
今天,质变科技正式发布首个多模态 AI 记忆平台 MemoryLake 龙虾版,面向开源智能体 OpenClaw 提供永久、可迁移、认知积累的多模态记忆。
引言:养虾从本科水平起步,省 91% 词元成本,这家 AI 记忆用 1 亿个多模态文件完成验证
今天,质变科技正式发布首个多模态 AI 记忆平台 MemoryLake 龙虾版,面向开源智能体 OpenClaw(俗称「龙虾」)提供永久、可迁移、认知积累的多模态记忆。这标志着 AI 正在从「无状态计算」向「有状态智能」完成关键一跃。
记忆,成为 AI 技术栈的新护城河
当前,GPT-5、Claude、Gemini、Kimi 等前沿模型正在快速商品化,模型性能差距缩小,API 成本大幅下降(GPT-4 价格比发布时便宜 97%),微调触手可及,开源方案加速发展。但行业专业人士发现一个普遍模式:最优秀的模型在生产落地中失败,不是因为缺乏推理能力,而是因为缺乏记忆连续性、上下文积累和自学习能力。
「用户重复输入信息,智能体凭空捏造过时数据,Token 成本飙升——『哇』的惊喜瞬间被挫败感取代。」质变科技创始人兼 CEO 占超群表示,「但认知状态是永久的。通过互动、决策、工作流程和结果积累的认知记忆会不断创造复利价值,这是任何模型都无法复制的。」
行业共识正在形成:记忆,是AI技术栈中新的护城河。
真正的记忆生产力:养虾应从本科水平起步
主流 AI 平台的「记忆功能」本质上高度趋同——存储用户偏好。
ChatGPT 的「记忆」:记住了你说过「我住在北京」。好,下次推荐天气时用上。
Claude 的「Projects」:把文件塞进项目上下文,会话结束后就散了。
各种 AI 的「长期记忆」插件:本质上就是一个键值对数据库,存的是「事实片段」。
「这是记忆的起点,而不是终点。」占超群强调。
RAG、向量数据库、长上下文——这些现有方案分别解决了不同层面的问题。RAG 解决了「让 AI 看到外部文档」的数据接入问题;向量数据库为语义检索提供了存储基础;长上下文窗口让 AI 能够「一次性看更多信息」。它们是记忆基础设施的重要组成部分,但单独使用任何一个,都无法构建完整的记忆系统。
六维认知记忆,重构AI记忆脑
MemoryLake 构建了完整的认知记忆体系,包含六种记忆类型:
背景记忆:那些永不改变的东西——你的价值观、世界观模型,由你手动设定,只读。
对话记忆:每一次对话,经压缩后可搜索。没有任何内容丢失。
事件记忆:你的时间线——发生了什么、何时发生、顺序如何,构建你的人生叙事。
事实记忆:一切可验证的信息——自动检测冲突、版本化、可溯源至来源。当来自不同 AI 的信息矛盾时,系统会实时检测冲突,并按预设策略自动解决。
反思记忆:你的 AI 注意到的深层模式——你如何思考、如何决策。
技能记忆:你构建一次的方法——在任何 AI、任何会话中永久复用。这实际上是把「提示词工程」升级成了「能力资产」。
为什么这很重要?
