
当前,人工智能正以前所未有的速度渗透千行百业,推动 AI 算力需求呈指数级增长,算力已成为人工智能产业发展的核心竞争力。
当前,人工智能正以前所未有的速度渗透千行百业,推动 AI 算力需求呈指数级增长,算力已成为人工智能产业发展的核心竞争力。
在此背景下,昇腾推出新一代 AI 芯片 Ascend 950PR 与 Ascend 950DT。两款芯片在继承上一代优秀能力的基础上,围绕计算、通信等关键维度实现多项技术突破,涵盖 NDDMA、CV 融合、SIMT、UB、CCU 等创新特性,大幅提升了大模型训练与推理、推荐、多模态等核心业务场景的性能与竞争力。
本文将从芯片架构、计算与通信规格、关键新特性等维度,对 Ascend 950PR 和 Ascend 950DT 进行全面、深入、细致的解析。
一、Ascend 950硬件架构
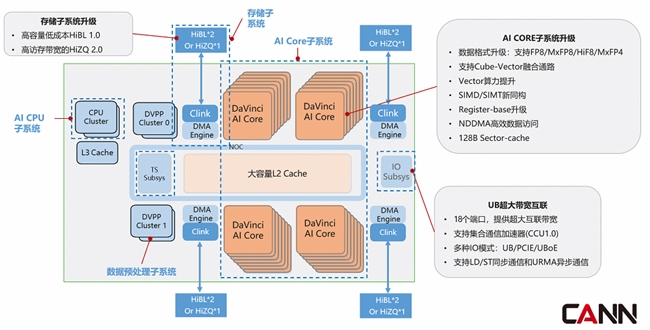
Ascend 950 代际发布了两款芯片。一款是 Ascend 950PR,一款是 Ascend 950DT。Ascend 950PR 中的 PR,代表 Prefill&Recommendation,此芯片面向的是 Prefill 和推荐场景,特点是以较低的成本,获得更高的性价比;Ascend 950DT 中的 DT,代表 Decode&Training,此芯片面向的是 Decode 和训练场景,特点是更高的访存带宽,获取更高的性能。两款芯片是基于 Ascend 950 Die,与不同的 Memory 进行合封构成。
Ascend 950PR&Ascend 950DT 与前一代昇腾芯片相比,在以下几个方面进行了提升:
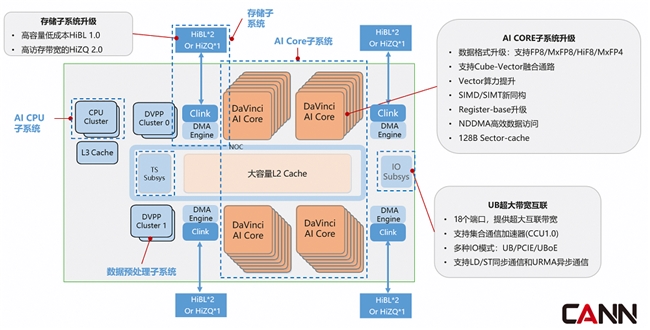
● AICORE 子系统,采用华为自研的第三代 Davinci 架构,在前代架构基础上,针对当前 Transformer 为核心,同时兼顾推荐、多模态等多种算法趋势,从低精度算力、计算效率、易用性等方面进行了全面的提升。
■ 新增支持业界标准 FP8/MXFP8/MXFP4 等低数值精度数据格式,并特别支持自研的 HiF8,提升训练效率和推理吞吐
■ 增加 Cube-Vector 融合通路,极大的提升了 Cube-Vector 融合算子性能
