
商汤科技正式开源空间智能模型日日新 SenseNova-SI-1.3
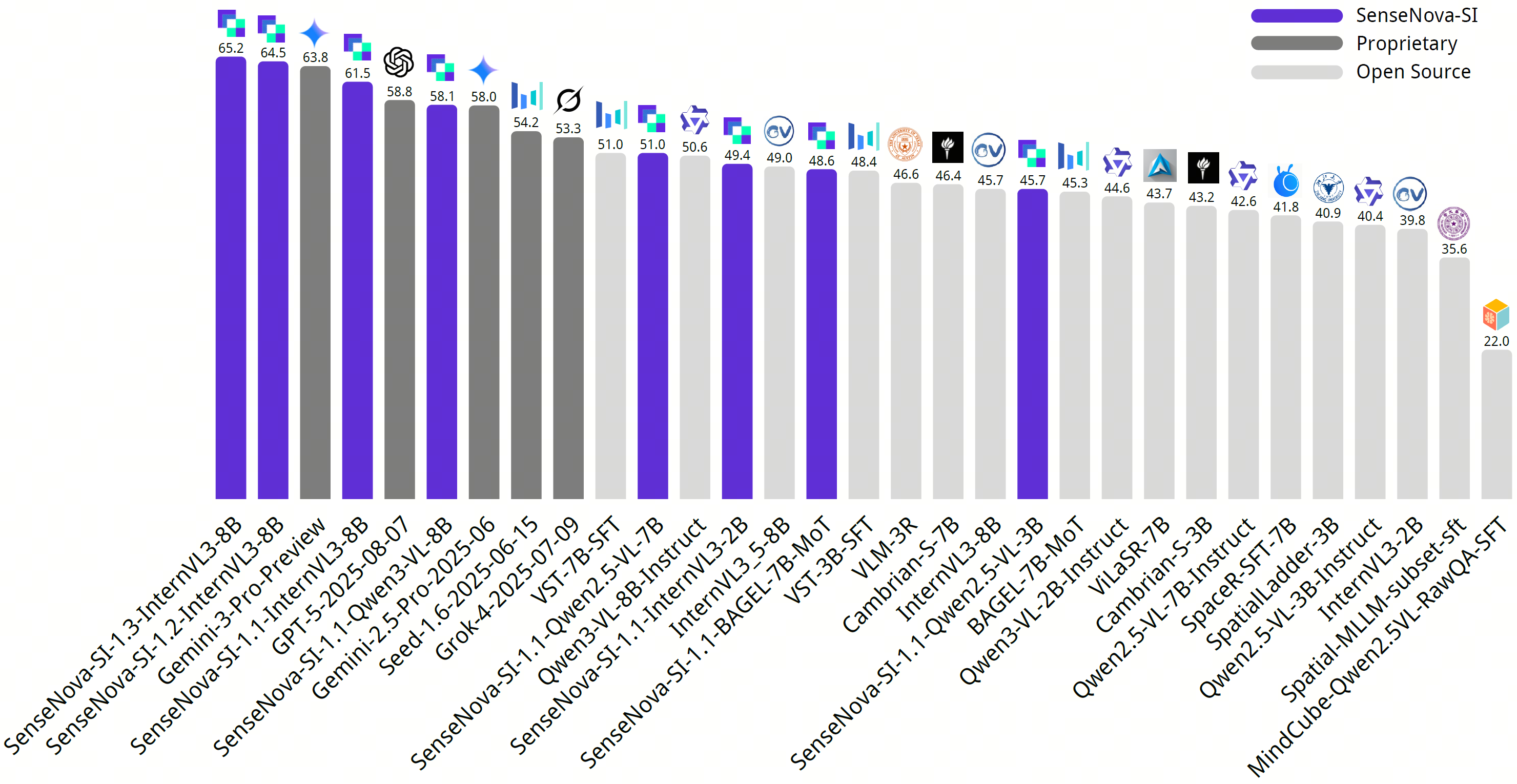
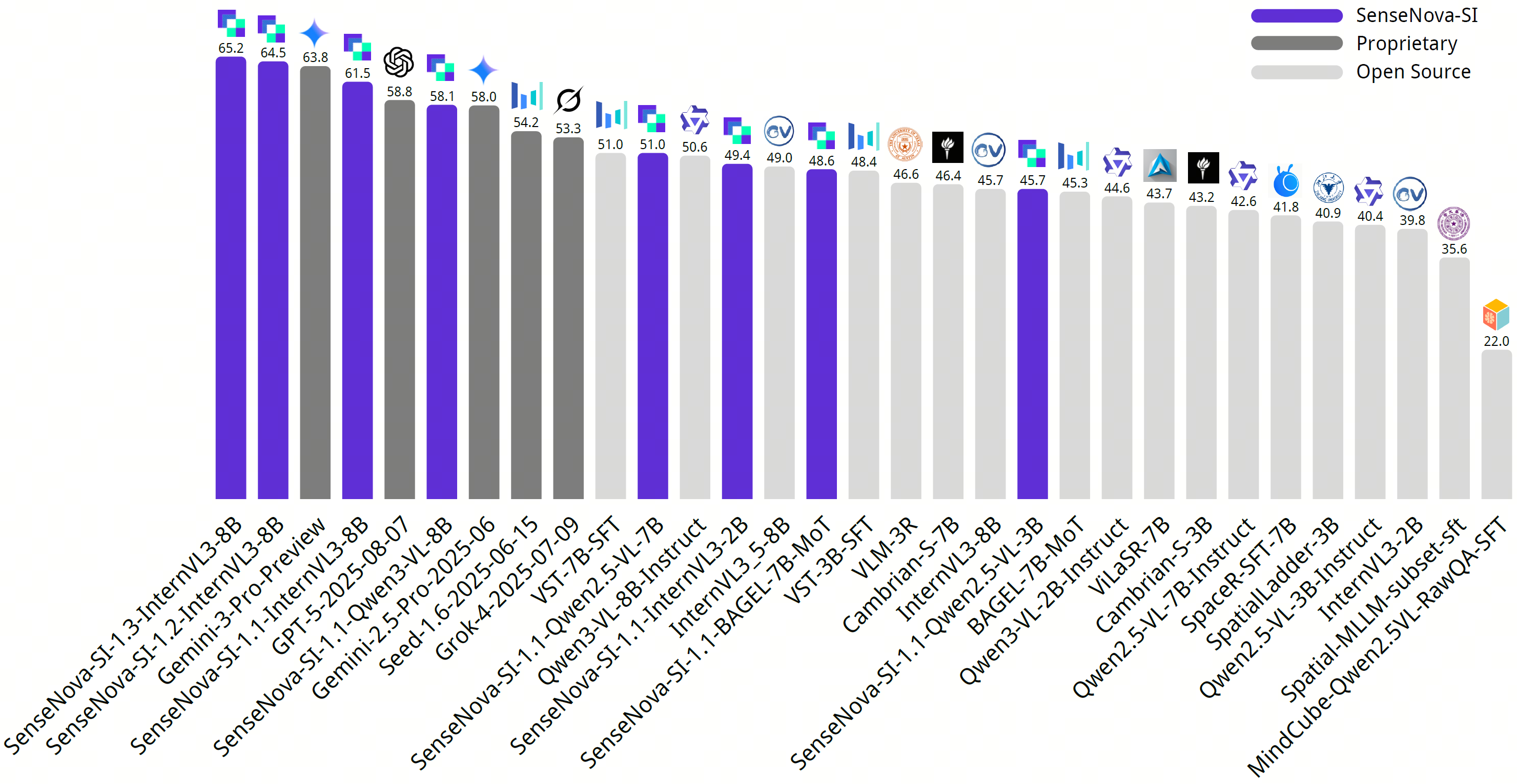
商汤科技正式开源空间智能模型日日新 SenseNova-SI-1.3,在空间测量、视角转换、综合推理等核心任务中展现出显著提升,另外对比之前的版本增强了回答简答题的能力。在集成多项权威空间智能榜单的综合评测平台 EASI 上,SenseNova-SI-1.3 综合性能超越 Gemini-3-Pro,均分斩获 EASI-8(八个权威空间智能榜单的混合评测)标准第一,在多个高难度空间任务(尤其是视角转换)中表现优异。
刁钻考题验证:SenseNova-SI-1.3 精准突破空间智能核心难点
EASI-8 包含一系列专门考察空间理解能力的高难度测试题,让 Gemini-3-Pro 等模型都频频踩坑。那么 SenseNova-SI-1.3 表现如何呢?(下列问题在测试模型时使用的原题为英文,为便于读者理解翻译为中文)。