当你问:「我在这种情况下优先考虑什么?」——AI 调用你的价值排序(反思记忆)。
当你问:「上周我们讨论了什么?」——AI 检索事件和对话记忆。
当你问:「这个项目的风险在哪?」——AI 综合事实、事件和反思记忆进行推理。
这种分类让 AI 能像人脑一样,根据问题场景精准定位相关类型记忆,而不是在海量聊天记录中盲目搜索。
如果说 RAG 和向量数据库是「图书馆」,长上下文是「更大的阅览室」,那么真正的记忆系统应该是「大脑」——它不仅能查阅资料,还能将每次阅读、对话、决策内化为可复用的认知记忆。
真正的记忆生产力,应让AI从本科水平起步:有自己的知识体系(开放专业数据),能判断信息来源是否可靠(溯源),面对矛盾信息会思考、会判断(冲突解决),能看懂你的图表、听懂你的录音视频(多模态处理),能把每一次交互都沉淀为可复用的能力(反思记忆),而不是一句「用户喜欢深色模式」。
「AI 记忆护照」:一份记忆护照,通行所有 AI
另外一个关键问题——记忆的可移植性。传统 AI 系统的问题在于,你在 ChatGPT 里告诉它的偏好,在 Claude 中无法使用;你在 Telegram 里积累的对话历史,在 Slack 中需要重新开始。每个 AI 都是孤岛,每次切换都意味着「失忆」。
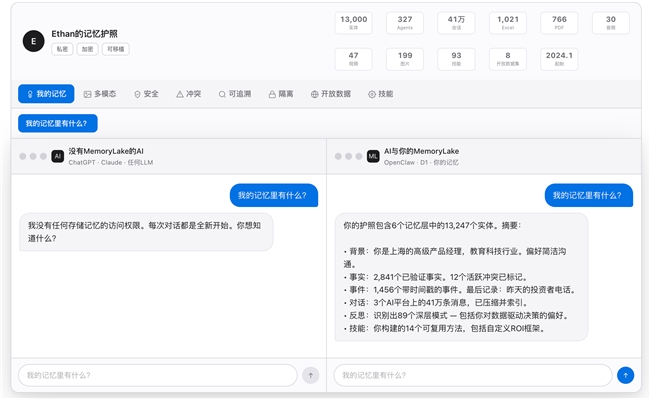
MemoryLake 采用「一份记忆护照,通行所有 AI」方案,解决 AI 生态的孤岛难题。就像护照让你在不同国家无需重新证明身份,MemoryLake 让用户的记忆在不同 AI 平台(OpenClaw、Qwen 等)之间无缝迁移。
用户分享:「当我的工作平台从 Telegram 迁移到 Claude Code 时,AI 居然还记得我三个月前提到的一个项目细节——那种感觉就像它真的『认识』我。」
核心技术:让记忆可信、可溯、可冲突解决
MemoryLake 的技术架构围绕「可信记忆」基础设施展开,核心能力包括:
智能记忆冲突解决:当来自不同来源或时期的记忆相互矛盾时,系统自动检测、标记并解决冲突。例如,在 ChatGPT 中上传报价文件显示商品 A 报价 300 美元,用户切换到 Claude 两小时后说「商品 A 报价 330 美元」,系统会自动提示冲突并给出推荐方案。冲突检测准确率达95%以上。
完整记忆溯源(Git式版本控制):每条记忆节点采用 Content-Addressable Storage,通过 SHA-256 生成唯一 commit ID,支持分支/合并/回滚,仅存储增量变化。每条事实携带完整溯源元数据(来源 AI/会话 ID/时间戳/置信度),通过 append-only 日志保证防篡改。你可以追溯任何一条事实的原始来源,导出符合合规要求的完整证明链。
隐私优先的安全设计:将安全设计为架构原点,全程加密用户笔记、文件、健康数据、密码、私人对话,引入 presidio 等权威 PII 检测模块,实现多模态隐私信息的 100% 检测和屏蔽。确保与 AI 工具对话时,安全敏感信息自动隔离。
开放数据集成:内置 4000 万学术论文、300 万 SEC 文件、50 万临床试验、实时金融数据、200 万化合物、1000 万美国专利等海量开放数据集。当私有记忆(如内部会议录音)与这些公共知识相遇时,AI 能做出真正有见识的推理——不仅听懂「GLP-1 药物」,还能结合最新临床试验数据,给出超越用户认知边界的洞察。
多模态记忆:MemoryLake-D1 是业内首个专注于多模态「记忆」理解与结构化提取的领域大模型,能处理复杂的 Excel 布局、扫描版 PDF、流程图、会议音视频等。在头部文档办公企业场景中,通用方案准确率仅 60-70%,而 MemoryLake 实现了 99.8% 的召回率。
多粒度记忆隔离与共享:通过策略矩阵灵活控制任意维度记忆的共享与隔离:
Global 级:全局共享的组织记忆
Agent 级:每个智能体的私有记忆(角色定义、专属知识)
Session 级:每次会话的工作记忆
以游戏 AI 为例:共享层为基础世界观,Global 级为所有 NPC 共享设定,Agent 级为每个 NPC 独立记忆,隔离层为会话记忆/私有记忆,Session 级为玩家本次对话上下文——灵活配置,一应俱全。
亚秒级多跳推理:记忆会「自己思考」。
