
近日,QQ 音乐在沉浸式音频自动化生成领域取得了突破性进展。
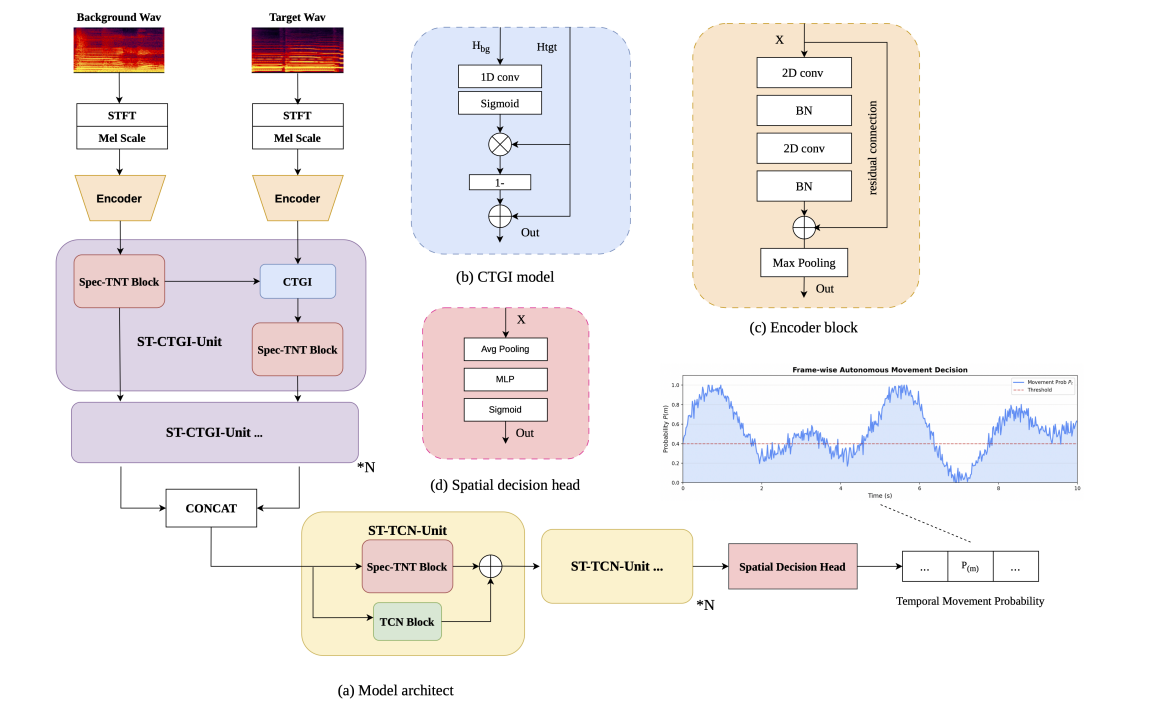
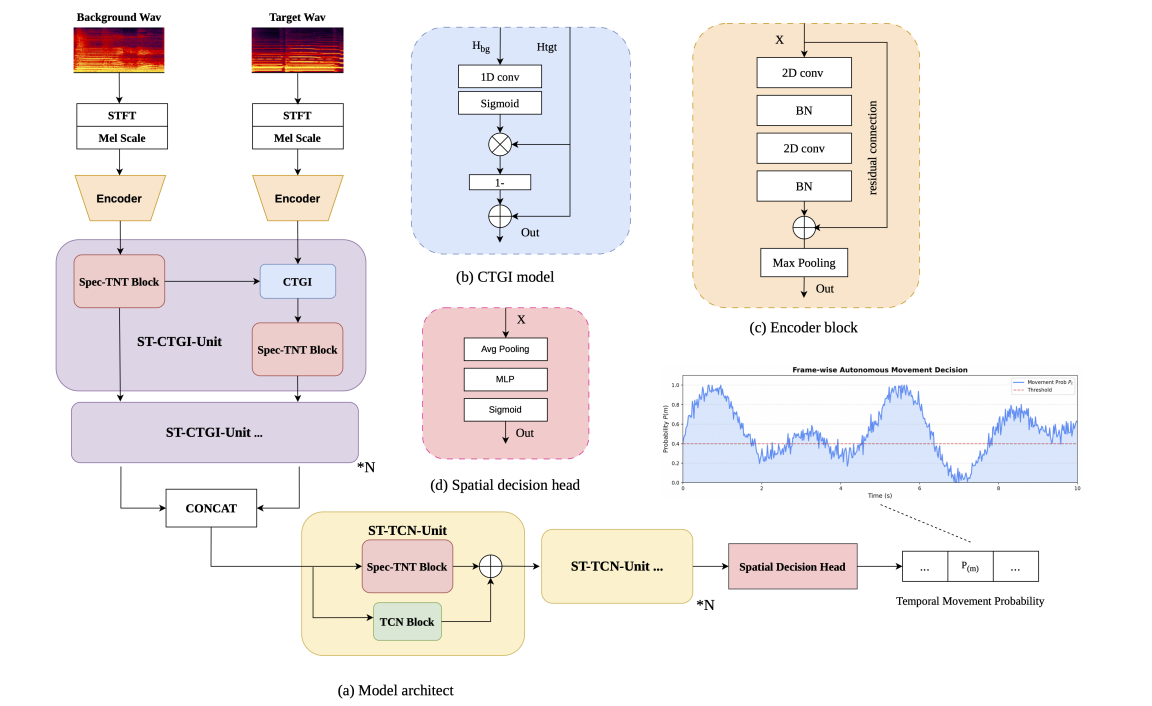
近日,QQ 音乐在沉浸式音频自动化生成领域取得了突破性进展——其自研的业界首个基于深度学习、具备「音乐意图」的空间混音检测模型 SEND(Spatial Event Neural Detector) 论文,正式被第 29 届国际数字音频效果会议(DAFx26)接收录用。
SEND 模型获得学术权威认可,标志着 QQ 音乐在「AI 赋能沉浸式音频」的工业化探索上,已稳步走在全球前列。目前,SEND 核心技术已全面落地应用于 QQ 音乐臻品全景声 3.0,实现从音源内容到用户收听的全链路技术赋能。
首个读懂「音乐意图」的 AI 空间混音模型 媲美专业混音师
随着沉浸式音频技术的普及,听众对声音的期待跨越了左右声道。而真正的「沉浸感」,不仅在于声音「从哪里来」,更在于它「如何运动」。目前,行业内制作高质量的「空间动效」门槛极高,现有智能混音工具只能「摆开声音」,混音师需在高造价的全景声监听环境中手动「绘制」声音轨迹。
为了解决传统工具「缺乏乐感」的痛点,QQ 音乐 SEND 模型通过「音乐空间事件检测」,让机器精准预测出声音该在何时开始移动、何时停止。
不仅如此,QQ 音乐还对 SEND 模型进行了严苛的客观测试与主观盲听。在客观测试上,SEND 模型能精准卡点,在此基础上的音轨运动不是「盲目乱动」,而是紧跟着音乐的「起承转合」,在音乐情绪爆发点「煽情」。在主观评价上,QQ 音乐甄选 20 位经验丰富的混音工程师和音乐人,通过「金耳朵」双盲听音测试,有效避免音乐的突兀感与眩晕感,真正达到媲美专业混音师的级别。
