
开放权重模型的较量,正从排行榜转向「能不能在真实 Agent 任务里干活」。
过去一年,开放权重模型之间比的东西其实挺单调:谁的 SWE-bench 高一点,谁的参数大一圈,谁就能上一条新闻。排行榜几乎成了这类发布的默认开场白。
但最近这段时间,节奏有点不一样。5 月 29 日,阶跃星辰发布并开源了 Step 3.7 Flash,值得留意的是官方介绍的第一句话——它没有先报分数,而是把这款模型定位成「面向生产级 Agent 的高效率 Flash 模型」。
根据官方介绍,它是围绕 Agent、Coding、Search 与多模态工作流进行系统优化的 Flash 模型。它真正想兼顾的,是速度、成本、长上下文、工具调用、联网搜索和多模态理解这一整套——在「又快、又便宜、又能稳定把复杂任务跑完」之间找平衡。
发布两天后,Step 3.7 Flash 登上 OpenRouter Trending 全球第二,成为近期开发者社区关注度较高的开源模型之一。同期国内也有厂商在开源模型上密集发力,方向同样落在真实工作流。
我真正想搞清楚的,不是 Step 3.7 Flash 强还是不强,而是一个更具体的变化:为什么这一波开源模型不再先亮分数,而是先讲「能不能插进开发者每天的任务里」?顺着这几个「不像跑分」的细节往下追,能看到的可能是开源模型从「发模型卡片」走向「进真实工作流」的那个交接点。
它们不先报分数,是因为分数能回答的问题,已经不是开发者最关心的那个了。
一旦模型从单轮问答进入真实 Agent 工作流,问题就变了。一个 Agent 任务往往要读长上下文、反复调用工具、跑多步操作、再根据结果决定下一步。调用次数会暴涨,延迟会被一段段叠加放大,token 消耗指数级上去。这时候单次回答多聪明,无法决定整个任务的成败;能不能用更低延迟、更低成本、更高吞吐把任务稳定跑完,才是真问题。阶跃这款Flash模型,押的正是这件事。
速度,在 Agent 里不是体验,是任务能不能用
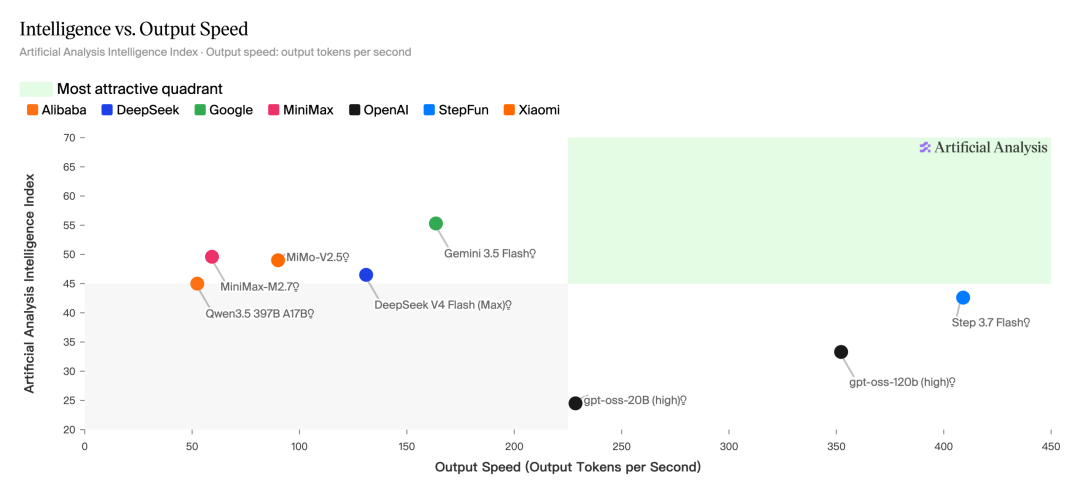
在传统单轮问答里,快一点只是体验更好。但在 Agent 场景里,一个真实任务可能要经历二三十步乃至更多的推理、工具调用和结果生成,单次只慢 1 秒,叠到几十步就变成用户等不起的成本。所以衡量价值的关键,是单位时间内能跑完多少有效任务。
根据Artificial Analysis 最新榜单,Step 3.7 Flash 以 409 tokens/s 的输出速度,在 Output Speed 一项位列主流模型前列。作为参照,资料显示,在没有特别推理加速的情况下,多数模型输出速度在 100 tokens/s 以下,主流大概在 30 tokens/s 这个量级。Step 3.7 Flash 是在支持多模态的前提下,把速度拉到了 400 tokens/s 这个量级。
把官方技术规格摊开看,这个速度不是凭空来的:它用的是稀疏 MoE 架构,总参数 196B、推理时激活只有 11B,上下文窗口 256K。激活参数压到 11B,推理的计算开销就下来了,速度才有可能拉高;256K 上下文意味着一个不算小的代码库加上多轮操作记录可以一次塞进模型视野,不用频繁截断。对一个要连续生成、反复调用的 Agent 来说,快和长不是锦上添花,是能不能用的前提。
性价比,决定一个 Agent 能不能被放大
速度决定任务跑多快,性价比决定这件事能不能被无限放大。真实 Agent 商用场景里,企业和开发者其实都对价格敏感——调用一旦高频又长链路,成本会被迅速放大。
在 Artificial Analysis 榜单的 Output Speed vs. Price 象限图里,Step 3.7 Flash 落进了「高输出速度 + 有竞争力价格」最具吸引力的象限。对需要持续运行、高频调用的 Agent 系统来说,只有速度、智能和成本一起兼顾,规模化部署才算得过来账。
多模态,不是看懂画面,是接管一段工作流
相比很多同样高效的Flash文本模型, Step 3.7 Flash 在多模态上的能力值得关注。它的多模态能力并未停留在识别和理解「图片」,而是「看懂一个真实环境,理解物理世界的任务操作逻辑,然后帮你把事办完」。
