

一觉醒来,OpenClaw 彻底火了。
一觉醒来,OpenClaw 彻底火了。

何为 OpenClaw?简单来说,OpenClaw 是一个代理式 AI 开源框架,它让 AI 不再局限于被动应答,而是能主动规划、调用工具、串联多步操作——就像一个数字世界的「全能助理」。
它能自动整理会议纪要、同步跨平台日程、比价下单并生成报销凭证,甚至在检测到你连续加班时,悄悄预约按摩师上门。
截止目前,其在 github 上的 star 数已经达到 14.3 万,每天都在以近万的速度在增长。OpenClaw 创始人 Peter Steinberger 开玩笑的称之为:不是曲棍球式增长,而是「脱衣舞」式增长。
更有意思的是,还有人专门建了一个 Agent 社交平 Moltbook,目前已经有 150 万 agent 在上面互动和发帖,而人类用户没有任何发言权限,只能围观,围观人数达到了惊人的 100 万。

但当这个「全能助理」开始接管你的数字生活,恐慌也随之而来。
毕竟,它所调用的每项权限、连接的每个 API、安装的每个插件,都可能成为黑客撬开你数字边界的支点。如果它误删了核心数据?如果它被一句话诱导「黑化」了?传统「打补丁」的安全思维,在自主决策的智能体面前会瞬间失效。
也就是说,你的 AI 助手,可能正以你无法察觉的方式,在互联网上「裸奔」。
同样,我们也应该看到,这个现象级的开源 Agent 给云厂商们也带来了一些产业机会。
其一,OpenClaw 的爆火让全民尝鲜 Agent 成为趋势,但本地部署不仅需要承担 Mac Mini 这类硬件的采购成本,更面临着权限隔离、数据安全的核心难题,而安全稳定的云端专属算力、标准化一键部署能力,以及 7×24 小时不间断的运行支撑,成为个人开发者与中小主体入局的最低门槛,也让云端算力成为 Agent 落地的核心载体;
其二,Token 消费将迈入指数级增长阶段,Agent 的自主规划、多步工具调用、长期上下文记忆特性,再加上 7×24 小时常驻运行的需求,让 Token 消耗从传统问答式的零散消耗,变成规模化、持续性的巨量消耗,而 Agent 部署时对 Token 厂商的指定属性,更让 Token 成为算力消费的核心「通用货币」。数据显示,2024 年初中国日均 Token 消耗量为 1000 亿,截至今年 6 月底,日均 Token 消耗量已突破 30 万亿,一年半的时间增长 300 多倍。而 OpenClaw 的爆火则意味着更大的 Token 消耗量。
其三,Agent 的使用特性决定了一次部署即锁定运行阵地,用户后续仅需通过聊天工具交互,几乎不会产生二次切换平台的行为,谁能占据 Agent 的部署入口,谁就能锁定后续持续的 Token 消费与算力调用需求,成为 Agent 时代的核心玩家。
但算力需求的爆发绝非昙花一现,而是随 Agent 生态的成熟持续走高,形成「短期推理算力吃紧,长期训练算力刚需」的双重算力机会。短期来看,OpenClaw 这类 Agent 的 7×24 小时常驻、多步调用、长上下文记忆特性,叠加全民部署潮,让 Token 消耗成规模化、常态化刚需,直接引爆推理侧算力的指数级增长,尤其高并发、低时延的定制化推理算力需求激增;长期而言,模型厂商为争夺用户,会围绕 Agent 场景持续迭代优化效果,从场景化微调到大模型核心能力升级,都需要海量算力支撑,训练侧算力将成为算力市场长期核心增量。
而对于广大企业尤其是 中小企业来说,这种持续走高、兼具短期爆发与长期刚需的算力需求,靠传统本地部署模式根本无力承接——既要承担硬件采购的『高位接盘』成本,又要应对算力弹性不足的效率损耗,还得直面 Agent 自主运行带来的安全风险。因此,企业上云已不仅是技术选择,更是生存刚需。
近期,在华为云面向中国区合作伙伴召开的发布会上,华为云不仅对 Flexus 云服务器系列规格及性能进行了更新,展示了其在各种业务负载下的运行表现,同时发布了专为中小企业客户打造的 Flexus AI 智能体。该智能体深度融合华为云 Token 服务,支持按需调用百模生态中的任意大模型,算力资源秒级弹性伸缩;企业只需为实际消耗的 Token 付费,无需预购 GPU 实例或预留容量,真正实现「用多少、付多少」。真正为中小企业破解「存储成本-AI 算力-安全防护」三角困局提供了关键路径。
本文就针对华为云 Token 服务的弹性计费机制、百模生态接入能力与安全隔离架构展开评测。
Token 化为什么重要?