全链路赋能臻品全景声 3.0 推动智能音频技术进化
目前,QQ 音乐将 SEND 模型核心技术全面应用于臻品全景声 3.0,完成从音源内容到用户收听的全链路技术革新,助推音娱产业升级。
2025 年 12 月,QQ 音乐 20.0 版本推出了臻品全景声 3.0,充分拓展声场的宽度与深度。今年 3 月,在 2026 中国国际音频产业大会上,腾讯音乐与头部整车品牌合作,首次公开演示了臻品全景声 3.0 在智能座舱中的应用效果,以包裹式声场效果让汽车座舱变身「移动音乐厅」。今年 6 月,腾讯音乐娱乐集团(TME)与 UWA 世界超高清视频产业联盟达成合作,将菁彩声 Audio Vivid 技术上线至鸿蒙版 QQ 音乐,以臻品全景声 3.0 精准还原细腻声场,打造沉浸式听歌体验。
通过持续应用落地,采用 SEND 模型核心技术的臻品全景声 3.0,得到了用户的高度认可。用户盲测数据显示,臻品全景声 3.0 在音质纯净度、乐器定位清晰度,以及声音对象动态移动艺术效果上,实现了对上一代版本的全面超越。而对于音娱行业而言,SEND 赋予平台工业化空间音频量产能力,有助于流媒体跨越「产能鸿沟」,抢占未来体验高地。
作为国内领先的音乐流媒体平台,QQ 音乐致力于音频技术创新突破,持续提升用户音娱体验。SEND 模型的诞生及在臻品全景声 3.0 的落地,标志着 QQ 音乐智能音频技术正从单纯的「声学修正工具」进化为「懂艺术的创作伙伴」。未来,QQ 音乐将继续深耕沉浸式音频底层算法,让听众真切感受三维空间跳动的音乐灵魂。
来源:互联网


