

当前,业内深陷于一个反直觉困境:即便触觉传感器在机器人领域已经广泛应用,整个行业却深陷"感知更多、做得更差"的困境。
想象这样一个场景:你正在擦桌子、削水果,或者插拔一个精密零件。这些动作对人类来说轻而易举,然而对于机器人来说,这些看似简单的操作却是一道难以跨越的技术鸿沟。
近期,它石智航联合新加坡国立大学、复旦大学、中科院自动化所、清华大学、中关村学院以及北京航空航天大学六大顶尖机构,推出 OmniVTA 视触觉操作框架和 OmniViTac 大规模视触觉数据集并发表相关论文,让机器人实现从被动感知,到对触觉进行主动预测和闭环精准控制,迈出灵巧操作的关键一步。

当前,业内深陷于一个反直觉困境:即便触觉传感器在机器人领域已经广泛应用,整个行业却深陷"感知更多、做得更差"的困境。机器人明明"摸得到",却依然"不会用"。为什么给机器人提供额外的触觉感知,反而可能让它表现更差?答案在于,当前主流方案对触觉本质存在根本性误解。
机器人操作领域长期缺乏对接触动态的建模和对触觉信息的有效利用。当前主流方案仅将视觉与触觉特征简单拼接后输入策略网络。这种方式看似合理,实际上却忽视了触觉的核心特征。相较于具备全局语义与连续观测能力的视觉,触觉信号高度局部且由接触事件驱动,无法提供全局感知,难以支撑长时序规划。
更关键的是,接触本质上是一个随时间演化的动态过程。擦拭、削皮、插接、拧紧等操作,都是"接触状态随时间不断变化"的过程。然而,现有方法通常仅利用当前或历史几帧触觉观测,缺乏对"接触如何随时间演化"的显式建模。结果是触觉往往只被用于简单的接触检测或视觉遮挡补偿,而无法真正参与对接触过程的预测与决策。同时高频触觉数据缺失也让模型难以学习真实接触规律,操作稳定性与泛化性严重不足。
人类真实行为启发:"预测+反馈"协同机制
如何破解这一困局?答案或许就藏在人类自身的神经机制中。
神经科学研究表明,人类在进行接触操作时,依赖的是一套"预测+反馈"的协同机制:大脑一方面通过前向模型提前预测动作将带来的感觉变化,另一方面通过实时感觉反馈进行快速修正,抵消误差和扰动。正是这种"先预测再修正"的机制,让人类能够在不确定的环境中,依然完成稳定而灵巧的接触操作。
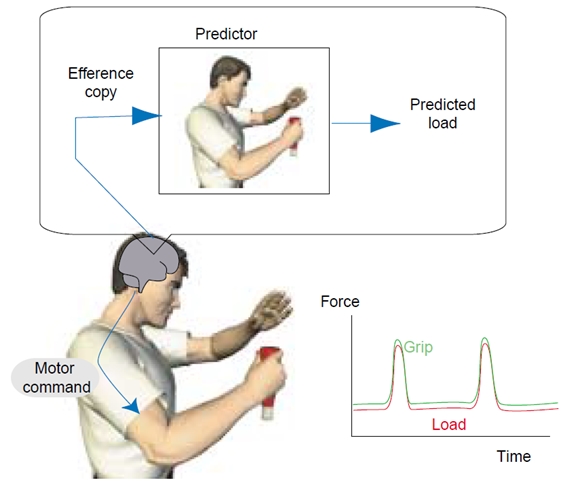
「预测 + 反馈」的协同机制。图源:Motor prediction[1]
本次它石智航联合六大顶尖机构,从数据底座与技术框架双向攻坚。在数据层面上,团队发布了OmniViTac大规模视触觉数据集,如下图所示,为后续模型训练筑牢基础。