题目要求统计两张照片中建筑模型的总数量,核心难点是理解两张图的对应关系,以此避免遮挡漏数和重复多数。图 2 视角下显现出图 1 中被遮挡的深灰色建筑,且部分模型在两图中重复出现。Gemini-3-Pro 未完全去重,误数为 6 个;SenseNova-SI-1.3 则给出「4 个」的准确答案。
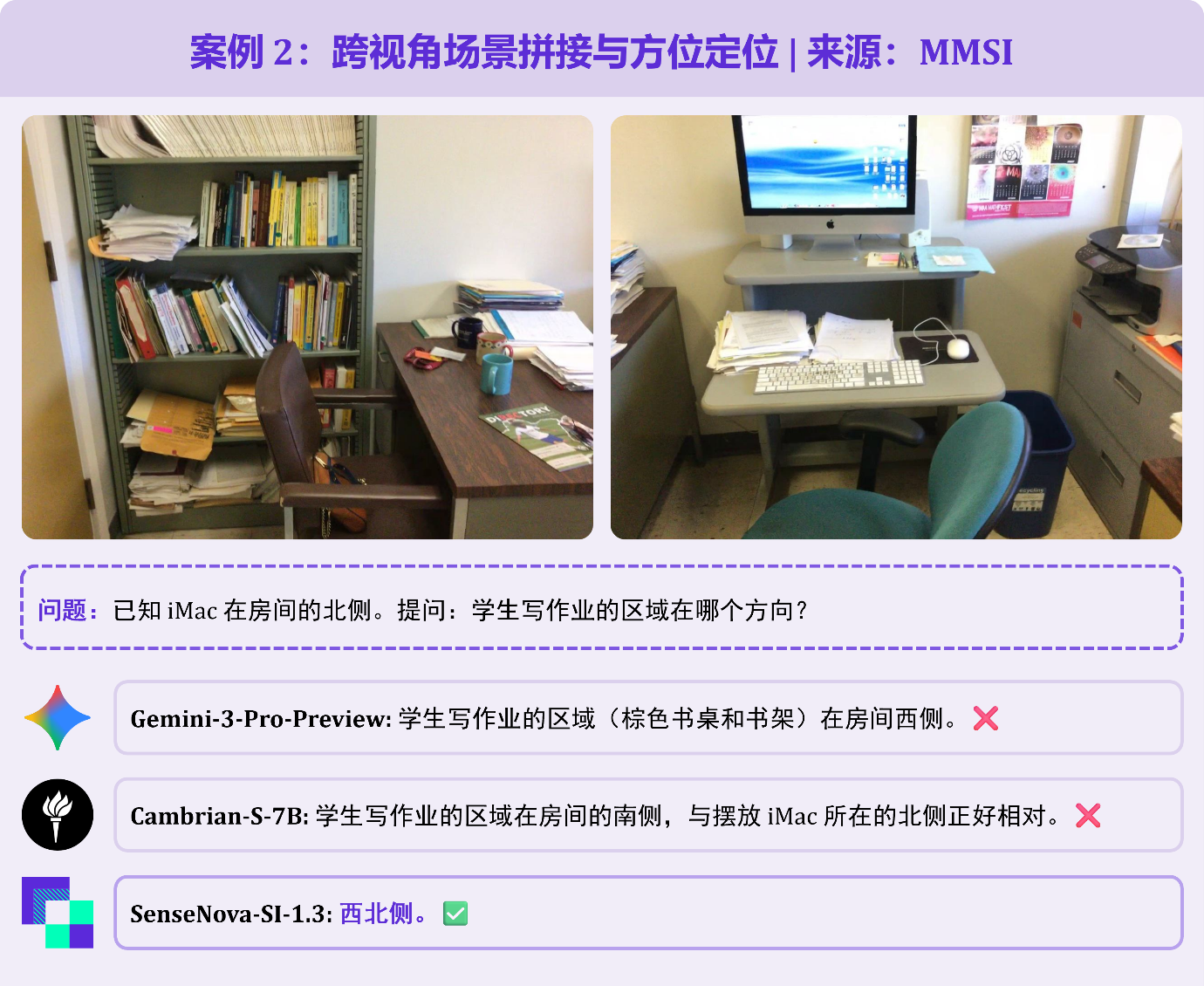
题目给出两张书房局部照片,已知 iMac 位于房间北部,询问学生写作业区域的方位。需先理解两张图片属于同一空间,再通过视觉线索拼接场景。Gemini-3-Pro 误判学习区在西侧;SenseNova-SI-1.3 精准定位「西北角」,完全符合空间逻辑。
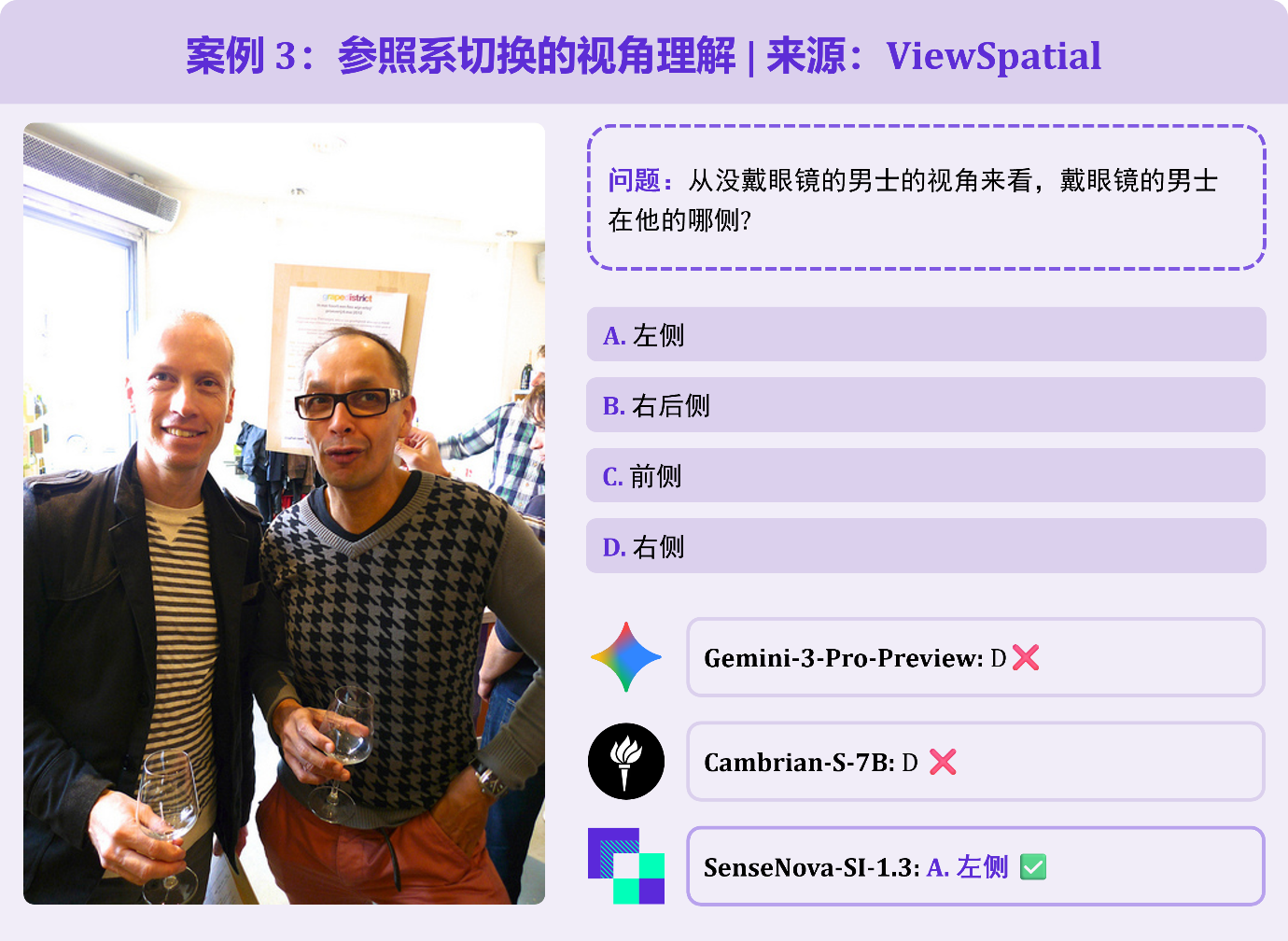
题目要求以「未戴眼镜男士的自身视角」判断身旁戴眼镜男士的方位,考察「参照系转换」能力,模型很容易以「观察者视角」来判断方向。Gemini-3-Pro 就误选了「右边」;SenseNova-SI-1.3 则能正确给出「左边」的正确答案。
