
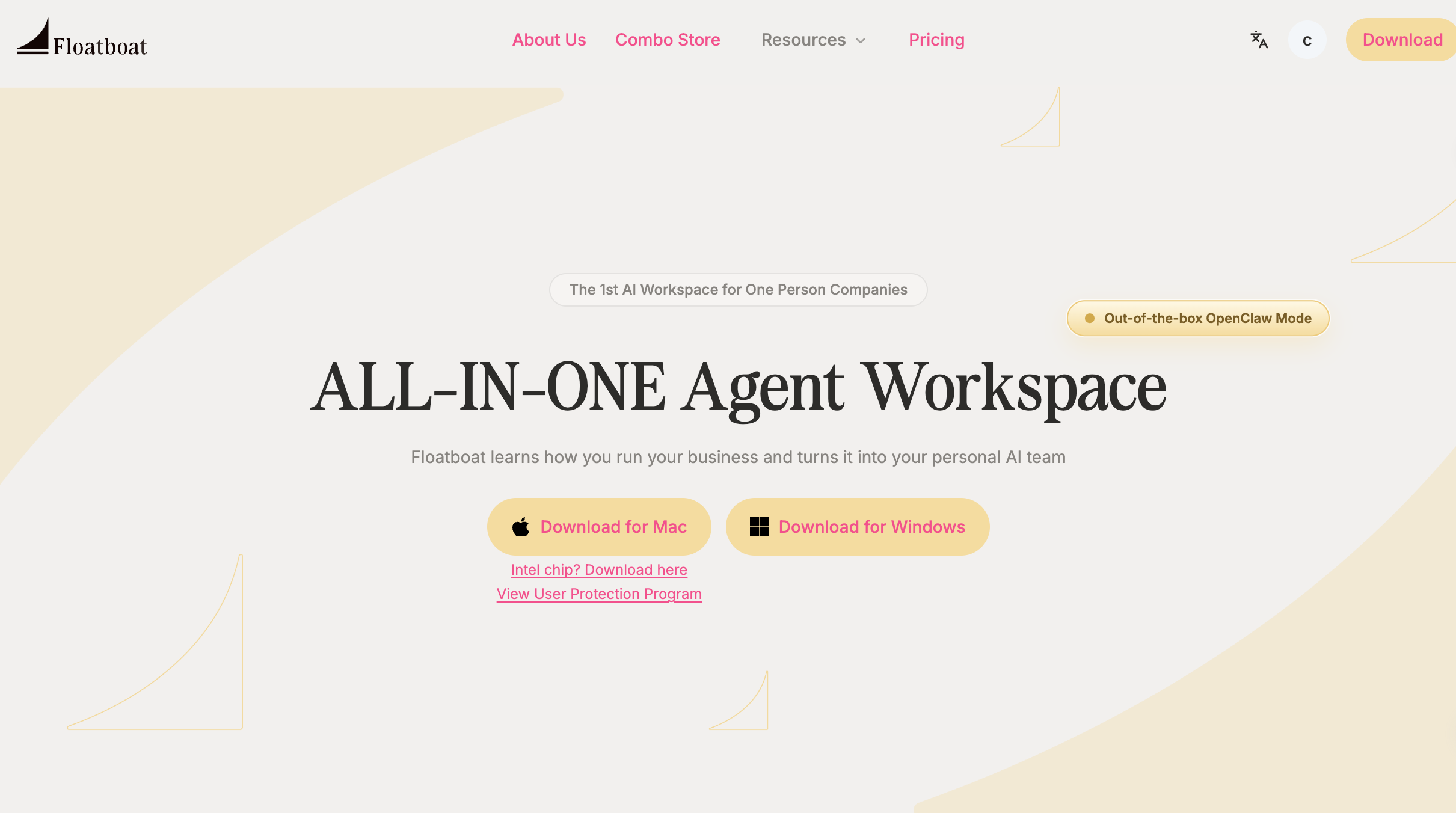
面向 OPC 的 Agent 工作空间。
最近,端侧 AI Agent 已成为 AI 办公赛道的核心赛道,从 Openclaw 掀起的端侧智能热潮,到各类新 Agent 产品密集亮相,行业在技术迭代与产品落地的过程中,也呈现出一种割裂状态:一方面大模型的通用能力持续提升,Agent 的工具调用、指令遵循能力不断优化;另一方面,全球超 10 亿规模的知识工作者群体中,多数人的日常办公仍未摆脱 “多窗口切换、上下文反复投喂、工作流与 AI 能力割裂” 的普遍痛点。
图片来源:floatboat 官网
最近,一款桌面客户端产品Floatboat开启了内测,它集成了文件管理器、浏览器和AI对话界面 ,主要面向OPC群体。
这款产品究竟针对 AI 办公的哪些核心问题给出了新的解决方案?其产品设计与行业主流方向有何差异?我们与 floatboat 创始人谭少卿进行了对话,还原这款产品的核心逻辑与行业思考。
一、AI办公的最大痛点,不是模型不够强
“我们测过,即使用户完全不调用floatboat的Agent功能,纯工具层面的办公效率也能提升2-5倍。”对应谭少卿这句话的,是当下AI办公赛道存在的一种情况——大多产品都在卷模型能力、卷多模态效果、卷工具调用的丰富度,但AI和用户的原生工作流,仍然是有些割裂的。