这是迄今为止规模最大、质量最高的视触觉操作数据集之一,目前已收录 2 万余条操作轨迹,覆盖近百类任务和百余种物体,并将接触模式系统性分为擦拭、削皮、切割、抓取、装配以及手内调整六类,在数据采集过程中严格保证视觉、触觉与动作的高精度同步,并保留了原始传感器频率。该数据集也同步受到了业界认可,获得由魔搭社区(ModelScope)主办的「EAI-2025年度10大数据集」奖项。
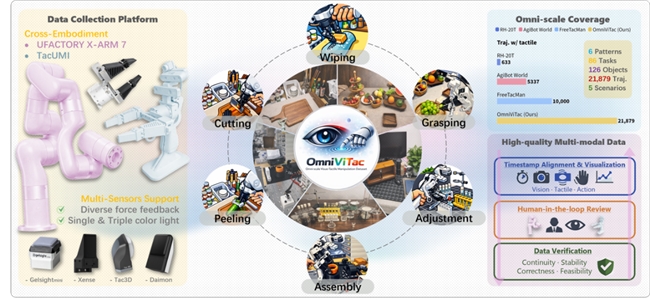
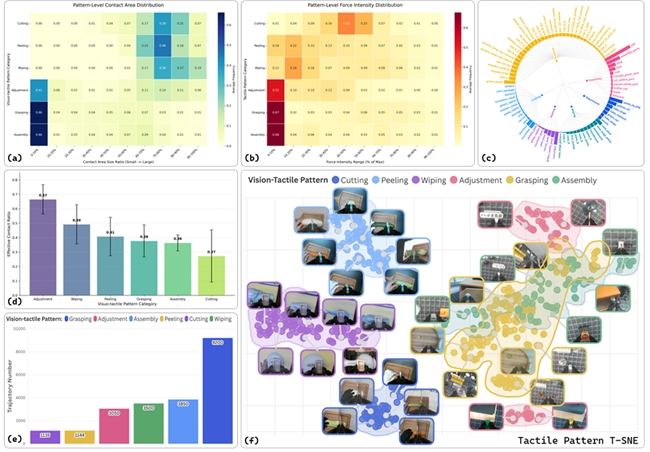
OmniVitac数据集
依托 OmniViTac 的多模态数据支持,它石创新提出了 OmniVTA——一种以世界模型为核心的视触觉操作框架。该方法的核心思路在于从「被动感知触觉」转向「主动预测触觉」:机器人不仅能够感知当前触觉信号,还实现了建模并预测未来触觉的演化过程,并以此指导动作规划与闭环调整。
在系统设计上,OmniVTA 采用慢–快分层控制结构,如下图所示:慢系统基于视觉–触觉世界模型预测未来触觉表征并生成动作序列,快系统则利用预测触觉与实时触觉反馈进行反射式高频控制,从而实现稳定、鲁棒且精细的接触操作。
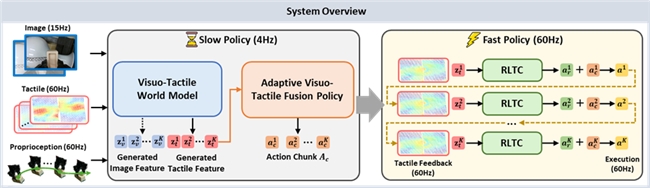
OmniVTA系统图
在此基础上,OmniVTA 通过四个关键模块协同构建统一的闭环控制体系,使机器人具备「预测触觉—理解接触—修正动作」的能力,从而重塑其在复杂接触场景中的操作表现:
TactileVAE:通过时空联合编码与隐式函数解码,将高频、稠密的触觉 3D 形变压缩为低维连续潜变量表示,如下图所示。该模块不仅在空间上保留细粒度接触结构(如剪切、法向形变等),还在时间上建模触觉动态变化,从而有效刻画接触过程的演化轨迹。在显著降低数据维度与计算开销的同时,为后续预测与控制提可泛化的触觉表征,使机器人能够高效理解当前接触状态并快速响应环境变化。
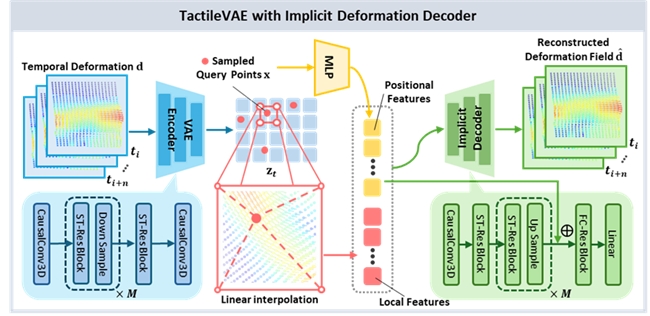
TactileVAE网络结构图
视触觉世界模型(预测模块):基于双流扩散生成架构,在共享条件约束下联合建模视觉与触觉的时序演化关系。视觉分支提供全局语义与几何先验,触觉分支聚焦局部接触动态,两者在潜空间中协同对齐,从而实现对未来触觉信号的高质量预测。通过显式建模「接触发生前—接触发生中—接触演化后」的动态过程,该模块使机器人能够提前预判接触趋势(如即将发生的接触、接触强度变化或滑动风险),为动作规划提供前瞻性信息支撑。
