
近年来,大模型的能力竞争,被简化成一串榜单数字。
近年来,大模型的能力竞争,被简化成一串榜单数字。
谁在通用评测中排名更高,谁的上下文窗口更长,谁的数学、代码、推理得分更漂亮……往往成为外界判断模型实力的直接依据。但随着大模型快速迭代,传统评测逐渐暴露出它的局限性:各类公开题库被反复用于训练和测试,「刷榜」现象愈演愈烈。一个模型在榜单上得分很高,并不必然意味着它在真实任务中稳定可用。
因此,行业开始重新思考一个问题——什么样的评测,才能更接近真实世界?
在此背景下,全国高考进入了评测者的视野。作为国内最具社会公信力的国家级考试,高考不仅命题严谨规范、阅卷体系成熟,而且有足够复杂的任务构成,覆盖数理逻辑、语言理解、创意表达等多维能力,更接近大模型在教育场景中真正要面对的复杂任务。最重要的是,高考试题每年全新命制,直接杜绝了「刷榜」可能。
2026 年高考季,多家媒体和第三方机构纷纷组织 AI 大模型参加高考盲评。国内外多款主流大模型被送进同一个考场,从语文作文到数学压轴题,从英语语法细节到全科综合能力,一场围绕大模型真实水平的「年度大考」就此展开。
多方测评之下,大模型进入更复杂的能力比拼
从多方测评来看,头部大模型整体能力都在提升,但不同模型之间的能力侧重也更加清晰。
在数学测评中,选择题、多选题等标准化基础题型已经很难拉开差距,真正形成区分度的,是解答题过程和压轴题中的复杂推理能力。
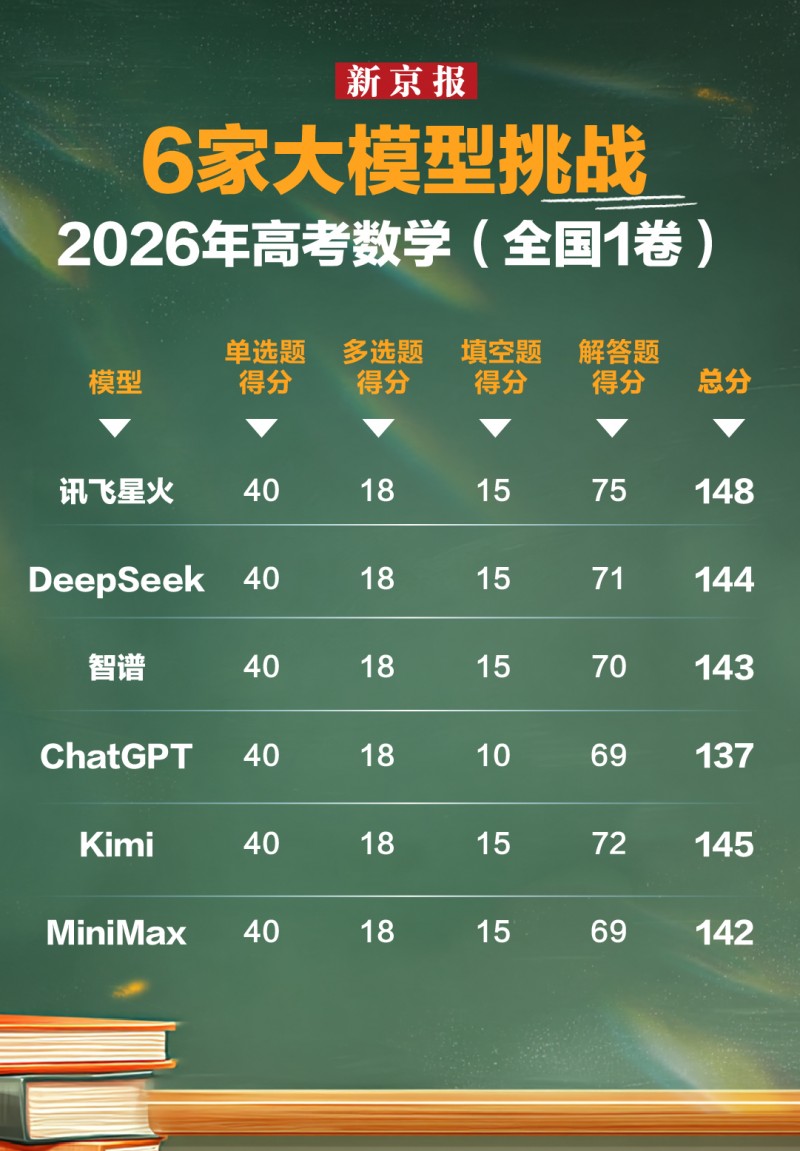
在新京报针对 2026 年新高考 I 卷数学卷的测评中,参与测试的包括讯飞星火、DeepSeek、智谱、ChatGPT、Kimi、MiniMax 等 6 款主流大模型。结果显示,讯飞星火以 148 分位列第一。专业老师给出的评价是,星火全程规范分与结果分完全一致,推理过程较为清晰,在几何题、数形结合和复杂题目拆解中表现稳定。
这恰恰说明,大模型的数学能力竞争,正在从结果导向跨入过程导向的阶段。有些模型虽然具备较强推理能力,但在长链条推导中出现步骤跳跃、关键推导缺失,甚至引入高中阶段不宜使用的高等数学方法。对真实高考阅卷来说,这些都会影响过程分。

▲6 款大模型数学总体得分情况,图源:新京报
语文作文的情况更为复杂。
如今,让大模型写出一篇结构完整、语言流畅的作文已经不难,难的是它是否真正理解题目要求,形成清晰立意、避免模板化表达的文章,是否能写出符合高考评价体系的思辨深度。
