

当前,人工智能作为培育新质生产力的核心引擎,已上升为国家战略层面。
当前,人工智能作为培育新质生产力的核心引擎,已上升为国家战略层面。国务院《关于深入实施「人工智能+」行动的意见》明确提出,要加快 AI 核心技术自主创新、降低产业落地门槛、构建开放共享的国产 AI 生态,推动人工智能与千行百业深度融合。
在这一战略背景下,网易有道正式推出「子曰 4.0」大模型体系 TTS 语音合成引擎——Confucius4-TTS,并已面向全球用户开放。近日,该引擎凭借全球首个不依赖参考文本即可实现 14 语种无口音跨语种语音克隆的开创性突破引发行业高度关注,为数字人、跨境传播、智能教育等产业提供国产化、低成本语音克隆功能。
重磅开源发布,完整模型权重本地可部署
Confucius4-TTS 采用 1.3B 参数高性能语音模型,开放行业领先的零样本语音克隆、跨语种无痕音色迁移、情感复刻能力,采用宽松友好的 Apache 开源协议,面向全球创作者、开发者开放完整模型权重与配套工具链。开发者可完整下载 54G 资源包,本地离线部署运行,配套开源龙虾智能体工具链,商用无限制。

三大技术突破,重新定义开源 TTS 天花板
突破一:3 秒极速克隆,零样本即可复刻原声
Confucius4-TTS 实现了真正的零样本语音克隆能力。用户仅需 3 秒即可完成音频克隆,克隆音色与原声相似度超过 85%,克隆任务准确度高达 97%。相较于初代 EmotiVoice 仅支持训练集内音色的局限,Confucius4-TTS 实现了「无口语零样本复刻」的跨越式升级。