在正式开始评测前,我们首先需要搞明白 Token 究竟是什么?在 AI 浪潮下,Token 将发挥怎样的作用?
简单来说,Token 是将文本分割转换成数字向量,大模型吞吐内容的规模以 Tokens 计算,它是大模型时代天然的计量单位。用 Tokens 作为计费单位也逐渐成为行业共识:一方面,能更精准计算企业使用的资源,让用户仅为实际消耗付费,同时通过实际消耗了解费用构成,进一步优化成本;另一方面,可解决不同场景 Tokens 消耗量差距大导致的收费不公问题,为云厂商动态调节计算资源提供参考。
此外,Token 服务可以有效屏蔽复杂的底层技术实现,用户不必关心芯片的工艺、服务器的代次等复杂的硬件技术栈,也不必关心推理框架、模型部署等复杂的软件技术栈,可以高效地直接获得「AI 的最终结果」。
就当下而言,Token 用量的多少已经成为衡量一家 AI 公司价值的重要标尺。而华为云 AI Token 服务正是在此背景下推出的创新实践,其底层依托昇腾 AI 集群与盘古大模型优化引擎,封装成按 Token 计费的标准化 API 接口,让大模型像水电一样按量付费,随处调用。
实测体验:5 分钟上手,中小企业也能玩转的 AI Token 服务
作为面向中小企业的云服务,「低门槛」是核心诉求。我们从注册、选型、调用三个环节实测华为云 AI Token 服务,验证其是否真正适配中小企业的技术能力与成本预算。
1. 上手门槛:零技术壁垒,5 分钟搞定模型调用
首先在注册与接入阶段,我们只需访问华为云 AI Token 服务官网
支持企业/个人账号一键注册,注册后无需复杂配置,控制台提供可视化操作界面与 API 文档,开发者无需深入理解底层算力架构。
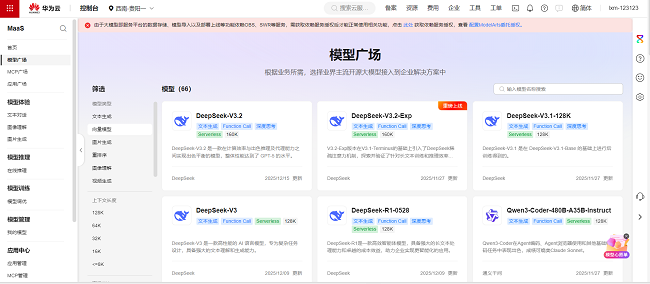
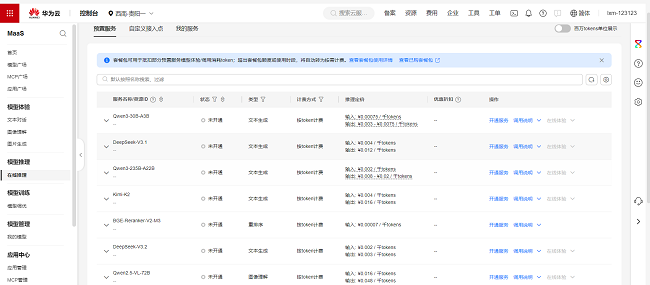
在控制台的模型广场,可一键选择你想用的模型,如 DeepSeek、Qwen、GLM 等主流开源与闭源大模型,无需下载 SDK 或编写复杂代码,点击推理调用或在线体验即可实时发起对话。
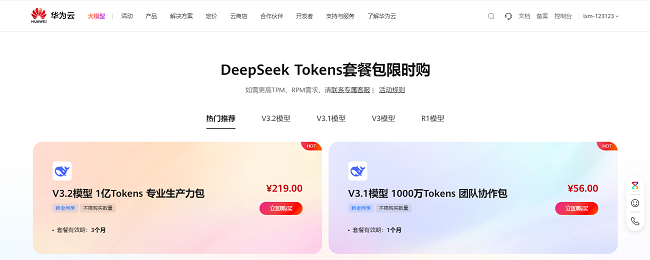
在套餐选择上,提供按月、按季度等多种灵活计费方式,并区分了不同的付费档位,从百元级起步,满足初创团队轻量试用需求;千元级档位则覆盖中小企业的常规业务负载。更贴心的是,系统自动按实际 Token 消耗实时扣费,账单明细精确到每一轮对话的输入输出量,杜绝隐性成本。对于预算敏感的中小企业团队,还可设置用量预警与自动停用阈值,真正实现「花多少、算多少、控得住」。
2. 成本优势:按 Token 计费,告别算力浪费
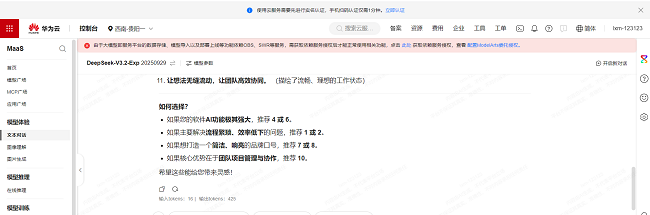