这可能是每个知识工作者的日常:写一篇深度稿件,你要先在浏览器里查行业资料、扒数据,再打开文档整理素材,接着切到GPT、Claude等的窗口里,把素材一段段粘贴进去,写prompt告诉AI要写成什么风格,等AI生成后,再复制回文档里手动修改,过程中发现缺了数据,又要重复一遍“浏览-复制-粘贴-投喂”的循环。
更不用提身兼数职的OPC创业者,写BP要同步产品设计文档、用户反馈、市场数据,写JD要同步公司愿景、产品特性、团队情况,做投放要管素材制作、账号运营、数据复盘,所有的信息散落在本地文件夹、微信聊天框、浏览器网页、各类SaaS工具里,AI根本无法触达完整的工作流,只能做单点的、碎片化的任务处理。
floatboat的解法,跳出了“对话框即Agent”的行业惯性,它没有在传统办公流程里加一个AI对话入口,而是直接打造了一套浏览器+文件管理器+AI Agent三位一体的AI原生办公环境——这也是产品最早的代号AoE的由来,既是游戏里“范围伤害”的术语,也是AI Office Environment(AI办公环境)的缩写。
这个设计的核心,是让Agent融入用户的工作流,而非让用户围着对话框转。在floatboat里,AI不是一个能主动感知你工作状态的协同者:你打开的产品设计文档、浏览的行业网站、操作的本地文件夹,都会成为AI可感知的上下文,不需要你手动上传、复制粘贴、写长长的prompt,它天然就知道你正在做什么、需要什么。