突破二:14 种语言跨语种互通,彻底告别「中式口音」
Confucius4-TTS 全面支持中、英、日、韩、德、法、西、印尼、意、泰、葡、俄、马来、越南语等 14 种语言的自然流利表达。其最大亮点在于解决了语音合成领域长期存在的跨语种口音痛点——用户上传中文音频,AI 即可用该音色流利说出日语、英语等外语,发音地道自然。技术博主 @XAMTO_AI 评价:「你拿中文声音去讲日语,听着就像地道的日本人在说话,彻底告别了『外国人在那儿硬凹』的尴尬。」
突破三:音频 Prompt 情感克隆,语调韵律精准迁移
区别于初代 EmotiVoice 仅支持「happy/sad/angry」等离散文本标签的粗放式情感控制,Confucius4-TTS 创新性地支持音频 Prompt 情感克隆迁移。系统可自动提取参考音频中的情感标签,精准复刻其语调、韵律,支持跨语种无损迁移——「只要生气地说一句话,合成出来的外语也是生气的语气。」
全栈技术架构升级,从「传统声码器」到「大模型驱动」
Confucius4-TTS 在底层架构上实现了全面革新。相较于初代 EmotiVoice 采用传统 HiFi-GAN 声码器和 Speaker ID 查表的方案,Confucius4-TTS 引入了 GPT 式语义大模型作为主干,搭配基于 SSL 预训练特征和 ECAPA-TDNN 的可学习说话人编码器,并采用 Flow Matching 流匹配生成框架实现高保真、高自然度的语音合成。