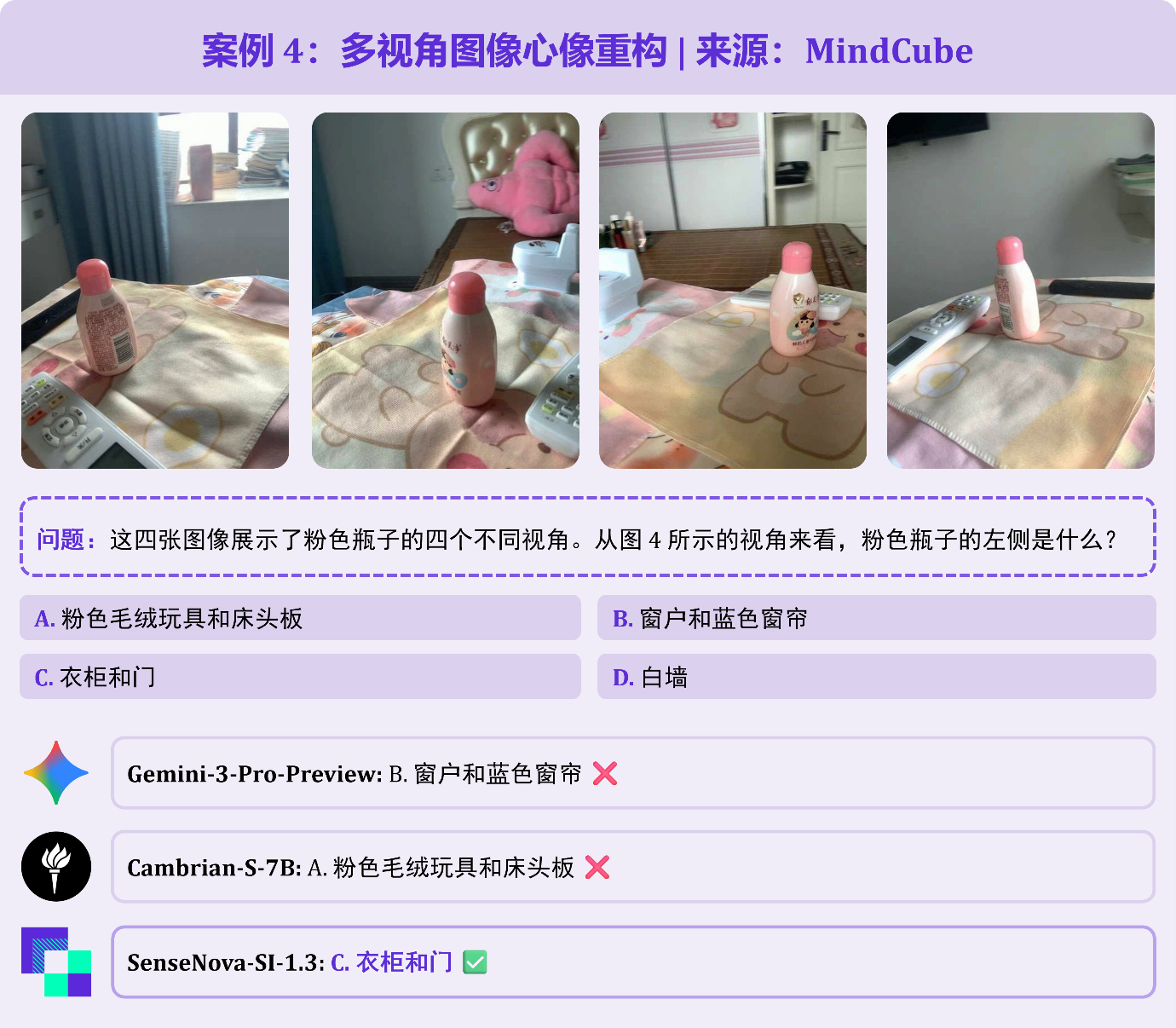
题目给出粉色瓶子前、后、左、右 4 张照片,询问图 4 角度下瓶子左边物体。这道题需整合多视角线索重构房间全局布局,再切换至目标视角判断方位——第 4 张照片中瓶子左侧完全处于视觉盲区,仅能通过前 3 张图中的窗户、床、衣柜等线索还原空间关系。Gemini-3-Pro 误选「窗户和蓝色窗帘」,SenseNova-SI-1.3 精准锁定正确答案「衣柜和门」。

以双层巴士与公交站的场景为题,需避免陷入「英国巴士靠左行驶,因此靠站的是左侧」的常识陷阱,而是通过实际的视觉画面判断方位。Gemini-3-Pro 误判「左侧」为答案;而 SenseNova-SI-1.3 则准确理解「右侧」为正确答案。
空间智能是极其独特的多模态能力
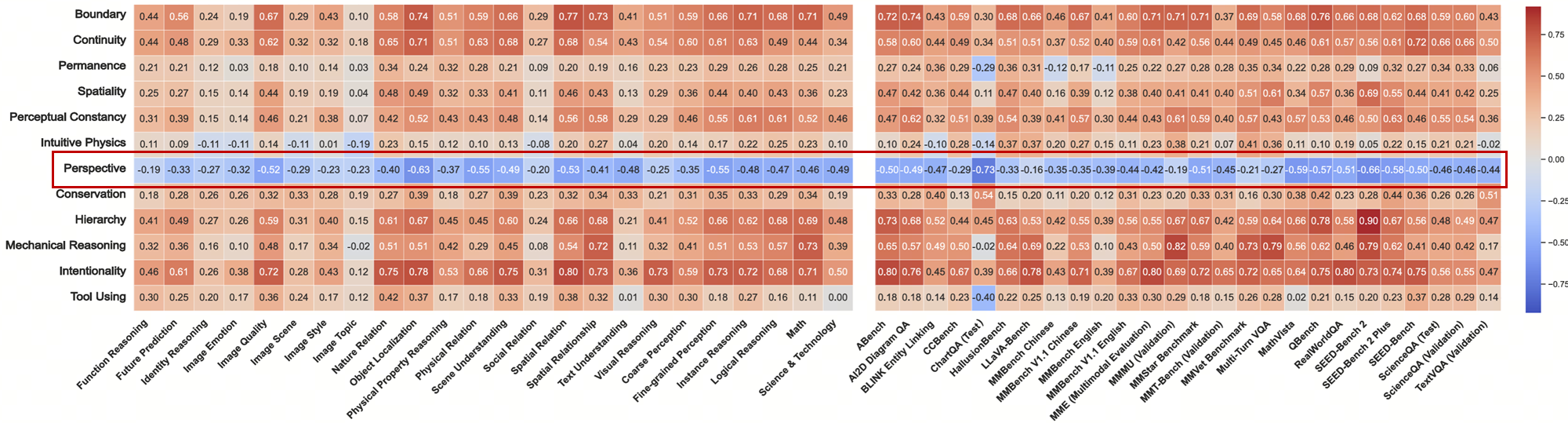