比如写融资BP时,你只需要在左侧打开产品设计文档、市场调研材料,对着AI说一句“写一版种子轮融资BP”,它就能自动读取所有上下文,生成完整的BP内容,甚至能根据需求迭代20多个版本,全程没有任何文件传输的操作;招聘写JD时,你不用再大段给AI解释公司情况,只需要说一句“帮我写一个测试岗位的招聘JD”,AI就能自动读取左侧的公司资料,生成精准匹配需求的文案,你只需要微调细节就能使用;内容创作时,你可以直接用内置浏览器浏览博主的社交媒体内容,一句话让AI把博主三天的帖子整理、转录、配音,生成一期完整的播客,全程不用切换窗口、不用下载转录工具。
图片来源:极客公园
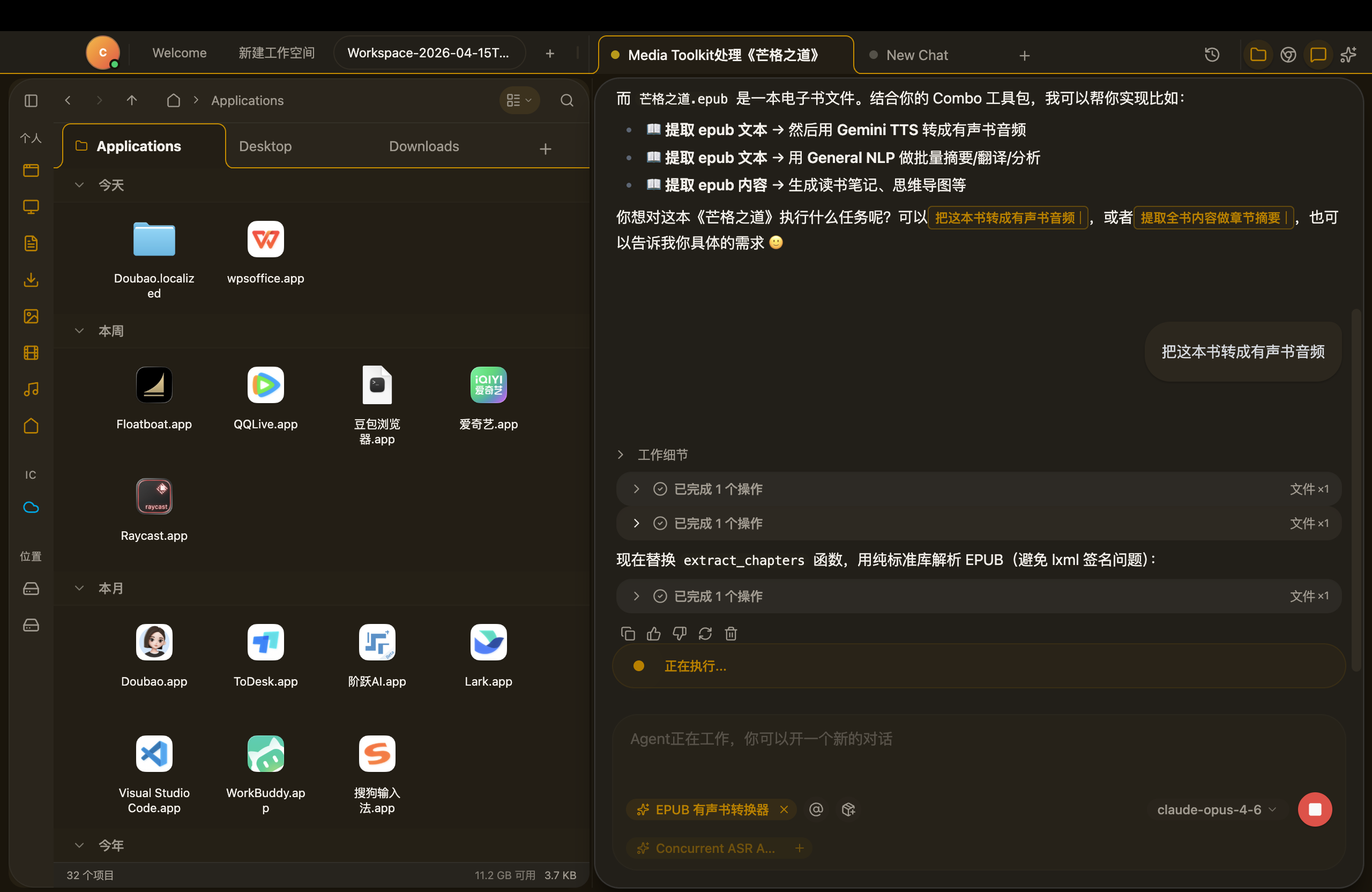
在试用过程中,能感受到确实便利不少,在工作空间里,我可以同时开启多个文件夹并自由切换,文件浏览和查找的效率很高;也能直接将多份文档拖入对话区域,让 AI 分析它们之间的关联与逻辑。在处理网页信息时,内容可以随手拖拽保存到本地文件夹,无需复制粘贴;内置编辑器支持直接修改文档,每一处改动都会被 AI 同步感知,不需要重新上传或手动同步上下文。
完成一次任务后,比如按个人风格生成稿件,我可以将整段工作流程一键保存为 Combo Skill。系统会自动记录操作步骤、表达偏好与执行逻辑,形成可重复使用的技能模板。后续遇到相似任务时,AI 会根据当前上下文主动推荐匹配的 Skill,加载即用,不必手动查找或输入命令。
对话式产品的逻辑是“人找AI”,你必须主动把所有信息、指令喂到AI嘴里;而floatboat的逻辑是“AI跟着你的工作走”,它就在你的办公环境里,你的工作流在哪,它的能力就延伸到哪。
二、Agent行业的内卷误区:我们到底需要什么样的端侧智能?
