
近日,国际声学、语音与信号处理会议 ICASSP 2026 公布录用结果。
近日,国际声学、语音与信号处理会议 ICASSP 2026 公布录用结果。江苏省语言计算及应用实验室多篇论文被会议接收。ICASSP 长期被视为声学、语音与信号处理领域最具国际影响力的学术会议之一,其录用成果集中反映了语音语言技术前沿的发展方向。
江苏省语言计算及应用重点实验室(以下简称「实验室」)由思必驰科技股份有限公司牵头,联合上海交通大学、苏州大学共建,是江苏省在通用人工智能领域布局的重要战略科技力量。实验室以思必驰的产业平台为依托,汇聚上海交大、苏大的顶尖科研资源,形成「产学研用」深度融合的创新共同体,聚焦语言计算核心技术,贯通基础理论、关键算法、产业落地的全链条创新。
实验室本次收录的论文成果聚焦 多语种语音识别、高效自回归语音合成 与 低码率神经语音编解码 等前沿方向,支撑思必驰核心技术能力持续增强:提升了多语种交互一致性、优化了端云协同实时响应、强化了分布式智能体在复杂场景中的感知与执行稳定性;并进一步升级了车载座舱语音助手、会议软硬件产品与智能家居终端的交互体验,同时提升面向海外与多行业客户的标准化交付效率与可扩展能力。下面介绍本次收录的代表性成果:
多语种语音识别
复杂口音与多语种环境下的识别鲁棒性强化,支撑车载座舱中的多音区交互与跨区域语音服务能力。
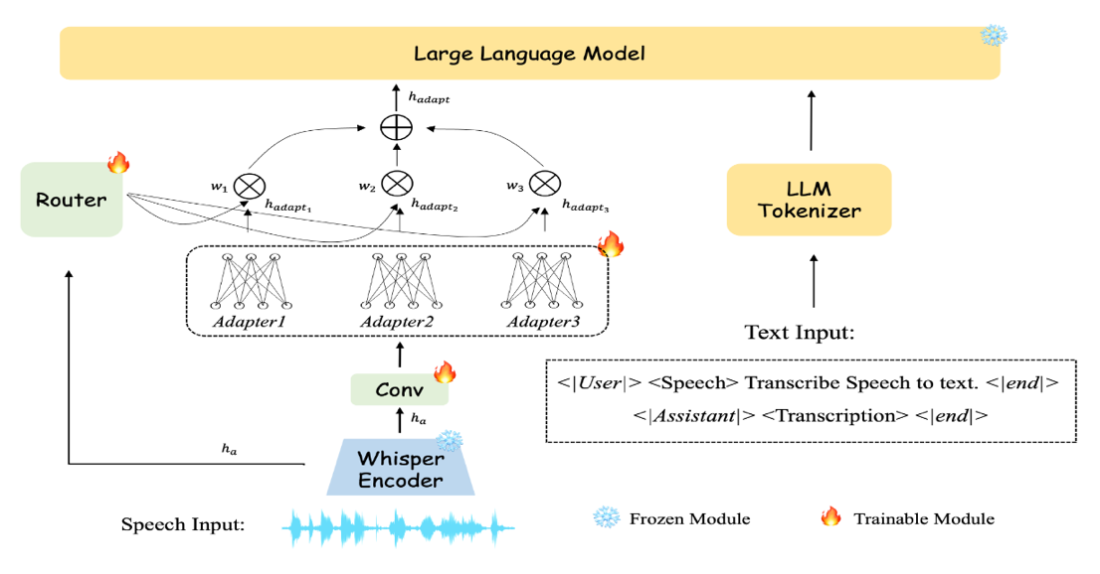
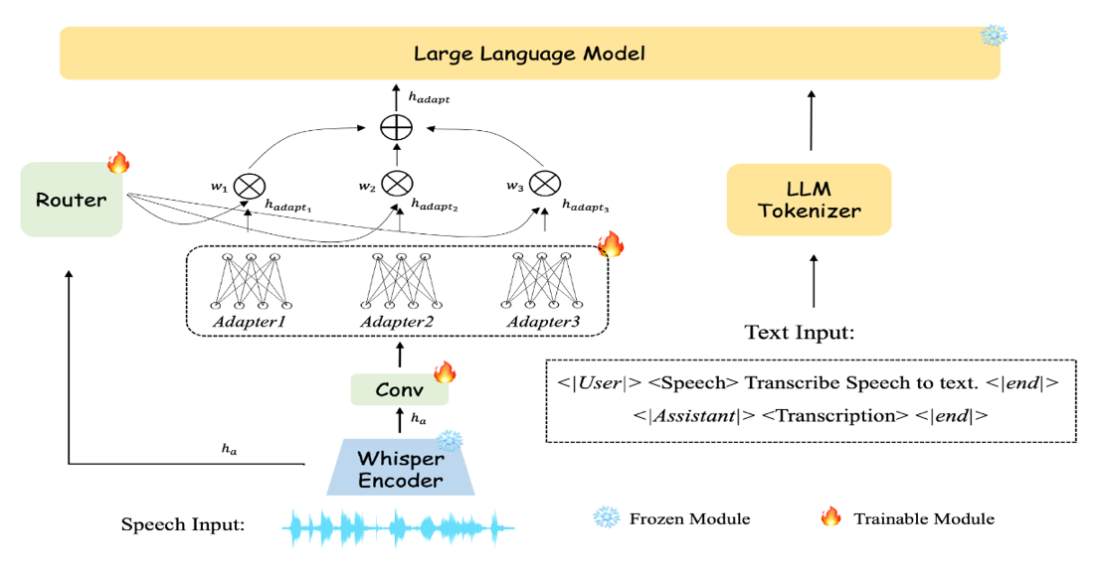
MOSA: Mixtures of Simple Adapters Outperform Monolithic Approaches in LLM-based Multilingual ASR 面向端到端多语种语音识别中的核心难题。该问题长期受限于两类结构性瓶颈,一是低资源语言数据不足,二是传统单一投影器难以同时兼顾跨语言共享与语言特异建模。
MOSA 采用 简单适配器混合 的结构范式,在统一框架内引入多专家协同机制,使跨语言共享知识与语言专属性特征能够实现有效分工与协同学习。该方法并未依赖更重的单体投影结构,而是通过多个轻量适配器的组合提升表示能力,因此在工程资源受限条件下更具部署价值。
实验结果显示,在训练参数量仅为 Ideal-LLM Base 六成的条件下,平均词错误率仍下降 13.3%。这一结果表明,多专家轻量适配策略不仅提升识别精度,同时在数据不平衡情形下展现出更强稳定性,为多语种识别系统的大规模落地提供了可验证路径。