Core Knowledge Deficits in Multi-Modal Language Models (2025) 发现视角转换任务与其它多模态任务的相关性(红框内)呈蓝色,即代表相关性较低
一篇 2025 年发表于机器学习顶会 ICML 的论文《Core Knowledge Deficits in Multi-Modal Language Models》揭示了一个有趣的发现:视角转换(Perspective)和所有传统多模态模型的能力的相关性均异常得低,这代表主流算法路径可能不是空间智能的形成的有效路径,这也解释了为什么领先的多模态大模型在空间智能相关的任务上表现不佳。
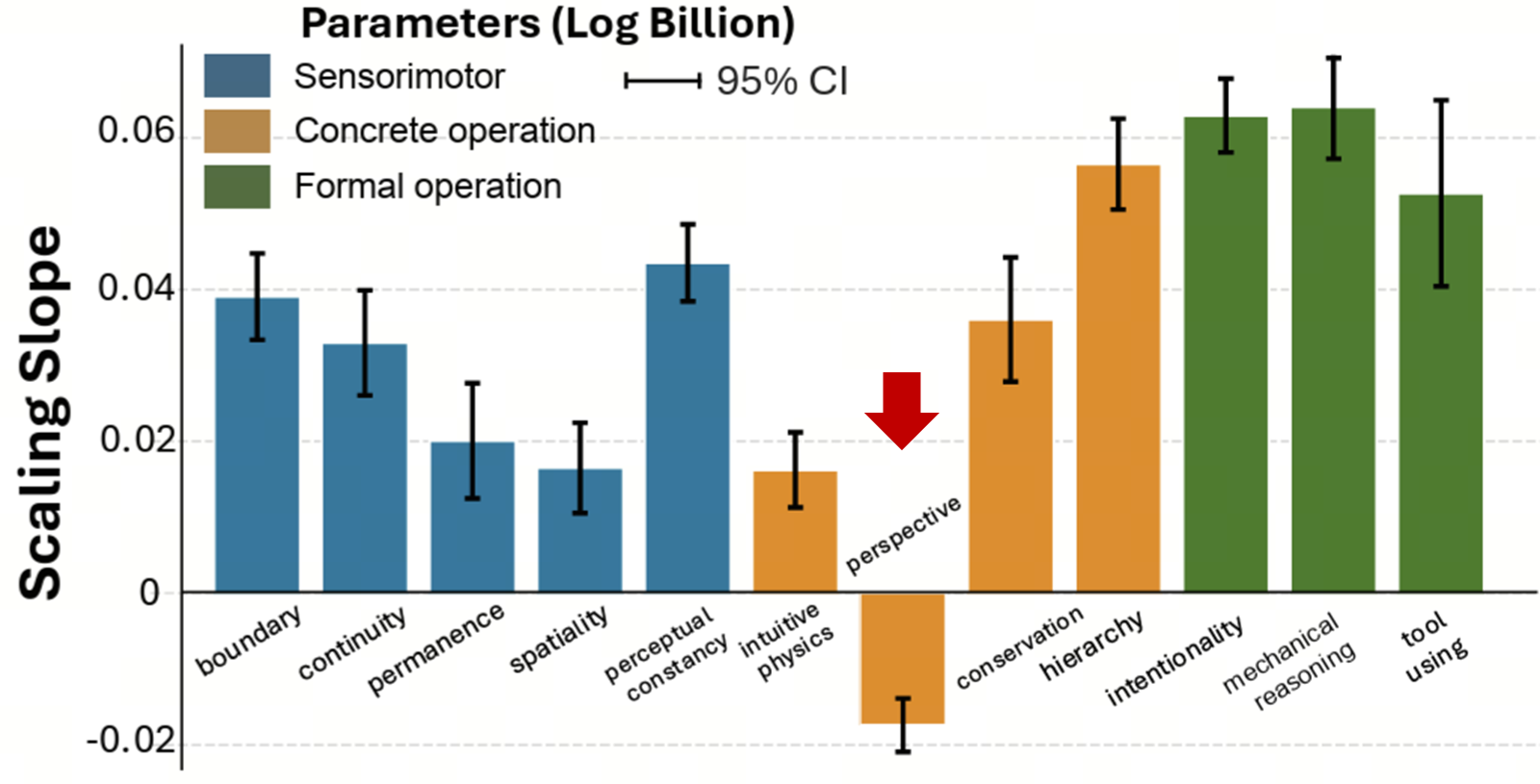
Core Knowledge Deficits in Multi-Modal Language Models (2025) 发现增大模型尺寸对提升视角转换任务效果不佳