以调用 DeepSeek-V3.2-EXP 模型生成产品文案为例,输入「为智能办公软件撰写一句吸睛的 Slogan」,模型仅耗时 1.2 秒便输出「把时间还给创造,琐事交给 AI」等 11 个 Slogan 建议,全程消耗 Token 441 个(含输入输出 Token);控制台实时刷新调用状态,让每一次 AI 决策都清晰可溯、成本可控。
核心能力拆解:超节点算力+全栈生态,撑起中小企业 AI 落地
当然,中小企业选择云服务,不仅看成本,更看性能与稳定性。华为云 AI Token 服务依托 CloudMatrix 384 超节点与全栈自研技术,在性能、生态、安全三方面构建起差异化优势,满足中小企业从「能用」到「好用」的需求。
1. 性能硬实力:超节点加持,快且稳的算力支撑
2025 年 9 月,华为云 AI Token 服务全面接入 CloudMatrix 384 超节点,通过 xDeepServe 分布式推理框架重构算力调度逻辑。
在硬件底座方面,CloudMatrix 384 超节点通过 MatrixLink 高速对等互联网络,将 384 颗昇腾 NPU 与 192 颗鲲鹏 CPU 耦合为「超级 AI 服务器」,单芯片最高实现 2400 TPS 吞吐量、50ms TPOT 时延。

CANN 昇腾硬件使能,优化算子与高效通信策略,让云端的算力能够以最高效的方式被调用和组合;EMS 弹性内存存储打破 AI 内存墙,突破性地实现「以存强算」,彻底释放了每一颗芯片的算力。这一整套技术栈协同发力,使中小企业在调用大模型时,既享受毫秒级响应,又规避了资源争抢与调度抖动。
2. 生态全覆盖:百模任选+伙伴方案,无需多平台切换
中小企业技术团队规模有限,难以应对多平台、多模型的集成工作。华为云 AI Token 服务通过「MaaS 平台+伙伴协同」模式,提供全场景覆盖的 AI 生态——目前,华为云 MaaS 服务已支持 DeepSeek、Kimi、Qwen、Pangu、SDXL、Wan 等主流大模型及 versatile、Dify、扣子等主流 Agent 平台。
并且积累了大量模型性能优化、效果调优的技术和能力,从而实现「源于开源,高于开源」,让更多大模型可以在昇腾云上跑得更快更好。以文生图大模型来说,在轻微损失画质的情况下,通过 Int8 量化、旋转位置编码融合算子等方式,在华为云 MaaS 平台实现了 2 倍于业界主流平台的出图速度,最大尺寸支持 2K×2K。而在文生视频大模型上,不仅通过量化方式来提速,还通过通算并行等方式,降低延迟与显存占用,大幅提升视频生成速度,相较于友商实现了 3.5 倍的性能提升。华为云 Tokens 服务在性能、模型适配、效果调优方面的基础,也让更多企业能够快速开发和构建 AI Agent。
本质意义上来说,这不仅是算力的跃迁,更是 AI 生产力范式的重构——当技术底座足够坚实,中小企业便得以从繁琐的基础设施运维中抽身,将全部心力聚焦于业务逻辑与用户价值的精耕细作。