高效自回归语音合成
提升合成语音的可懂度与响应效率,加强车载播报、办公助手语音反馈与多轮任务执行中的自然表达。
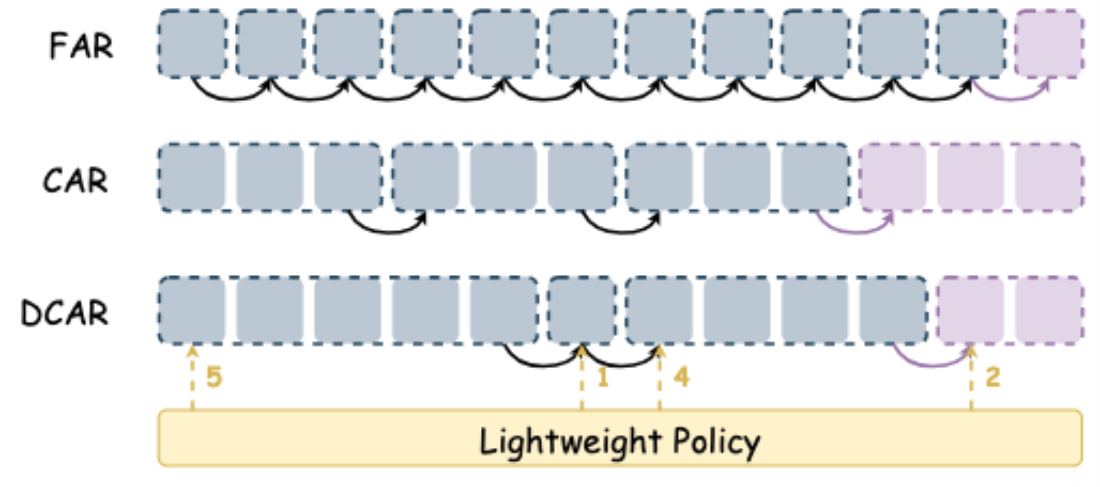
Robust and Efficient Autoregressive Speech Synthesis with Dynamic Chunk-wise Prediction Policy 针对自回归语音合成在长序列建模中的关键矛盾展开研究。传统逐词元预测方案在序列增长后容易出现注意力不稳定,进而引发时延上升与可懂度下降,这也是高质量合成模型进入实时业务的重要障碍。
DCAR 提出 动态分块预测策略。该策略通过多词元预测训练与轻量在轨模块协同,按语音内容动态调整预测跨度,降低模型对长序列逐步递推的依赖,同时保持合成细节质量。其核心价值在于将效率优化与语音质量优化统一到同一生成机制内。
在公开实验中,DCAR 相较传统逐词元预测模型实现可懂度最高 72.27% 的提升,并将推理速度提升至 2.61 倍。该结果显示,动态分块范式能够显著改善实时语音生成能力,为车载播报、会议助手与多轮语音交互中的低时延输出提供技术基础。
低码率神经语音编解码
优化低码率语音传输与端侧资源开销,赋能智能家居与消费终端中的低功耗部署、弱网稳定交互。
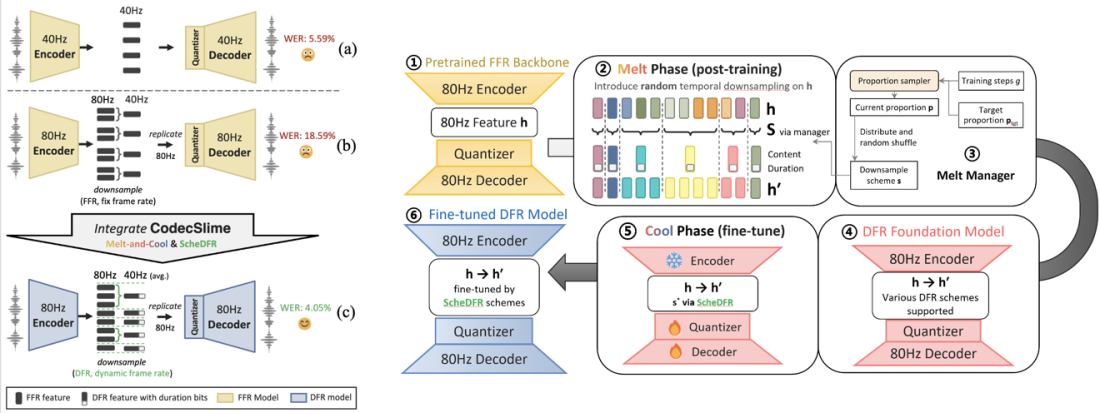
Codecslime: Temporal Redundancy Compression of Neural Speech Codec via Dynamic Frame Rate 指向神经语音编解码中的普遍问题。固定帧率机制默认语音时间信息密度均匀,然而真实语音在静音段、长元音段与快速过渡段的有效信息密度差异显著。固定帧率因此会在低信息区产生冗余编码开销。
CodecSlime 引入 动态帧率 机制,以插件化方式嵌入现有神经编解码体系,在不依赖额外监督的条件下压缩时间冗余。方法中的 ScheDFR 与 Melt-and-Cool 分别服务于推理侧与训练侧,使模型能够在不同时间密度区间自适应分配编码资源。
在典型 VQ-GAN 编解码骨干上,当系统运行于约 40Hz 动态帧率并保持约 600bps 量级码率时,CodecSlime 的重建词错误率相较固定帧率基线最多下降 28%。同时,模型在不同帧率设置下持续保持竞争性能,体现了重建质量与传输成本之间更灵活的工程权衡能力。
产品落地:智能车载、智慧办公与智能家居的持续升级