Openclaw带火了端侧Agent的同时,这个赛道也陷入了同质化的内卷:人人都在做端侧产品,个个都在搭skill市场,仿佛谁的skill数量多、谁开放的权限高,谁就能赢得市场。但现在,全球10亿知识工作者里,真正能把端侧Agent用起来的人,依然寥寥无几。
在谭少卿看来,绝大多数产品都踩中了行业的三大核心误区,而floatboat本质上是从底层就避开了这些内卷陷阱。
误区一是,要么只服务极客,要么想讨好所有人,却不懂用户的核心需求是截然相反的。“我们可以非常粗浅地把用户分成三级:极客用户、专家用户、大众用户,每一种用户的需求,都是完全相反的。”
这是谭少卿做了十几年亿级用户产品,核心的洞察之一,也体现了当下Agent产品的普遍通病:
极客用户追求的是极致的开放性,他们需要把产品的底层能力完全暴露出来,自己写代码、改脚本、自定义所有规则,这也是Openclaw、Claude Code能吸引极客群体的核心原因。但代价是极高的使用门槛,非技术用户光是安装部署就要花一个星期,对着终端命令行手足无措,更别说真正用起来;
专家用户追求的是极致的可控性,他们需要AI“指哪打哪”,需要它发挥的时候能精准完成需求,不需要它发挥的时候绝对不能画蛇添足。专业的内容创作者、视频设计师、分析师,根本无法接受AI随意修改自己的作品,可绝大多数Agent产品,都做不到这种精准的可控;
大众用户追求的是极致的易用性与安全性,对他们来说,AI工具的核心价值是“快点把活干完,早点下班”,他们没有时间去学怎么写prompt、怎么装skill、怎么调试Agent,复杂的知识管理、流程编排,对他们来说本质上都是伪命题。
市面上的产品,要么倒向极客,做了一个只有少数人能玩明白的玩具;要么想讨好所有用户,结果做成了四不像,极客觉得不够开放,大众觉得太复杂,专家觉得不可控。
而floatboat是先锚定了OPC这个核心群体——他们是最特殊的用户,既是自己领域的专家,又要身兼数职,同时做法务、财务、运营、创作、投放,工作流极其复杂,对效率提升的需求最为强烈。在此基础上,产品实现了三层用户的兼顾:
- 底层保留了极客用户需要的开放性,支持自定义combo skills与API调用,能满足深度定制的需求;
- 交互上做到了大众用户能接受的开箱即用,零代码门槛,不用写prompt,用自然口语就能驱动AI;
- 功能上满足了专家用户需要的可控性,内置编辑器可以随时手动调整内容,避免AI乱改,实现“人机协同”的精准控制,不用再下载文件、切换软件反复修改。
谭少卿提出了一个本质的判断:“我们每个人在不同的事情上,都处于不同的用户分层。你可能是一个技术极客,但在法务这件事上,你就是个大众用户;你是一个内容创作的专家,但在数据分析这件事上,你可能就是个普通用户。一个真正有普适性的生产力工具,必须要能覆盖这三层用户的需求。”
误区二是把skill市场当核心壁垒,却忽略了它只是过渡形态。
当下的Agent行业,几乎所有玩家都在疯狂内卷skill市场,仿佛谁的skill数量多,谁就能建立下一代应用生态。但谭少卿的判断是:“绝大多数skill市场,最终都会死掉。”
他给出了两个理由:第一,第三方skill存在无法解决的安全与信任问题。普通用户根本看不懂skill的代码,无法判断它有没有安全风险,而平台只做聚合,不承担任何责任,用户用了skill之后电脑出问题、数据泄露,只能自己承担后果。就像Openclaw的开源逻辑:“我玩法都开放了,你电脑搞坏了跟我有什么关系?”但在谭少卿看来,作为一款面向大众的商业产品,这种价值观是完全行不通的。
第二,skill本质上只是一个过渡形态。“skill是什么?其实就是我们人类在把自己的knowhow蒸馏给模型,模型厂开心坏了,终于有人系统性地把各行各业的经验扔给我。”谭少卿说,“而大模型的能力在飞速提升,现在需要skill才能实现的功能,未来模型会直接内化掉,变成自己的通用能力。”
在他看来,skill只会在需要高确定性的企业场景里长期留存,对于绝大多数普通用户来说,它注定只是AI发展过程中的过渡产物。
也正因如此,floatboat没有陷入skill数量的内卷,而是打造了一套完全不同的combo skills体系。它用Markdown这种人和机器都能读懂的介质,把指令、模板、脚本、API调用全部整合在一个文件包里,用户不需要懂低代码、不需要写复杂的脚本,就能轻松自定义技能,同时技能和用户的工作流、上下文深度绑定,不是一个孤立的功能插件。更重要的是,官方出品的skill都做了严格的安全审核,给用户兜底,从根源上解决了安全焦虑。