3. 安全合规:数据安全不越界,满足中小企业合规需求
中小企业对数据安全与合规性要求极为严苛,因此,华为云 AI Token 服务不做数据变现业务,不用客户数据训练模型,不做流量应用。

以近期爆火的 OpenClaw 开源项目为例,华为云通过主机安全(HSS)实现工作负载的深度防护与微隔离,守住「绝对隔离」的底线;利用云防火墙(CFW)精细管控网络流量,轻松实现「网络隐身」,避免控制端口暴露;借助密码管理(DEW)的密钥管理与凭据自动轮转能力,确保访问安全无虞;同时,安全云脑可整合全局安全态势,并快速编排响应各类安全威胁。
目前,OpenClaw 已在华为云 Flexus L 实例云服务器、云商店(KooGallery)以及 Solution as Code 解决方案三种方式完成一键部署。
但归根结底,脱离场景的技术毫无价值。根据目前披露的官方信息,在应用层,华为云已与超过 100 家伙伴携手深入行业场景,共建丰富的 Agent,在调研分析、内容创作、智慧办公、智能运维等领域解决产业难题,让企业更便捷地拥抱 AI 创新,加速智能化。
如基于 MaaS 平台推出的今日人才数智员工解决方案,集成了先进的自然语言处理、机器学习和深度学习技术,能实现与用户的智能交互和任务处理,显著提升服务效率与客户满意度;而北京方寸无忧科技开发的无忧智慧公文解决方案可以提升公文处理效能,实现政企办公智能化转型。
当 Agent 浪潮撞上存储涨价周期:中小企业上云正当时
当 Agent 浪潮的算力需求撞上存储涨价的成本压力,中小企业 正站在「要么被硬件成本压垮,要么借云服务接住 AI 红利」的岔路口。而华为云 AI Token 服务,恰好为这道选择题给出了最优解。
一方面,存储成本持续攀升,传统本地部署模式已难以承受,且根据行业分析师的普遍预测,本次存储涨价周期将持续至 2027 年,中小企业每拖延一天,就需多承担一天的硬件涨价成本。而根据市场变化制定应对策略,华为云率先走出了弹性按需付费的存储服务模式,让中小企业客户只需为实际使用的存储空间和流量付费。
另一方面,AI 时代,新的竞争变量涌现,存储厂商正从过去的买芯片转向嵌入 AI 计算体系,与 AI 芯片厂商间的绑定越发紧密,这对存储厂商们的产品组合和交付能力都提出了更高的要求。华为云 AI Token 服务的价值,在于通过云原生技术重构算力供给模式,为中小企业提供「按需取用、按用付费」的解决方案。它让中小企业告别前期重投入,转而以轻量、弹性、高性价比的方式接入 AI 能力。
因此,对中小企业而言,选择华为云 AI Token 服务,不仅是应对当前存储涨价的权宜之计,更是提前抢占 AI 时代算力制高点的战略选择。
现在,就是中小企业上云的最佳时刻。
来源:互联网