当用户问「我应该投资这个医疗 AI 项目吗?」
第 1 跳:检索「医疗 AI 项目」相关记忆 → 找到:「当前评估项目:斯坦福团队,2 亿估值,5 家医院试点」
第 2 跳:关联「你的其他医疗投资」→ 找到:「18 个月前投资 XYZ 公司,同样医疗 AI 赛道」→ 提取教训:「XYZ 项目因 FDA 审批延迟导致融资困难」
第 3 跳:关联「你的投资偏好」→ 找到:「你倾向技术壁垒强、有专利保护的项目」→ 找到:「你对监管风险敏感」
第 4 跳:关联「外部知识」→ 从行业报告记忆中提取:「医疗 AI 的 FDA 审批平均周期 18-24 个月」→ 从新闻记忆中提取:「斯坦福团队成员中有前 FDA 顾问」
综合输出:「建议谨慎乐观。优势:(1) 团队有 FDA 资源,可能加速审批;(2) 试点医院增速 67% 显示 PMF 良好;(3) 符合你的『技术壁垒优先』偏好。风险:(1) 参考 XYZ 项目经验,需重点尽调 FDA 进度;(2) 估值 2 亿偏高,建议压价到 1.5-1.8 亿。建议:进入下一轮尽调,重点关注专利组合和临床数据。」

在全球极具挑战性的长程对话记忆基准测试 LoCoMo 上(平均 300 轮、跨数月、多模态内容),MemoryLake以94.03%的综合得分位列全球第一,显著超越其他记忆方案及人类标注基线。
性能为王:91% Token 成本下降背后的生产级验证
MemoryLake 的性能指标为其生产级记忆基础设施能力提供了坚实支撑:
Token成本直降91%:返回给模型的不是冗长原文,而是经过理解、压缩和关联后的高价值记忆片段
记忆准确召回率99.8%:在严苛办公场景端到端评测中达到惊人的 99.8% 准确率
无限记忆:支持 PB 级记忆容量,可随着用户、组织和业务持续增长
毫秒级延迟:检索层支持亚秒级多跳推理查询,底层数据平台在超大规模生产环境中实现毫秒级检索延迟
从消费端到企业端:10 万亿记录的实战验证
在消费领域,MemoryLake 已服务全球超过 200 万专业数据用户。在企业领域,服务了超大规模文档办公企业、头部移动办公应用、大模型公司、大型国央企等——生产系统中超10万亿级记录、亿级文档的实战验证,MemoryLake 在与全球云大厂和 AI 典型厂商的竞争中,成本、准确召回率和延迟等性能指标实现数倍于对手的优势。
资本押注:2 亿美金估值背后的千亿赛道
根据 Mordor Intelligence 预测,到 2030 年,全球 AI 智能体编排与记忆系统市场规模将突破 284.5 亿美元,成为 AI 基础设施中增长最快的细分领域。
质变科技创始人占超群拥有超过十年的阿里云核心数据体系搭建经验,曾主导国内营收最高的云原生数据仓库产品,并在 TPC-H 和 TPC-DS 两项全球权威数据库基准测试中同时登顶(中国首次)。2023 年,团队通过面向 C 端专业用户的决策智能体 Powerdrill 快速积累全球超 200 万用户,沉淀出端到端的记忆工程技术,最终产品化为 MemoryLake。
这种扎实积累与快速验证,让质变科技在创业初期便收获资本高度青睐,获得高瓴创投与光速光合联合投资的数千万美元融资,估值超2亿美金。
记忆的引力效应:成为 AI 时代的记忆底座
模型的护城河在于算力和数据,而记忆的护城河在于「信任」与「中立」。企业不愿意把积累了数年、涉及核心业务的认知记忆,锁死在一个特定模型厂商的生态里。他们需要一个像 Snowflake 一样、能自由连接任何模型和 AI 的中立记忆层。
「记忆是有引力效应的,越用越好用,价值越来越大;模型和智能体可能随需切换,但记忆基础设施是个人和组织需要持续构建的核心资产。」占超群在谈及公司独立性时表示,「作为全球少有的兼具记忆能力、模型能力和数据平台能力于一体的全栈玩家,我们有机会做出一个像 Databricks、Snowflake 那样的 AI 时代基石企业。」
---
关于质变科技
质变科技是一家专注于可信 AI 记忆基础设施的技术公司,由前阿里云核心数据团队创建,获得高瓴创投与光速光合联合投资。公司推出的 MemoryLake 是全球首个大规模多模态 AI 记忆平台,通过认知记忆体系让 AI 具备持久、可迁移、自进化的记忆能力,已在 10 万亿级记录生产场景中得到验证。
来源:互联网


