
本月 Gemini 3.5 模型的发布,Google 把「with action」放到了更靠前的位置。
本月 Gemini 3.5 模型的发布,Google 把「with action」放到了更靠前的位置。
首发的 Gemini-3.5-Flash 被放进 agents、coding 和 long-horizon tasks 的语境里,真实工作流中的速度、智能和成本平衡,开始成为同样重要的能力指标。
本周,阶跃星辰发布并开源了 Step 3.7 Flash。一家闭源模型、一家开源模型,完全不同的模型和商业策略,做出了相似的判断: Flash 模型正在从旗舰模型的轻量版,变成 Agent 时代的任务基座。
阶跃上一代的 flash 模型 Step 3.5 Flash 上线两天登顶 OpenRouter Trending 榜单,一个月拿下 OpenClaw 调用量全球第一。一个开源 Flash 模型能在全球开发者平台跑到如此高的调用量,说明市场正在用新的方式评价模型:单点能力峰值重要,长期调用中的速度、稳定性和成本同样重要。
原因很简单。Chatbot 的评价单位是一次回答,Agent 的评价单位是一条任务链路。当一个任务进入「观察、搜索、工具调用、执行、验证、修正」的循环,效率就会影响任务完成率,也会影响智能上限。
Agent 时代,效率就是智能的决定性因素。
Founder Park 正在 持续寻找值得被看见的 AI 团队与项目。
我们将通过「AI 产品市集」、内容报道、社群分发等方式,帮你触达早期用户、获得真实反馈,以及建立关键连接。
如果你正在做 AI 相关的事,欢迎和我们聊聊。

01
11B 参数只需要「知道怎么去知道」
Step 3.7 Flash 是阶跃 Step 系列的新一代 Flash 模型,总参数 196B+1.8B(ViT)、激活参数 11B,开源,支持本地部署,推理速度最高 400TPS,主打效率极致。专注四个方向:多模态理解、Agent 搜索、工具调用和代码生成。它延续了 Step 3.5 Flash「更快、更强、更稳」的核心特征,但进一步强调多能力协同,不追求任何单个维度的绝对峰值,而是围绕 Agent 任务链路做一体化设计,让模型在复杂流程中持续推进任务而不掉链子。
过去,行业习惯把模型的能力和效率分开讨论。能力在权重里,包括知识、推理、代码、多模态理解;效率在部署层,包括速度、吞吐、价格、延迟。
Agent 改变了这个划分形式。
Anthropic 在《Building Effective Agents》里把 Agent 定义为:由 LLM 动态决定流程和工具使用的系统,在执行中不断从工具调用结果和环境反馈中获得 ground truth,评估当前进展,再决定下一步。Agent 的任务不是「一次性给出答案」,而是「在循环中不断接近目标」。一个真实任务可能需要几十次视觉识别、十几次搜索验证、若干次代码执行和工具调用。模型越快,Agent 越能多观察一次;模型越省,Agent 越能多验证一次;模型越稳,Agent 越能把长任务跑完。