自适应融合策略(决策模块):引入 Latent Tactile Differential(LTD)编码器,对当前触觉与预测触觉之间的差异进行显式建模,从而提取接触动态变化的关键信号。在此基础上,结合门控(gating)机制对视觉与触觉模态进行动态加权,使策略能够根据接触阶段自适应调整感知依赖:在无接触或远接触阶段侧重视觉全局信息,在接触发生及演化阶段增强触觉主导作用。该模块有效避免了简单特征拼接带来的信息冲突问题,使动作决策更加精确且具备情境适应性。
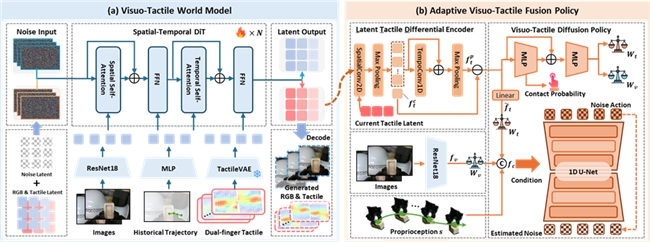
OmniVTA慢策略:视触觉世界模型+自适应融合策略
反射式触觉控制器(执行模块):基于预测触觉与实时触觉反馈,在 60 Hz 高频下输出单步修正动作,对慢系统生成的动作序列进行连续闭环补偿。该控制器通过建模触觉误差(预测–观测差异)实现快速响应,可在接触扰动、物体偏移或摩擦变化等情况下即时修正执行轨迹,从而显著提升操作稳定性与精度。其引入使系统具备类似人类「触觉反射」的能力,能够有效弥补低频规划带来的滞后性。
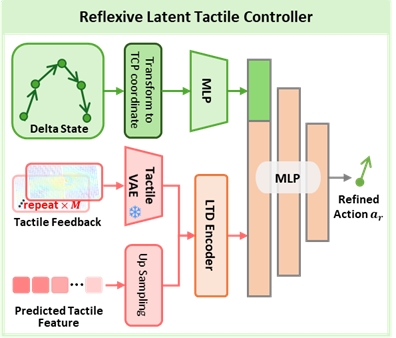
基于触觉特征的反射式控制器
实操验证:从"机械记忆"到"理解接触"
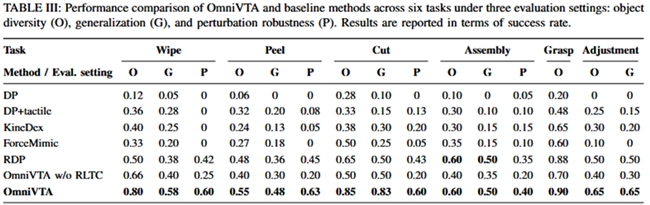
实验数据表明,OmniVTA 视触觉操作框架在不同物体、不同接触模式下均取得了最优性能。在位置变化、工具变化和外界扰动等情境中,展现出了远超传统方法的鲁棒性和泛化能力。

操作过程中实时扰动-恢复接触
更具深远意义的是,模型学习到了可迁移的接触动态规律。如下图所示,模型能根据预测的接触状态自适应调整视觉与触觉的权重,并在不同物体和工具下保持稳定表现。这表明机器人正在从「执行动作」走向「理解物理接触」,逐步具备类似人类的预测与反馈协同能力。
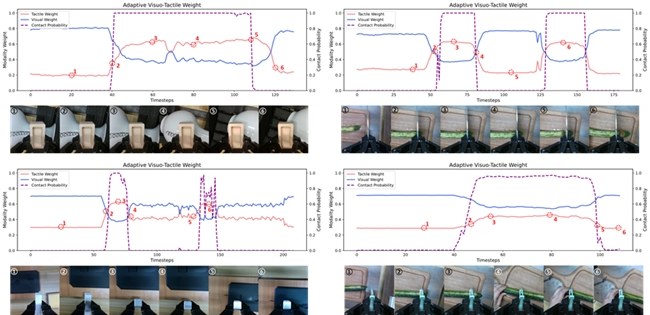
门控机制效果:触觉和视觉权重随操作过程的变化
可以看到,OmniVTA 展示了一条清晰的技术路径:以「世界模型」为核心,以预测为先导、反馈为保障,最终使机器人能够真正胜任精密装配、家居清洁与食材备制等工业生产与日常生活中不可或缺的接触密集型(contact-rich)任务。本次它石联合多所顶尖科研机构发布的 OmniVTA 框架,不仅在学术研究方面有所突破,更具有深远的产业应用落地价值,将具身智能「干活」的能力提升至可落地、可泛化、可规模化的全新高度。
引用
[1] Wolpert, Daniel M., and J. Randall Flanagan. "Motor prediction." Current biology 11.18 (2001): R729-R732.
来源:互联网