■ 大幅度提升了 Vector 算力,Cube:Vector 算力配比达到 8:1
■ 采用创新的 SIMD/SIMT 新同构设计,提升编程易用性
■ 支持 128 字节的 Sector-Cache,提升离散且不连续的内存访问性能
■ 支持 NDDMA 高效数据访问,提升内存访问效率
● 存储子系统:950 芯片的存储子系统,支持两种类型的 Memory,包括高容量、低成本的 HiBL 1.0,以及高访存带宽的 HiZQ 2.0。采用统一的接口实现不同 Memory 的对接。
● IO 子系统:950 芯片支持 UB 灵衢互联,可以实现超节点系统的超高带宽、超低时延、超大规模组网需求。
■ 整芯片支持 18 个 400Gbps 端口,支持超大互联带宽
■ 支持硬化的集合通信加速单元,降低通信对访问带宽的占用,提升通信性能,并降低通信对计算的影响
■ 创新的支持 UB&UBOE 互联协议;同时兼容 PCIE 互联
■ 同时支持 Load/Store 的同步通信语义,和 URMA 异步消息通信语义
二、核的微架构改进,提升计算性能和开发易用性
在人工智能技术飞速发展的今天,大型语言模型(LLM)、多模态 AI 等复杂任务对计算硬件的性能需求持续提升。昇腾 AI 芯片最新发布的第三代 DaVinciCore 架构,通过硬件能力升级与软件协同优化,在计算性能、开发者体验和能效比方面实现了持续提升。
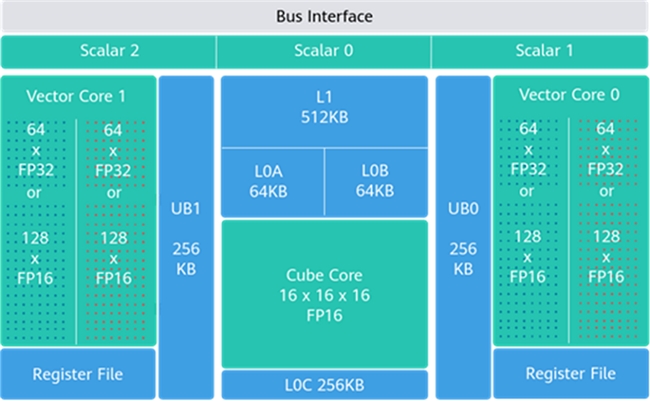
1、算力效率革命:低精度计算+混合架构,性能提升 4 倍
传统的 AI 芯片往往受限于计算精度与数据搬运效率,而第三代 DaVinciCore 通过全栈数值格式创新和访存效率优化,彻底释放低精度计算的潜力。
● HiF8/FP8/MXFP8/MXFP4:支持 MXFP8/4 和 FP8 基础上,全新设计了动态位宽浮点格式 HiF8,在保证精度的同时大幅降低存储与带宽需求。以 HiF8 为例,其采用变长前缀编码+原码阶码优化,动态范围接近 FP16(-22∼15),但计算效率提升 2~4 倍,尤其适合 LLM 训练与推理。
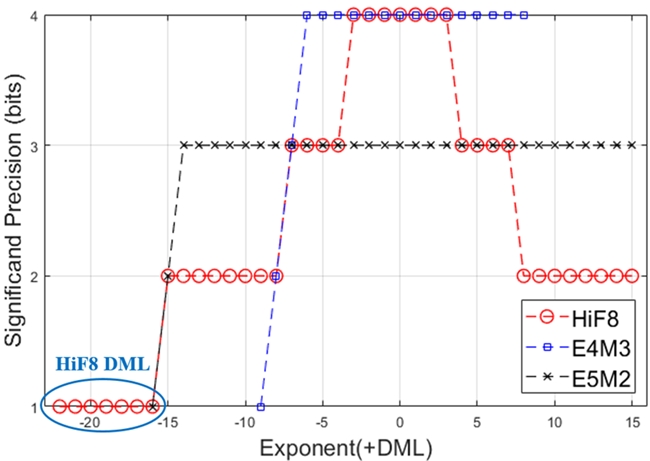
HiF8 阶码分布图(锥形精度图)