阶跃在 Step 3.7 Flash 上做了一个明确选择:减少把海量视觉常识和单步极致感知都压进 11B 激活参数权重里的冲动,在权重中保留核心推理引擎,也就是官方所说的 Essential Reasoning Loop,把一部分感知边界和世界知识外推到推理阶段,再用 Flash 的速度和 Test-time Agency 支撑多轮行动。
翻译成人话就是: 11B 参数的模型不需要「什么都知道」,它更需要「知道怎么去知道」。 看不清的图,可以裁切、放大、再读一次;拿不准的信息,可以搜索、交叉验证,再回到任务里继续推进。前提是这些动作足够快、足够便宜,否则 Agent 就只能押注第一眼判断。
这个方向也不只出现在阶跃身上。Cursor 训练自研模型 Composer 时,同样把模型能力放回具体工作流里理解。 Cursor 模型负责人 Federico Cassano 在红杉的访谈中提到 ,权重容量有限,Cursor 关心的是「在 Cursor 中做软件工程」这个具体任务,因此会把权重容量集中给这个工作流,其余能力通过推理时工具调用和环境反馈补齐。Composer 的 RL rollout 也发生在完整 Cursor agent session 中:模型调用工具、生成代码、接收反馈,再根据结果获得 reward,质量、速度、成本一起进入优化目标。
应用场景反向塑造模型的权重分配;Agent 场景同样在反向塑造 Flash 模型的能力组织方式。
共同趋势是: Agent 时代的模型效率,不只来自算得快,也来自能力在权重、工具、环境和推理循环之间的重新分配。
02
效率极致的含义,
是让 Agent 多做一步
Step 3.7 Flash 的多模态、Search、Tool Use、Code 四种能力,围绕同一件事展开:让 Agent 的循环跑得更快、更稳、更省。
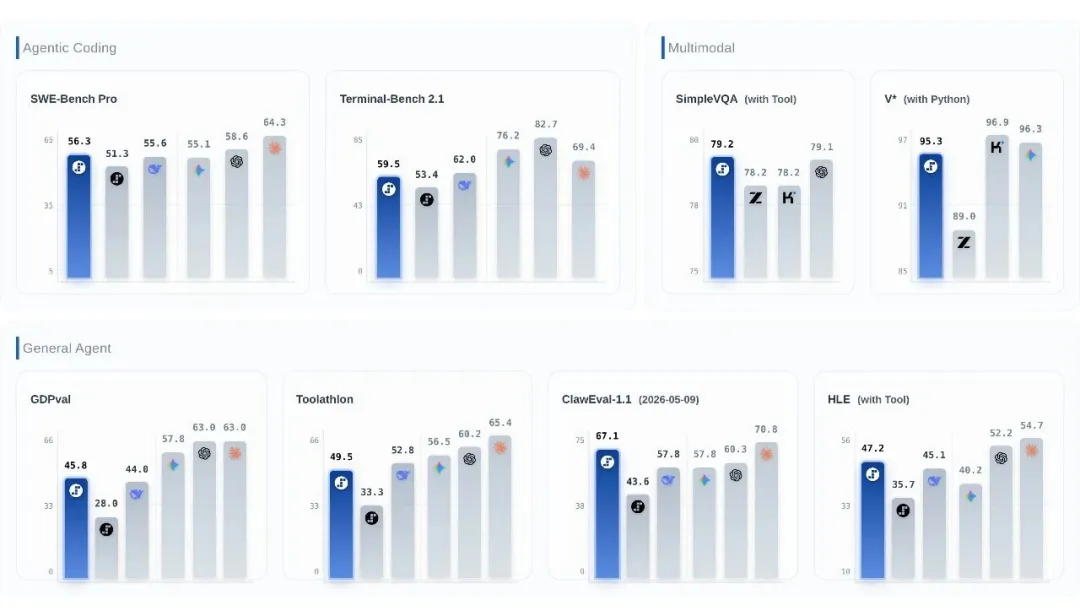
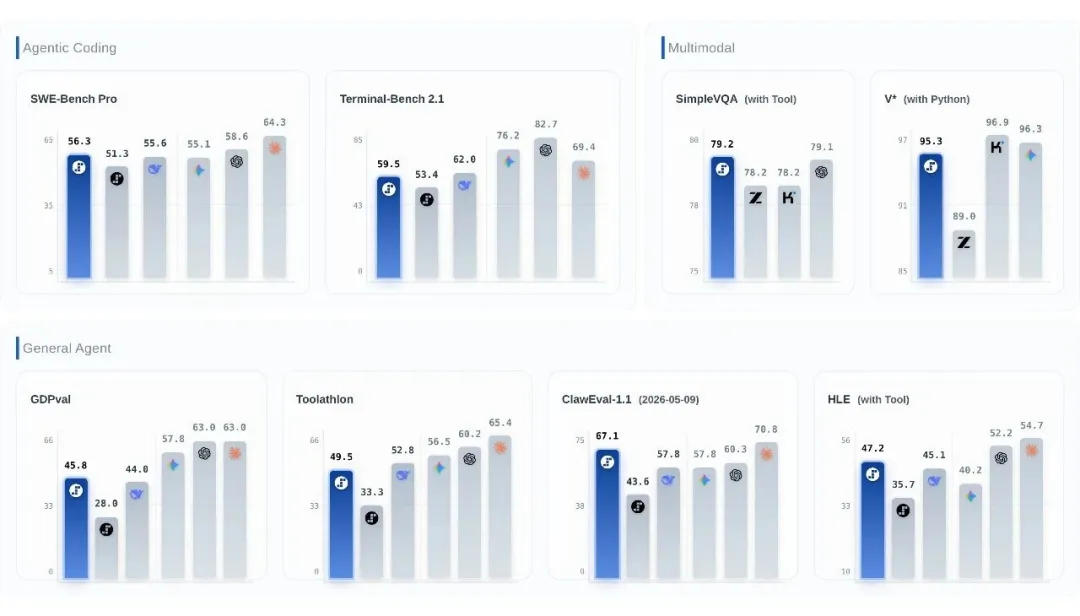
柱状图中左一为 Step 3.7 Flash、左二为 Step 3.5 Flash(Multimodal 除外)
2.1 多模态不是单次看图,而是反复感知世界
传统多模态模型处理图片,常常是输入一张图,输出一段描述,然后结束。但真实世界的视觉任务远比这复杂。一张专业界面、一份复杂文档、一个需要逐步操作的软件环境,都很难靠一次判断解决。
Step 3.7 Flash 的做法是引入 Visual Python Tool:模型可以在推理中途自主对图像进行 crop、zoom 和 re-read,把视觉理解从单次判断变成多轮观察循环。按照阶跃给出的测试口径,在高难度视觉感知任务上,11B 激活的 Flash 模型已经达到接近甚至超过部分大参数旗舰模型的水平。
为什么这和「效率」直接相关?因为多轮观察意味着多次视觉推理调用。只有模型足够快、足够便宜,这种循环才在工程上可行。否则模型只能猜一次,很难反复确认、反复修正。