这篇论文也发现,空间智能似乎存在反尺度效应的现象:更大的模型并不能更好地解决空间智能任务。另外,在 EASI 的官方报告中也可以找到相似的描述,指出视角转换任务(Perspective-taking)依然是最具挑战的基础能力之一。
空间智能需要全新的学习范式。
从 3D 世界数据匮乏到空间智能的尺度效应

空间智能的核心——视角转换任务被拆解成了三个关键步骤:建立跨视角关联、理解视角移动、想象视角变换,并围绕着解决这三个基础能力构造大量训练数据
学术界现有数据集多着重于目标识别与场景理解,模型往往停留在图像模式匹配阶段,难以形成稳定的空间理解能力。基于这一洞察,想要解决空间智能尤其是视角转换任务,简单扩充相关数据规模是不够的。为了解决这一根本问题,我们将视角转换看作从二维视觉信息迈向三维空间关系理解的关键桥梁,并将其拆解为递进的能力阶段,由易到难、难度递增的三个任务层级(建立跨视角关联、理解视角移动、想象视角变换),并构造大量且层次分明的训练数据,使模型建立完备的空间理解能力。
同时,在数据规模持续扩大的过程中,SenseNova-SI 团队挖掘并重组多视角学术数据资源,将许多过去未被充分利用的标注转化为视角转换训练数据。例如,多目关联数据集 MessyTable 提供了高物体复杂度场景,其中跨视角物体一致性信息与精确的相机位姿标注,可用于训练物体对应与相机运动推理能力;而部分室内场景扫描数据如 CA-1M 中包含物体自身朝向标注的样本,则被用于补充模型进行视角转换与想象所需的稀缺数据。这种跨数据源的重组与再利用,使积累大量丰富而系统的空间理解数据成为可能。
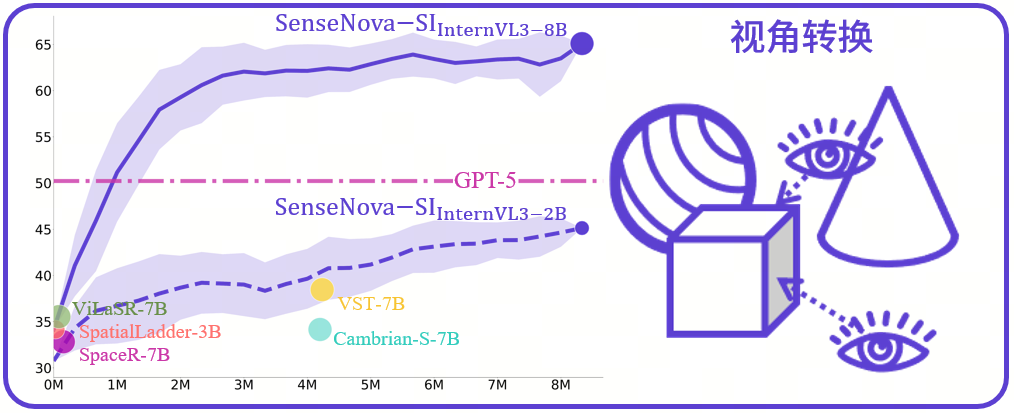
空间智能的尺度效应:SenseNova-SI 在视角转换任务上超越 GPT-5
大规模高质量的空间智能数据在 SenseNova-SI 团队的手中最终验证了空间智能的尺度效应:SenseNova-SI 的 8B 参数基模型最终超越了强闭源模型如 GPT-5,而 2B 参数的小模型也表现不俗,在相同数据规模下,甚至超越了纽约大学的 Cambrian-S 和字节的 VST 两个 7B 参数的模型。