● 张量-向量协同计算:单核内 Cube 核(张量计算)峰值算力与上一代持平,Vector 核(向量计算)FP16/FP32 性能翻倍,二者通过高速直连通道实现数据无缝流转,彻底解决传统 AI 芯片在混合计算(如 FA)任务中的瓶颈问题。
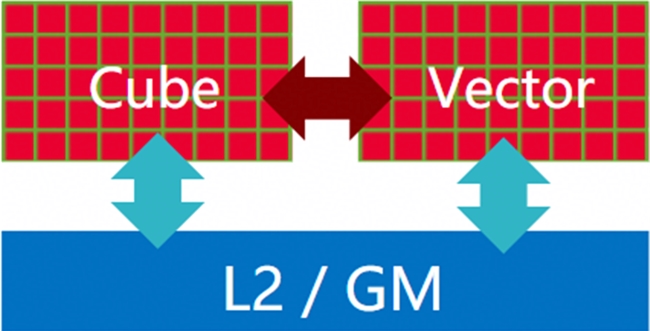
增加核内 CV 直连高速通路示意图
● 优化核内 buffer size:L0C buffer Size 增加到 256KB,支持 Cube 计算 256*256 tile 块,算力密度比提升 20%,提升 Mac 效率达成 90% 场景的覆盖面,分布式 localbuffer 降低多流水并发对 local buffer 的访问竞争,提升流水并发的效率,两者共同提升算子性能的天花板。
2、访存效率持续优化:提升算子非对齐小 Burst 场景的泛化性能
● L2 Cache 支持 128B Sector,访存颗粒度相比上一代的 512B->128B,小包场景 4x 带宽效率;数据访问 GM 支持多种 L2 Control Hint,通过指令控制 L2 Cache 的缓存策略,优化 Cache 使用效率,提升网络 E2E 的 Cache hit 率。
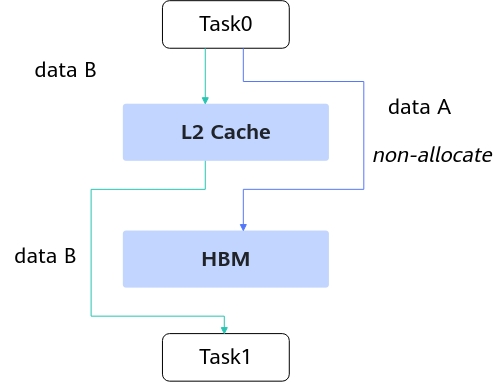
non-allocate(L2 hint) 典型使能场景示意图
● ND2NZ 支持 Advance 模式,对 Stride 在不大于 256B 的场景都支持并包处理。
3、核微架构持续演进:带来多项「黑科技」级编程优化
● SIMD/SIMT 混合编程:开发者可自由选择并行模式——规则计算用 SIMD 双发指令榨干硬件性能,复杂逻辑(如多条件分支)/小包搬运等场景切至 SIMT 线程级并行,代码可读性与执行效率兼得。
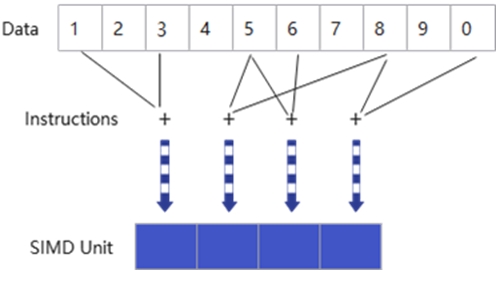
SIMT 离散访问示意图
● NDDMA 指令:传统数据搬移需硬件地址计算+访存合并,如今只需一行 NDDMA 指令 (transpose,stride,broadcast,slice),硬件自动完成格式转换、对齐、分块,效率提升 50% 以上。
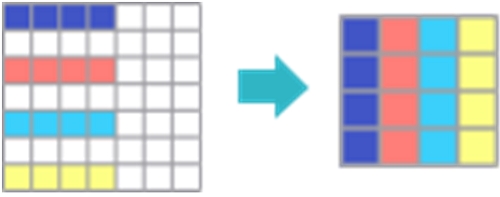
NDDMA 指令能力示意图
● 极简同步机制:BufferID 模型取代繁琐的 set/wait 配对,消除分支逻辑,让多核协作代码更直观、更健壮。