从阶跃官方放出的demo,也可见多模态对于Agent场景的价值:一个是让模型理解飞机驾驶舱环境、生成起飞操作说明——它要框选仪表按钮,还要理解什么时候推油门、何时收起落架这种操作因果,做的是「环境感知→状态理解→任务推理→操作指导」的闭环,而不只是输出一句 caption。另一个是读懂Blender 这类专业生产力软件的应用界面,对里面不同帖子做专业的设计分析,给出具体执行建议。
更贴近企业日常的是票据这一个:上传十几张不同场景、不同角度手机拍的发票,模型自动识别金额、税额、商户、消费场景,抽取报销最关键的字段,整理成表格并一键导出 Excel 或 CSV。它对应的是企业里大量重复、低效但高频的活——报销、财务录入、对账、审计整理。这类活的价值不在「读出内容」,而在端到端把「识别→理解→整理→导出」一次跑完,把非结构化信息变成能直接用的数据。
阶跃还演示了把模型扩成一支智能体集群:让 40 个不同身份的虚拟角色组成产品评测团,并行判断、再实时汇总它们对几个方向的偏好。
这些共同说明一件事:这款模型是被设计成在多模态工作流里干活,而不是在单张图上答题。
从「能下载」到「能干活」,中间卡在哪
开源模型这两年不缺。权重放出来、许可证给得大方、分数贴得漂亮,这套动作大家都熟。但开发者真要把一个开源模型接进自己的 Agent 流程,会卡在几个地方。
先说工具链对接。Claude Code、KiloCode、RooCode 这套 Agent 框架是过去一段时间才真正成型的,MCP、Skills 这类协议也是最近才被当成标准接口。一个模型不兼容这些,开发者就得自己写一堆胶水代码,迁移成本立刻把人劝退。Step 3.7 Flash 针对这几个主流框架和协议做了兼容优化,把适配开发者现有工作流,当成了产品设计的起点,而不是发完模型再补的兼容层。
还有部署这道门槛。Step 3.7 Flash 用 Apache-2.0 开源,GitHub 仓库给了权重、推理代码和部署资源,支持云端、数据中心和本地。本地跑需要高内存设备——官方列了 NVIDIA DGX Station、AMD Ryzen AI Max+ 395 系统,或至少 128GB 统一内存的 Mac Studio、Mac Pro。对企业而言是一条清晰路径:权重可控、可私有部署、许可证宽松,数据不必出本地。对一家要把 AI 接进内部研发、又对代码资产和数据安全敏感的公司来说,能私有部署、能审计、能自己掌版本,往往比榜单上多两分更要紧。
这正是这次发布对企业客户真正有价值的地方:它瞄准的不是「再多一个能下载的开源模型」,而是「一个能被接进生产流程的高效率 Agent 模型」,补的是从能下载到能干活这一段断层。
开发者挑模型时,真正会看哪几件事
如果这个趋势继续走,开发者挑模型的依据会和过去很不一样。
过去的习惯是先看排行榜,谁分数高先试谁。但当主流模型基准已经被刷到一个梯队,多两三分带来的实际差别在变小,分数高低越来越难直接换算成「我用着顺不顺」。真正会被反复掂量的,其实是这么几件事。
任务完成效率会被放到最前面:不是单次答得多漂亮,而是一个多步任务能不能稳定、快速地跑到底。单位成本也会被反复掂量,高频长链路调用下,缓存命中、吞吐和延迟摊出来的那笔总账,比标价更说明问题。工具链接入会变成另一个现实门槛,它兼不兼容我现在用的 Claude Code、KiloCode,调工具会不会中途掉链子。上下文和多模态也会进入评估:装不装得下我这个项目,能不能既读代码、又读界面、读票据。部署门槛和稳定性则决定它能不能真正进企业环境。
这些,排行榜一个都回答不了。
对企业采购来说,执行任务稳定性和开发者的真实调用就是验收标准:先在自己的研发流程里用真实任务压测工具调用和长任务完成率,再决定要不要纳进生产环境。
不必急着给「谁赢了」下结论。但有件事已经能看清:这一阵子,开源模型发布的第一句话,从「我考了多少分」变成了「我能接进你的活儿」。衡量一个开源模型的标准,正在从排行榜上的名次,换成它能不能被开发者默认接进每天的 Agent 工作流。 Step 3.7 Flash 押的,是在开发者和企业真实任务场景中,真正发挥商业价值。