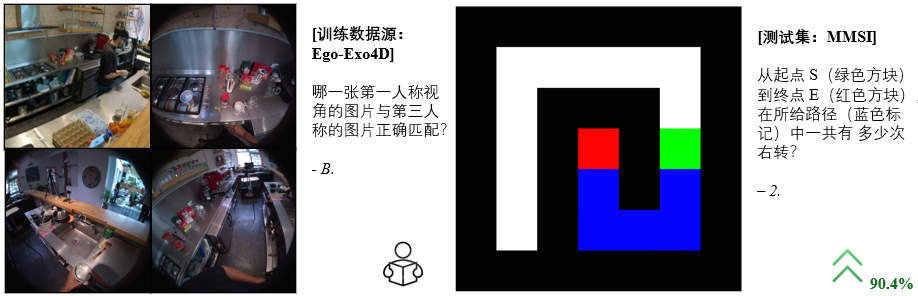
只在 Ego-Exo4D 上训练第一/第三人称视角匹配的模型可以大幅提升 (+90.4%) 在 MMSI 的 2D 迷宫导航问题上的表现
更有趣的是,团队在研究中似乎发现了一些智能涌现的先兆:一些看起来毫无关联的但也许细想之下有底层能力联系的任务可以协同发展。另外,团队也发现在视角转换任务上训练的模型也可以增强如心智重建(Mental Reconstruction)、综合空间推理(Comprehensive Reasoning)等能力。
商汤引领空间智能普惠生态
SenseNova-SI-1.3 模型的升级发布背后,是商汤科技始终致力于打破技术壁垒,让顶尖空间智能技术惠及更多开发者与企业。对科研人员而言,SenseNova-SI-1.3 通过在空间智能上验证数据尺度效应提供了一个与现有基座模型完全兼容,但又长于空间智能的强力预训练模型和基线(SenseNova-SI 已被 VSI-Bench, MMSI-Bench 