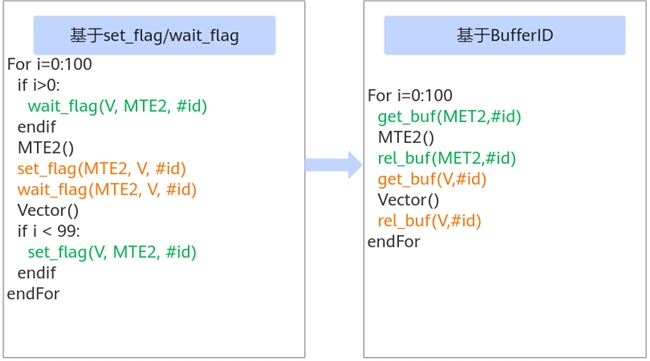
新同步机制代码示例
三、基于灵衢互联,构建大规模超节点集群
Ascend 950 提供比前代芯片更高的连算比,搭载先进的灵衢互联技术构建 Ascend 950 超节点集群,能够大幅降低通信时延、提升算力效率,有效破解大规模 AI 集群的通信瓶颈。
灵衢互联 UB(UnifiedBus,简称 UB),是面向新一代智算集群打造的新型互联协议,是破解算力瓶颈、共建开放生态的重要布局。灵衢互联以「协议归一、平等协同、全局池化」为核心,打破了传统互联的层级壁垒,让 CPU、NPU、存储等异构组件实现无主从直接通信,并大幅降低通信时延、提升带宽利用率。华为已开放灵衢 2.0 完整技术规范,推动产业协同创新。未来灵衢将持续演进,突破更大规模组网能力,携手产业伙伴构建自主可控、高效可靠的算力底座。
灵衢互联提供分层的协议栈结构,从下到上由物理层、数据链路层、网络层、传输层、事务层、功能层以及 UMMU、UBFM(UB Fabric Manager)组成,如下图所示。其中,Entity 为功能实体,是全局通信的基本单元;URMA(Unified Remote Memory Access)为统一远程内存访问。
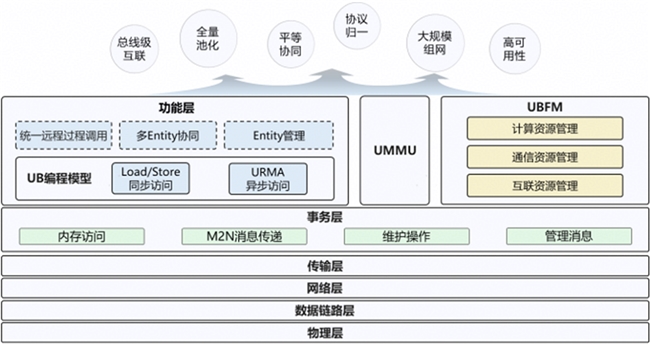
灵衢协议栈
Ascend 950 围绕超节点架构持续创新,将多台物理机器深度互联,重新定义了高效、稳定、可扩展的大规模有效算力新范式,并打造全系列超节点产品。
Ascend 950 以灵衢互联为基础构建的超节点架构,在面向人工智能计算的多个核心业务场景,如大模型预训练、中心推理、后训练与强化学习、多模态内容等业务领域均可提供领先的系统能力,带来计算业务性能和资源利用率提升。
四、总结
Ascend 950PR 和 Ascend 950DT 芯片在继承前代 DaVinci 架构核心设计理念的基础上,围绕计算、存储、互联三大维度实现了系统性升级,通过计算效能革新、访存效率深挖与互联架构突破三者的协同优化,面向大模型预训练、中心推理、后训练与强化学习、推荐系统、多模态内容生成等核心 AI 业务场景,提供了系统的软硬协同能力,为 AI 产业的算力需求增长提供了强有力的算力底座支撑。
来源:互联网