语音克隆方面,EmotiVoice 不支持克隆功能,而 Confucius4-TTS 不仅只需 3 秒音频即可完成克隆,而且无需参考文本。
社区反响热烈,开发者实测验证
自开源以来,Confucius4-TTS 迅速获得开发者社区的积极反馈。技术博主 @dsd2077 在实测使用日语人声的参考音频生成中文语音,表示虽无法 100% 复刻细微音色,但整体听感自然流畅,无生硬外语口音。
另一位技术博主 @XAMTO_AI 评价道:「这回是真开源——人家给的是真权重而不是只给 API,整整 54 个 G 直接让你下,还能本地跑。做口播配音数字人,省钱又好用。」
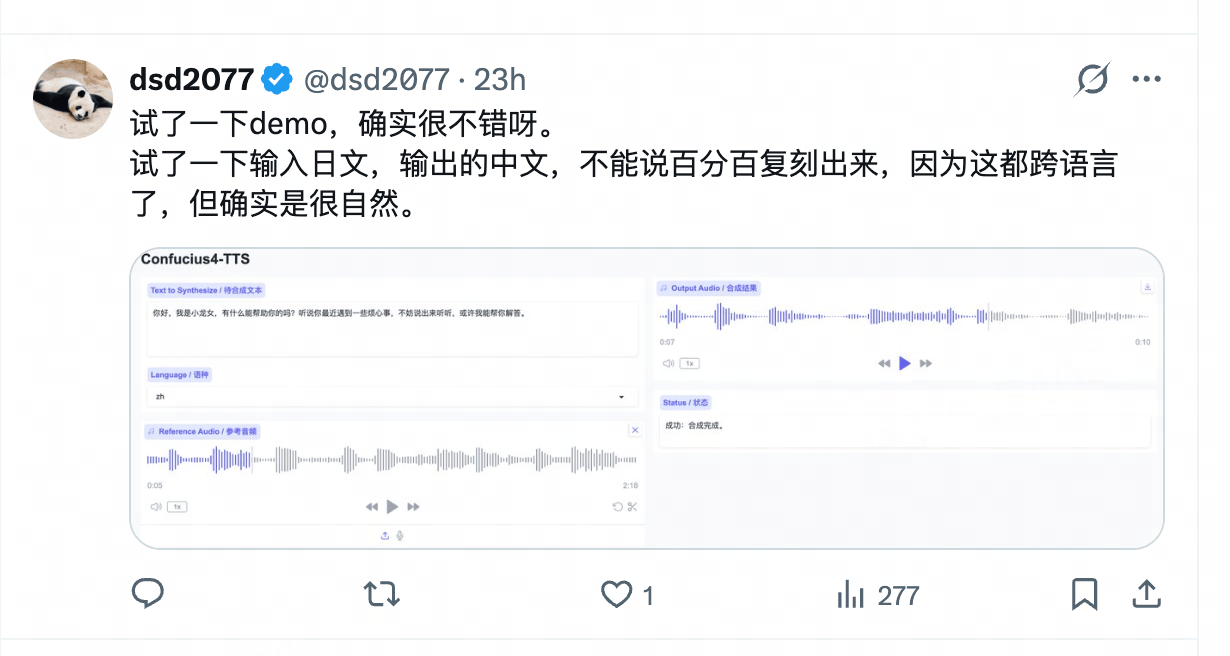
图 2 技术博主 @dsd2077 实测反馈
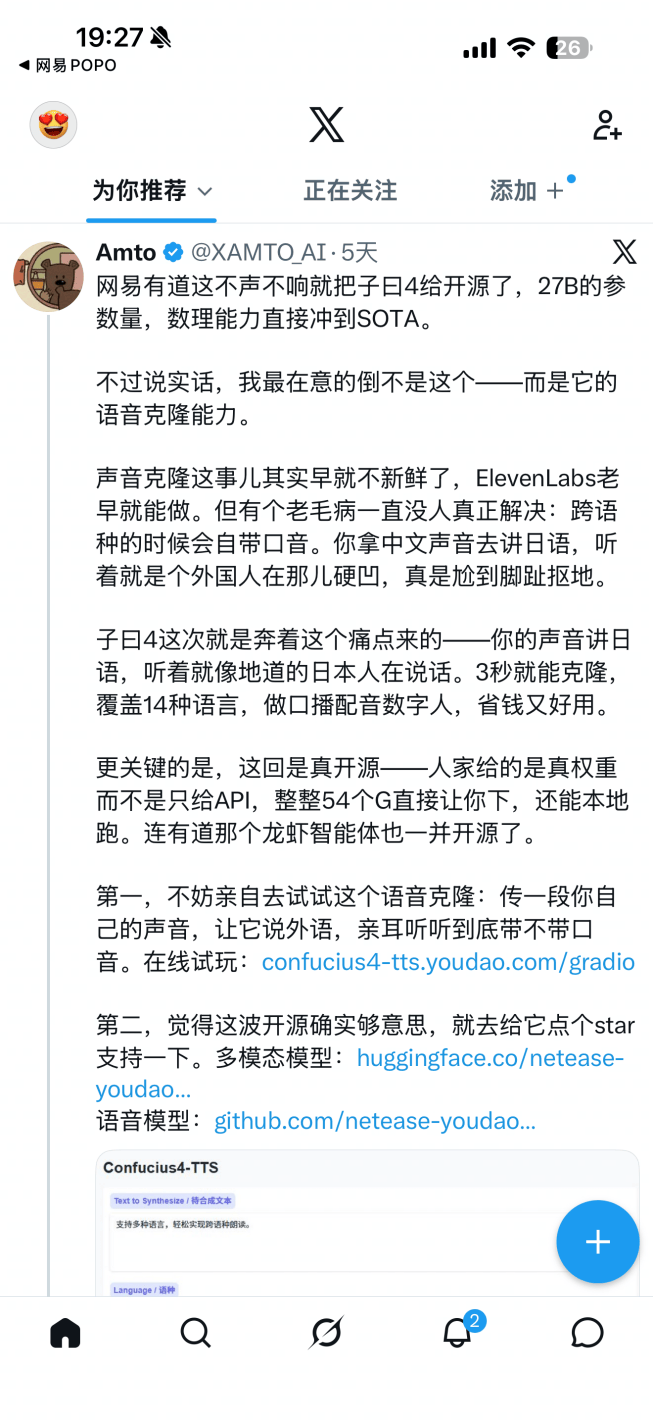
图 3 技术博主 @XAMTO_AI 实测反馈
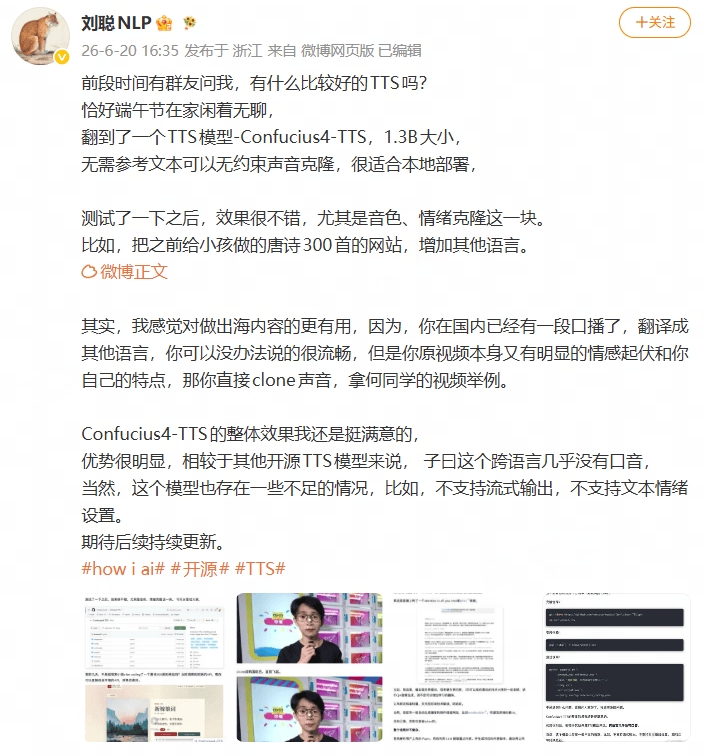
图 4 AI 博主刘聪 NLP 测评
Confucius4-TTS 的低门槛语音克隆和情感合成能力,可广泛应用于多语种内容创作、数字人配音、跨语言教学以及本地化运营等多种场景。
网易有道表示,希望通过全量开源 Confucius4-TTS,降低语音克隆和情感合成的门槛,期待社区探索出更多有趣、有用的新玩法。
来源:互联网