误区三是只做工具层面的创新,却不敢打破延续了几十年的数据垄断。
从PC时代的Office软件,到互联网时代的SaaS产品,办公领域几十年的发展史,本质上是一部平台垄断用户数据的历史。
传统的Office软件,用私有协议把数据、交互、逻辑强行分离,你必须用Word才能打开doc文件,否则就是一堆乱码,平台垄断了文件的唯一解释权;后来的SaaS产品,更是把数据垄断做到了极致,你存在飞书、Notion里的文档,绝大多数都不支持完整的原生格式导出,ChatGPT的记忆功能,甚至只允许导出用户自己发送的内容,AI回复的核心信息根本无法完整导出。
用户用的工具越来越多,却从来没有真正拥有过自己的数字资产。更不用提跨产品、跨Agent的协同:你在floatboat里的工作流,没法同步到Openclaw里;你在Claude里的AI记忆,没法用到GPT里;不同平台之间,数据和上下文完全是割裂的。
这才是办公领域最底层的顽疾,也是floatboat真正想要打破的壁垒——它推出了开源的self aware协议,重新定义了AI时代的数字文件格式。谭少卿用了一个很形象的比喻:“floatboat相当于是一艘承载用户数字资产的船,船与船之间流转的,就是self aware协议的文件包,它就是新时代Agent世界里的标准化集装箱。”
这个协议从底层重构了数字文件的逻辑:
- 它把数据、交互、逻辑重新整合到一个统一的文件包里,不止包含最终的交付结果,还完整保留了整个创作、协同过程中的所有想法、决策、修改记录、用到的skill与API,把AI需要的完整上下文,全部封装在一个文件里;
- 它实现了真正的跨产品兼容,只要是支持self aware协议的Agent产品,都能打开、编辑、使用这个文件包,用户再也不用被单一平台绑定,实现了“我的数据我做主”;
- 它保障了用户的数据所有权,所有的文件包、数据、AI记忆都储存在用户本地,不存在平台蒸馏用户数据、泄露用户隐私的可能,用户带着电脑,就带走了自己所有的数字资产。
这是在尝试对整个办公行业底层规则进行重构,把生产资料的所有权,重新还给每一个个体用户。
三、OPC时代,Agent的终局是重构生产关系
“我们选的切入点,是OPC。因为我们认为,OPC代表了先进生产力。”
AI大模型的爆发,正在彻底重构社会的劳动分工。原来需要专业团队才能完成的事,现在一个人就能做到:编程、做视频、写网页、做设计,这些曾经需要专门职业的技能,现在都被AI变成了人人都能掌握的基础能力。越来越多的人选择成为OPC,用10人以内的小团队,甚至一个人,去运营一整摊生意。
但传统的办公软件,并不是为这群人设计的。中大型企业的分工明确,法务、财务、运营、创作各有专人负责,工作流是标准化、线性的;而OPC创业者,要一个人扛起所有角色,工作流是动态的、交叉的、复杂的,信息散落在各个平台、各个文件里,对上下文流转、多角色协同的需求,远比中大型企业更强烈。
“如果你的工作越复杂,上下文流转越频繁,一个人扮演的角色越多,floatboat给你的效率提升就越大。”谭少卿说,“如果你的任务是单点的,分工特别明确,那它对你的提升可能没那么大。但未来,越来越多的人会成为OPC,会需要一个人顶一个团队,这就是我们的核心用户。”
工具只是floatboat的第一步,它真正想做的,是搭建一套分布式的Agent协同网络,让个体生产力第一次具备网络效应,重构AI时代的生产关系。
传统的协同办公,本质上是“人找人”。你要把自己的文件、文档、工作记忆全部暴露给对方,才能完成协同,不仅效率低下,还有严重的隐私泄露风险。而在floatboat的分布式网络里,协同的主体变成了Agent:你和同事的电脑,可以通过Agent实现安全、高效的协同,不用暴露自己的完整数字资产,只需要共享项目区间内的上下文,双方的Agent就能提前完成多轮信息同步与内容处理,最终人只需要做核心决策。
更具想象空间的,是这个网络对个体生产力的指数级放大。你的Agent可以在你休息的时候,和网络里其他用户的Agent完成对接、协作、甚至基础的商业交易。原本你一个人只能服务四五个客户,在Agent的加持下,你能服务的上限可以拓展到上百人。
谭少卿说,“当每个个体的生产力都被AI放大10倍、100倍,再通过开放的分布式网络实现协同,整个社会的生产关系,都会发生根本性的改变。”
交流最后,他反复提到一个核心观点:产品设计决定用户需求。“你把产品叫做Agent Infra Browser,那来的用户70%都是来抓数据的;你把产品定义成面向OPC的Agent工作空间,用户才会把剪视频、做科研、写播客、做战略分析这些真实的、复杂的需求释放出来。”