一个典型 demo 是驾驶舱场景:用户只需输入指令「如何起飞」,模型就会自动框选驾驶舱界面,识别大量专业仪表与状态信息后,输出一份完整的起飞操作说明。它完成的不是「描述画面」,而是「环境感知 → 状态理解 → 任务推理 → 操作指导」的闭环——输出的不是 caption,而是面向目标的 step-by-step 行动方案。 这本质上是 Agent 的核心能力:理解环境状态,并持续帮助用户在复杂系统中行动。 多模态的终点,不是看懂世界,而是帮助人类在复杂系统里行动。
另一个更接近企业场景的例子是发票批量识别:上传 12 张不同场景、不同格式、不同拍摄角度的手机发票,模型要识别金额、税额、商户、时间和消费场景,再整理成统一表格,导出 Excel 或 CSV。这类任务过去需要 OCR、规则工程和人工校对拼在一起,现在可以被压缩进一个端到端的 Agent workflow。
2.2 Search 从外挂工具变成思考的一部分
过去 AI 用搜索,常见方式是先生成一个答案,发现知识不够,再调用搜索补一下。到了 Agent 场景,搜索开始进入推理链路:一边想,一边查,一边验证,再继续想。
一个常见的场景是街景图片识别。模型看到画面中不认识的建筑 logo,传统做法只能依赖权重里的记忆去猜,猜不出就容易输出未知或幻觉。Step 3.7 Flash 的官方展示里,当模型判断自己的知识不足时,可以自主发起视觉搜索,用图片线索检索外部信息,确认公司和业务,再把验证后的信息带回推理链路。
这类能力的价值在于,模型减少对「脑子里的知识」的单独依赖,开始结合实时信息、外部数据和可验证来源,进行多轮循环。在阶跃的 Search-augmented VQA 口径下,Step 3.7 Flash 已经达到 Frontier 水平。更直白的理解是:搜索能力让 Flash 模型释放了一部分参数记忆压力,也让 Agent 在真实世界信息中获得校正。
Anthropic 在 Agent 工程文章中也强调过类似观点:Agent 需要不断从工具调用结果和环境反馈中获得 ground truth,评估当前进展。搜索在这里不只是找答案,更像是给判断增加真实世界锚点。
2.3 一段 prompt,一个可运行的应用
Code 是 Agent 执行复杂任务的通用方式。会写代码、运行代码、根据报错修复的模型,可以把许多复杂任务从「回答」推进到「自动化执行」。
开发者 yetone 有一段自然语言 prompt*,让模型生成一个功能完整的 macOS 语音输入法应用。Swift 实现,包含实时语音转录、LLM 纠错、浮窗波形动画、全局快捷键监听、多语言切换。实测下来,20min,Step 3.7 Flash 完成了端到端的交付。
地址:https://github.com/yetone/voice-input-src
03
Agent 进入生产,
真正难的是把模型组织起来
模型进入 Agent 场景后,面对的情况和 Chatbot 完全不同。