在南方产业智库组织的全国 I 卷作文测评中,千问、豆包、DeepSeek、讯飞星火等 9 款国内外主流大模型参与测试,专家按照高考作文标准逐一打分。结果显示,各模型普遍能够做到审题准确、结构完整,但也存在素材雷同、堆砌辞藻、论据泛化等问题。其中,讯飞星火平均得分 55.5 分,排名第一,专家评价其文风沉稳思辨,成长印记清晰,时代立意高远,逻辑闭环完整。

▲9 款大模型全国 I 卷作文得分情况,图源:南方产业智库
英语写作则提供了另一个观察角度。
英语应用文篇幅不长,但细节更多:要覆盖写作要点,要控制词数,要避免语法错误,还要符合高中英语应用文表达规范。在观察者网的英语新课标 I 卷应用文盲评中,不少模型出现了词性转换的错误,甚至有模型连犯两次同一错误。最终,GPT-5.5、讯飞星火与通义千问并列拿到第一梯队成绩。

▲大模型中英高考作文得分情况,图源:观察者网
如果说语文考察的是语义理解、价值判断和表达组织,数学考察的是复杂推理、过程规范和问题拆解,英语考察的是语言生成、跨语种能力和语用控制,那么全科测评则进一步放大了模型的综合稳定性。
在羊城晚报面向广东高考模式的全科测评中,8 款国内外主流大模型参加语文、数学、英语以及选考科目的综合测试。结果显示,头部模型之间的差距已经不再局限于单点知识问答,而是进入多学科综合能力的比拼。
评测结果显示,讯飞星火物理类总分 708 分,与 Claude 并列第一;历史类总分 700 分,是唯一进入广东屏蔽生行列的模型。专家指出,星火的表现并非来自单一科目的明显拉动,而是得益于其在语言理解、数理推理和综合分析等任务中的相对均衡表现。

▲8 款大模型 2026 年高考全科成绩情况,图源:羊城晚报
几轮覆盖语文、数学、英语乃至全科的第三方测评,进一步说明了高考作为大模型评测样本的价值。它所检验的,并不只是模型能否算出答案、写出文章,或者完成一道标准题,而是能否在具体评分规则下稳定输出高质量结果。
稳定表现背后,是技术优势与教育基因的「化学反应」
高考只是能力出口,背后对应的是大模型底层能力的综合调度。讯飞星火在高考中的出色表现绝非偶然,而是通用人工智能技术与垂直教育场景深度融合后产生的「化学反应」。
今年 2 月,科大讯飞发布基于全国产算力训练的星火 X2 大模型,和上一代 X1.5 相比,重点升级了多语言综合能力、数学推理、智能体等能力。
但仅有通用能力并不够。
教育场景有非常明确的规则。什么样的作文算扣题,什么样的解题步骤会被扣分,什么样的英语表达更符合应用文要求……这些并不是通用语料能解决的问题,它们来自真实课堂,来自一线教师和阅卷体系中长期沉淀下来的专业判断。
