
近日,小米推出的 MiMo Flash V2 模型备受开源社区关注。该模型采用 MoE 架构设计,拥有 3090 亿总参数量与 150 亿活跃参数量,更是国内首款融合 SWA + Sink(滑动窗口注意力 + 锚定令牌)与 Full Attention(全局注意力)混合注意力机制的模型,在推理效率优化上展现出显著优势。
近日,小米推出的 MiMo Flash V2 模型备受开源社区关注。该模型采用 MoE 架构设计,拥有 3090 亿总参数量与 150 亿活跃参数量,更是国内首款融合 SWA + Sink(滑动窗口注意力 + 锚定令牌)与 Full Attention(全局注意力)混合注意力机制的模型,在推理效率优化上展现出显著优势。
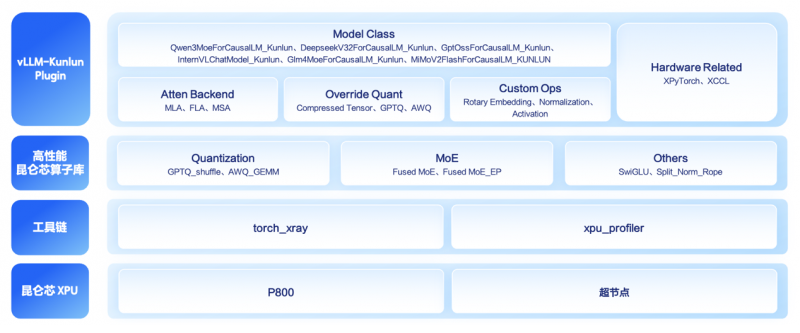
不过,这款模型独特的混合注意力架构,也给 GPU、XPU 等底层适配工作带来了不小的挑战。百度百舸和昆仑芯的技术团队基于 vLLM-Kunlun Plugin,仅用 2 天时间便在 vLLM 环境中实现了 MiMo Flash V2 在昆仑芯 P800 XPU 上的全流程适配。
这一成果不仅展现了高效的技术适配能力,更直观体现了 vLLM-Kunlun Plugin 的核心价值——帮助业务团队无需对 vLLM 核心代码进行侵入式二次开发,就能让最新大模型在昆仑芯 XPU 上快速落地,真正实现即插即用。
1. 适配架构新特性:破解非对称 KV 维度不匹配难题
MiMo Flash V2 有别于其他模型的关键特征,是其采用的 SWA+Sink 与 Full Attention 混合注意力机制,而这一设计也直接带来了适配层面的核心难题。在该模型的 SWA + Sink 机制中,Key 头数量为 192 个、Value 头数量为 128 个,这种非对称结构与传统模型常见的对称设计不同,导致模型无法直接在硬件上部署。
由于这种设计的特殊性,vLLM 社区尚未提供成熟的适配支持:MiMo Flash V2 的部署能力仅存在于 vLLM 的开发分支中,社区暂无稳定发版分支,最新的 v0.13.0 正式版本也未包含相关适配能力,这给适配工作增加了一定难度。
为在 vLLM 环境中实现 MiMo Flash V2 在昆仑芯 P800 XPU 的顺利跑通,百度百舸和昆仑芯的技术团队参考了社区的 MiMo Flash V2 PR,在 vLLM-Kunlun Plugin 中完成了下述两个步骤,最终实现模型成功跑通:
•通过继承 vLLM v0.11.0 版本 Linear 模块中的 QKVParallelLinear 类,在 Plugin 中修改 QKVParallelLinear 核心逻辑,为 Key 权重与 Value 权重分别创建对应维度的张量,从根源上解决维度适配问题;
•借鉴社区最新模型组网思路,在 vLLM v0.11.0 版本不支持该模型的情况下,在 Plugin 中自定义实现了 MiMoV2FlashForCausalLM_KUNLUN 模型类,实现了上层模型与底层 P800 算子的对接。
这两处修改仅涉及少量模型接口调整及权重加载逻辑优化,充分验证了 vLLM-Kunlun Plugin 开发模式的简洁性与高扩展性。需要说明的是,此次对 QKVParallelLinear 类的修改属于特殊情况,仅因 vLLM 暂无正式版本支持 MiMo Flash V2 模型。对于大多数已纳入 vLLM 正式版本的模型,适配时仅需对对应模型类进行微调即可部署。目前,vLLM-Kunlun 社区已推动无组网修改的模型支持工作,Llama2/3 系列及 Qwen2 系列模型已实现对社区组网的零改动适配。
2. 优化性能精度:实现无损高效推理
在开展上文提及的框架适配工作的同时,研发团队同步启动了 MiMo 模型的算子优化,让模型不仅能跑,更能精准高效地跑。
针对 MiMo Flash V2 复杂的混合注意力机制,团队依托昆仑芯完善的软件栈,在 2 天内基于已有的 SWA attention 算子,增量开发了 Sink 功能,并将其整合到高性能算子库中。开发者仅需升级至最新版本的算子库,即可在昆仑芯 P800 上高性能运行 MiMo 模型。
完成主要开发流程后,团队还针对该模型进行了进一步的分析与优化,确保精度和性能达到硬件最优水平。在此环节中,团队借助 vLLM-Kunlun Plugin 配套的 torch_xray 精度对齐工具与 xpu_profiler 性能分析工具,快速推进优化工作:
•通过 torch_xray 自动比对 GPU 与昆仑芯 P800 的逐层输出结果,精准定位并优化数值偏差;
•利用 xpu_profiler 生成清晰的算子调用时序图,精准识别性能瓶颈与计算气泡。
最终,MiMo Flash V2 在 P800 上的推理效果与 GPU 平台保持一致,实现无损适配与高效运行。开发者也可借助这两套工具,找到运行在 P800 上的其他模型的潜在性能瓶颈,并通过 GitHub Issue 或官方 Slack 社区向我们反馈相关问题。
3. 提前布局:MTP ready
百度百舸和昆仑芯的技术团队已提前完成 MTP(Multi-Token Prediction,多 token 预测)功能的底层逻辑铺设。本次开发的 SWA + Sink 算子在 decode 阶段支持的 query 长度最大可达 32,远超过 MiMo Flash V2 模型 MTP 功能(N=3)所需的 4。一旦开源社区修复该模型 MTP 相关问题,昆仑芯 P800 可立即启用该功能的加速模式。
4. 结语:开源生态中的昆仑适配速度
从适配架构新特性实现模型跑通,到深度优化完成性能精度双提升,仅用 2 天时间便让 MiMo Flash V2 在 vLLM 环境中于昆仑芯 P800 稳定高效运行,vLLM-Kunlun Plugin 用实际成果证明了国产芯片与开源生态协同适配的高效性。
作为全面开源的插件项目,vLLM-Kunlun Plugin 基于 vLLM 社区 RFC #11162 硬件插件标准开发,实现了 vLLM 社区版与昆仑芯 XPU 后端的完全解耦。目前插件已覆盖超过 20+ 主流及多模态模型系列,涵盖 Qwen 系列、DeepSeek 系列、Llama 系列等,无论是社区开源模型还是自研私有模型,均可通过该插件快速完成部署与优化,大幅降低迁移成本。
未来,插件将持续深耕大模型推理优化领域,不断丰富模型支持矩阵,为更多优秀模型提供高效、便捷的国产算力部署方案,同时通过开放协作机制,欢迎开发者深度参与上游贡献,共同推动国产 AI 基础设施的繁荣发展。
来源:互联网