大多数现有模型是为 Chatbot 场景训练的,它们在结构上就不适配 Agent 的循环。
Chatbot 的工作方式是「接受问题,在有限 context 里推理,给出答案」。这种模式鼓励模型在单次回答里尽可能完整,模型的后训练目标,就是把一个问题回答好。但 Agent 需要的是另一种模式:接收来自环境的 observation,做一段短暂推理,选择下一步 action,执行,再从结果中获得新的 observation。这是持续的交错过程,而不是一次性的大推理。
第一个变化是 time horizon。OpenAI 在介绍 Codex agent loop 时强调,agentic coding 的进展越来越关乎更长时间跨度里的连贯性、端到端任务完成和失败恢复。长程能力不能只靠更大的上下文窗口解决,还需要按需获取上下文、压缩历史、管理任务状态。
长程 Agent 能力,不是靠更大的上下文窗口,而是靠更好的上下文管理,以及更适配 Agent 工况的训练目标。
第二个变化是推理要和环境反馈交错。Agent 不能只在脑内完成所有判断,它要在工具结果、文件系统、搜索结果、代码运行反馈中持续评估和调整。
这也引出好模型之外的另一个特质。LangChain CEO Harrison Chase 说,long-horizon agents 的出现,需要有两个条件:更好的模型,和更成熟的 harness/context engineering。好的 Harness 要处理工具调用、搜索集成、代码执行、上下文压缩、任务状态、结果验证和错误恢复。模型能力要进入这套系统,才能变成可交付的工作结果。
正因为 Harness 需要大量中间调用,Flash 才有独立价值。每次都依赖最强、最贵、最慢的模型,系统很难规模化。效率极致的 Flash 模型,正适合成为在 Agent loop 中被反复调用、低成本持续推进任务的执行型基座,这个位置,旗舰模型因为成本和延迟无法填补。
04
Flash 模型的新生态位,
是在循环中把任务做完
回到最初的问题:模型竞争到底在比什么?
Step 3.7 Flash 给出的答案是:从单次回答的聪明程度,转向 Agent loop 中的任务完成效率。
当能力从静态权重竞争转向推理时循环竞争,速度和成本就会从工程指标变成能力实现路径。效率极致的意义,也从把一次回答变快,转向让 Agent 在真实任务里多观察一次、多搜索一次、多验证一次、多恢复一次。
对创业者和应用团队来说,选择 Agent 基座模型不能只看榜单峰值,还要看三件事:一条任务链路能跑多少轮,失败后能不能恢复,成本能不能支撑长期调用。
这也是「多快好省」真正该落到的地方:多模态让模型进入复杂场景,快速让循环发生,好用意味着能完成任务,省成本决定它能不能被持续调用。
Agent 时代不会只奖励最大、最强的模型,也会奖励最适合被循环调用、反复验证、持续执行的模型。到这个意义上,效率不再只是智能的成本问题,它正在成为智能本身的一部分。