等权威榜单官方收录),可以直接在其之上设计创新算法或者续训,推动空间智能向人类水平迈进;对企业来说,可直接基于 SenseNova-SI-1.3 快速落地应用,缩短研发周期、降低技术门槛;对普通用户而言,未来将有更多搭载先进空间智能的产品走进生活——从智能家电到自动驾驶,从工业机器人到教育设备,都将更懂「空间逻辑」、更贴合实际需求。
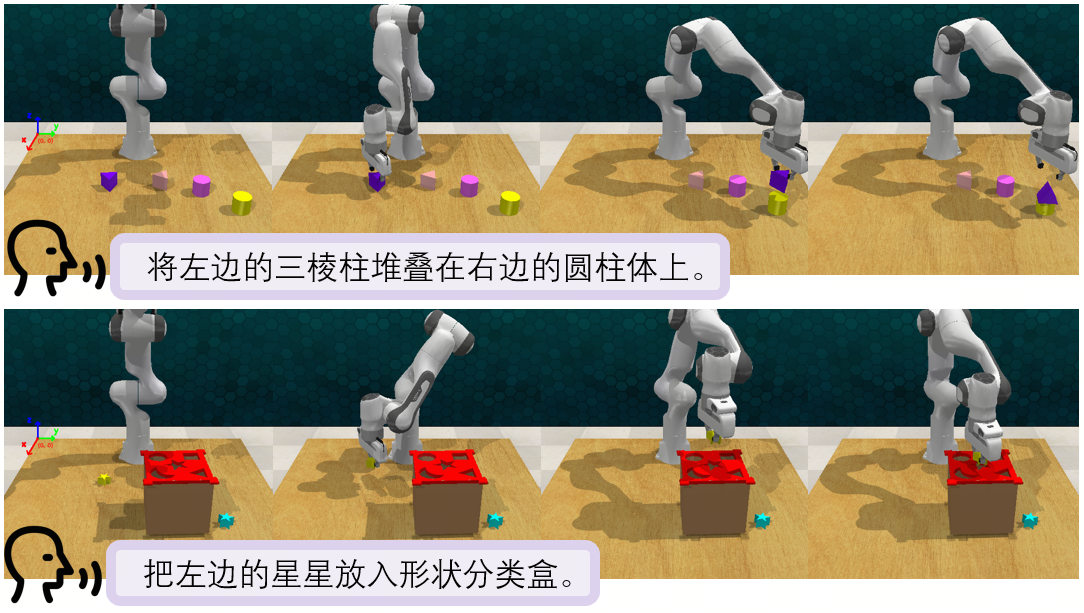
SenseNova-SI 在具身任务上的探索了空间智能的重要性
开源地址
SenseNova-SI 模型家族:https://huggingface.co/collections/sensenova/sensenova-si
SenseNova-SI 开源代码:https://github.com/OpenSenseNova/SenseNova-SI
Discord 社区邀请码:https://discord.gg/WBzH62bk
SenseNova-SI 入群码:



