

目前,有着「集成电路设计领域奥林匹克大会」之称的 IEEE 国际固态电路会议 ISSCC 2022 正在火热进行,临时变为全面线上会议的形式并没有减少学者与工程师们对它的密切关注。
目前,有着「集成电路设计领域奥林匹克大会」之称的 IEEE 国际固态电路会议 ISSCC 2022 正在火热进行,临时变为全面线上会议的形式并没有减少学者与工程师们对它的密切关注。ISSCC 是世界学术界和企业界公认的集成电路设计领域最高级别会议。在此次会议上,苹芯科技发表题为「A 1.041Mb/mm2 27.38TOPS/W Signed-INT8 Dynamic Logic Based ADC-Less SRAM Compute-In-Memory Macro in 28nm with Reconfigurable Bitwise Operation for AI and Embedded Applications」的论文,文章提出高效的无 ADC 架构 SRAM 存内计算加速引擎,基于 28nm 工艺搭建模块可以达到 27.38TOPS/W 的高能效比,同时实现高达 1.041Mb/mm2 面效比,达到国际领先指标并实现技术突破。
存内计算技术作为 AI 芯片未来方向,无论在学术层面还是商业价值层面均有巨大优势。由于「存储墙」、「功耗墙」的打破,存内计算的研究可以从根本上解决冯诺依曼架构带来的时间功率等方面的损耗,因此从数量级角度提升相关计算效率、能效比等核心指标。其技术本身是一门非常复杂的、技术壁垒极高的设计方法学,属于需要多年经验积累、大量资源以及时间投入才能实现的尖端领域。谁拥有兼顾计算密度与存储密度的存内计算硬件架构,谁就拥有了打开高能效计算的金钥匙。因此,无论技术实现还是落地实施路线上,都存在着很大的难点和挑战。
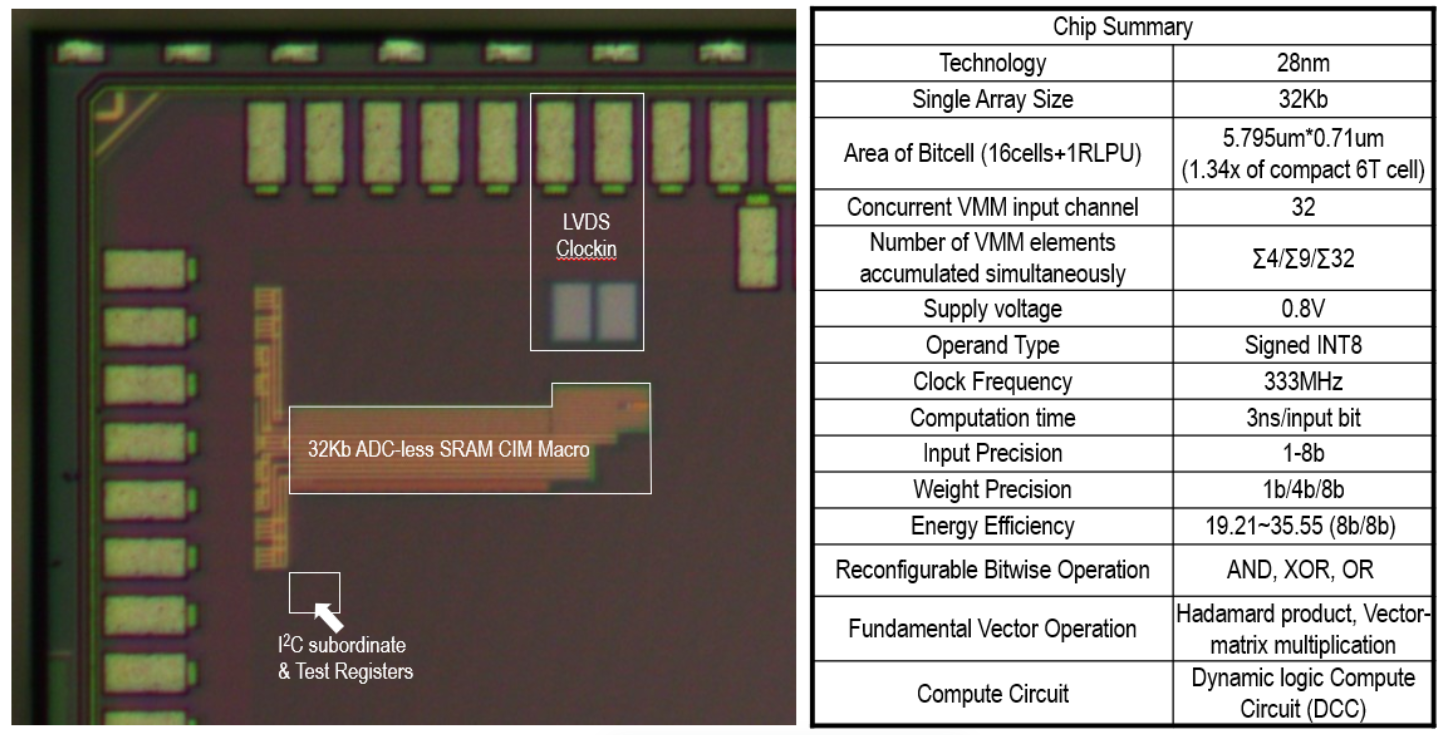
本次工作实现了 28nm 技术节点的 32Kb 无 ADC SRAM 存内计算加速单元,由动态逻辑计算电路(DCC)替代传统 ADC 或 CMOS 静态逻辑,实现高能效比与面效比。同时由可重构本地处理单元(RLPUs)实现 bitcell 数组逻辑运算,并拓展至向量矩阵相关计算(VHP/VMM), 在核心指标方面相较于传统架构具备数量级优势,为存内计算技术的实际产业化应用部署奠定坚实基础。
ISSCC(IEEE International Solid-State Circuits Conference,国际固态电路会议),是世界学术界和企业界公认的集成电路设计领域最高级别会议,被认为是集成电路设计领域的「奥林匹克大会」。世界上第一个 TTL 电路、世界上第一个 8 位微处理器、世界上第一个 1Gb 的 DRAM、世界上第一个 GHz 微处理器、世界上第一个多核处理器等众多集成电路历史上里程碑式的发明都在该会议上首次披露。自 1954 年以来,该会议已经成功举办 68 届。本次存内计算论文入选意味着此项核心技术已达到国际领先水平,得到了学术界的顶会认可,代表了芯片领域新的前进方向,在 AI 技术应用程度不断提升的今天,存内计算拥有巨大的发展前景。
北京苹芯科技专注于利用新兴的存内计算技术对现有的计算进行加速,目标是将计算和数据存储相融合,从体系结构上突破传统芯片架构固有的局限性,从而低成本地实现一个高性能的计算引擎。从根本上突破传统冯诺依曼体系下「存储墙」的限制,打造一个高性能,大带宽,低延时的通用计算平台, 为客户提供差异化解决方案。截至目前,公司已开发实现了多款基于 SRAM 的存内计算加速单元,并持续研发基于新型存储器的存内计算相关技术,致力于为人工智能行业提供低成本、高效率、低能耗、高性能的芯片及解决方案。此方向技术可广泛应用于众多人工智能行业领域,包括但不限于行业整合管理、智慧城市、工业物联网、智慧医疗、智慧安防、智能交通及无人机等领域。
来源:互联网