科大讯飞 20 余年长期深耕教育场景,从课堂教学、作业练习、考试测评,到智能批改、个性化学习、学习机等具体应用环节,积累了覆盖全国 6 万所中小学、超 1.6 亿师生的大量真实教育反馈。对大模型而言,这些反馈是帮助模型理解中国教育体系、考试逻辑和学生学习过程的重要来源。
因此,星火的高考表现更像是通用大模型能力与教育行业经验结合后的外化结果。它不只是会回答问题,而是更懂教育场景中的问题应该如何被回答。
这种结合,也与国家推动人工智能赋能教育的方向高度一致。
近年来,AI 与教育的融合已经从技术展示进入真实落地阶段。2025 年 8 月,国务院印发《关于深入实施「人工智能+」行动的意见》,明确提出「把人工智能融入教育教学全要素、全过程」,推动「育人从知识传授为重向能力提升为本转变」。2026 年 4 月,教育部等五部门联合发布《「人工智能+教育」行动计划》,进一步提出推动智能技术与教育全要素融合、全过程贯通、全场景覆盖,标志着「AI+教育」的加速变革。
在这样的背景下,讯飞多年深耕教育的价值也更加清晰。教育不是一个可以靠短期流量和单次跑分打穿的行业,它有稳定但复杂的评价体系,有分层分类的学生需求。真正能在教育场景中发挥作用的模型,不仅要有强大的通用能力,还要理解教育的专业逻辑。
从这个角度看,高考测评中的高分确实提供了一个观察窗口:当大模型进入真实考试任务,它能否理解题目、遵守规则,能否符合阅卷标准跨学科稳定发挥。这些能力,恰恰是教育大模型从「能用」走向「好用」的关键。
从算力竞赛到场景理解,大模型竞争进入深水区
大模型参加高考,并不意味着 AI 可以替代学生,也不意味着考试本身将被技术轻易改写。
但大模型高考测评的意义在于,它让我们看到了行业竞争正在发生变化。过去,大模型比拼的重点常常是参数、算力和通用榜单;而现在,真正拉开差距的,是模型能否进入真实场景,理解真实规则,并对齐真实需求。
高考正是这样一个窗口。它既有标准答案,也有开放表达;既要求统一规则,也强调个体思考。这样的复杂性,恰好成为检验大模型是否已经开始理解真实世界的专业标准。
今年上海高考作文题中有这样一句话:「科技改造世界时,也改造着我们的想象。」
技术进入教育,不应该只是为了制造更高的分数,更重要的是帮助教师更有效地教学,帮助学生更清楚地理解自己,帮助优质教育资源抵达更多地方,也帮助每一个人在技术时代更好地想象自己的未来。
通往 AGI 的道路上,不仅需要仰望星空的技术理想,更需要脚踏实地、深耕场景的敬畏之心。讯飞星火的价值,在于为教育公平和个性化学习提供强大的技术支撑,它可以成为每一位学生身边的 AI 助教,全天候陪伴、精准答疑、因材施教。这正是技术服务于人的终极价值所在。
来源:互联网