本次收录的研究成果共同推动思必驰全链路对话式人工智能系统在全流程可控、端到端贯通与规模化部署方面持续进阶。对于企业级产品而言,这类基础技术进展不仅提升单点模型指标,更重要的是提升跨模块协同效率与整体用户体验的可感知升级:多语种交互更稳定、语音反馈更自然及时、弱网与低功耗条件下的使用体验更顺畅。依托上述能力,思必驰在多行业项目中的交付效率与场景适配速度持续提升,为客户提供更一致、更可靠的语音交互服务。
结语
长期以来,思必驰深度参与国内外学术前沿研究,在 ICASSP、INTERSPEECH、ACL、EMNLP、AAAI、ICML、NeurIPS 等顶级学术会议上屡获佳绩,持续产出高质量科研成果,彰显了在人工智能语音语言关键技术领域的深度探索和重大突破。思必驰秉持科研与产业应用紧密结合的理念,将持续推进高水平科研成果向产品能力转化,围绕真实业务场景打磨可落地、可规模化、可持续优化的语音语言技术体系。
作为专业的对话式人工智能平台型企业,思必驰具有源头技术创新和应用创新的能力,自 2022 年 7 月获国家科技部批准建设「语言计算国家新一代人工智能开放创新平台」以来,接连于 2023-2024 年获批组建苏州市、江苏省、长三角三级创新联合体,并于 2025 年携手上海交通大学、苏州大学,牵头组建「江苏省语言计算及应用重点实验室」,成为国家人工智能战略科技力量的重要组成部分。思必驰承担了包括国家重点研发计划、国家发改委「互联网+」重大工程和人工智能创新发展工程、国家工信部人工智能与实体经济深度融合项目、长三角科技创新共同体联合攻关计划项目等十余项国家级、省部级项目,展现出卓越的科研实力与项目落地能力。思必驰深耕语音语言领域,凭借自主研发的核心技术多次在国际研究机构评测中夺得冠军;曾三度斩获国内人工智能最高奖「吴文俊奖」,荣获中国专利优秀奖,以及信通院车载智能语音交互系统最高级别认证等重要荣誉。技术创新能力备受全球瞩目,被高盛全球人工智能报告列为关键参与者,也被 Gartner 评为东亚五大明星 AI 公司之一。截至 2025 年年底,思必驰拥有近 100 项全球独创技术,已授权知识产权 1700 余项,其中已授权发明专利 700 余项,牵头/参与了 70 余项国家/行业/团体标准,获得 23 项国家级的产品认证,8 项算法通过深度合成算法备案。思必驰坚持自主的大模型技术路线,加速研发端云协同的分布式智能体系统,以任务型交互为核心,结合智能硬件感知优势,推进分布式的可规划的可信智能体落地,服务企业客户。
来源:互联网


