
美的 AI 研究院 联合南京大学、北京大学、QuantaAlpha 等多个团队,提出了 Controlled Self‑Evolution(CSE):一个面向算法代码优化的「可控自进化」框架。
这两年,大模型写代码的能力突飞猛进:需求描述一给,程序就出来了。
但在真实业务里,很多团队很快会遇到另一个更「现实」的问题:代码「写得对」只是及格,真正上线拼的是——跑得快不快、占内存多不多、成本高不高。
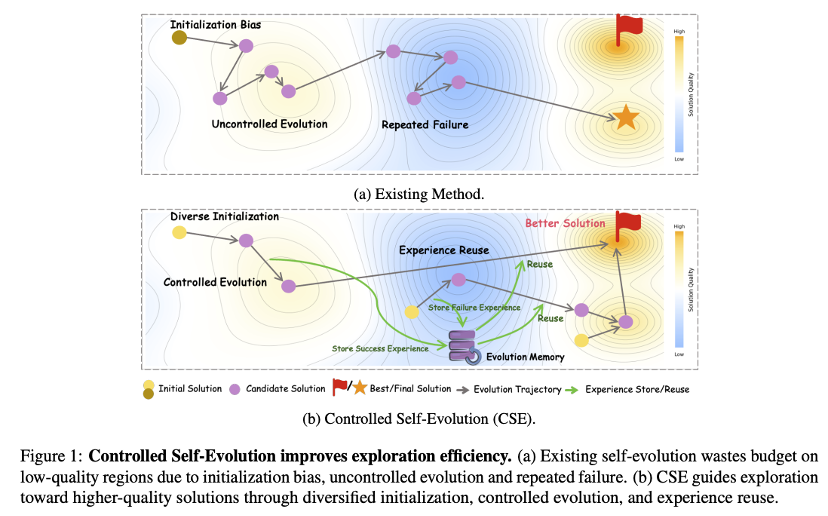
于是大家开始用「自进化」思路:让模型一次次生成候选解、跑测试、挑更好的,再继续改。比如 Google DeepMind 的 AlphaEvolve 论文,就是采用了一种自进化的 LLM 优化算法,这听上去很合理,但实际经常卡在三件事上:
1.起步就跑偏(初始化偏置):第一批候选解质量不高、还很像,预算很快被「无效版本」消耗掉。
2.越改越随机(不可控进化):随机变异、随机拼接缺少反馈引导,方向不稳定,容易「改崩逻辑」。
3.反复踩坑(经验难沉淀):没有可复用的「经验账本」,跨轮次、跨任务重复试错,长期低效。
近日,美的 AI 研究院 联合南京大学、北京大学、QuantaAlpha 等多个团队,提出了 Controlled Self‑Evolution(CSE):一个面向算法代码优化的「可控自进化」框架。
在 EffiBench-X 上评估生成代码的时间复杂度与空间复杂度,CSE 在多种开源与闭源模型上均取得了优于 Google DeepMind 的 AlphaEvolve 等基线的表现:CSE 不仅起步即拉开差距,更能通过持续进化实现代码性能的稳定跃升,展现出极高的预算利用率与可控进化能力。
它要做的事情很直接:
|
让代码执行轨迹的自我进化不再靠「碰运气」,而是每一步怎么改、改哪里、改完有没有变好,都可控、可追溯、可复用——有路线规划、有实时反馈、有经验复盘。 |
CSE 用「三件套」构建了高效闭环:
多样化规划初始化 + 可控遗传进化 + 分层进化记忆,把「生成—验证—进化」连成一条更稳的流水线。

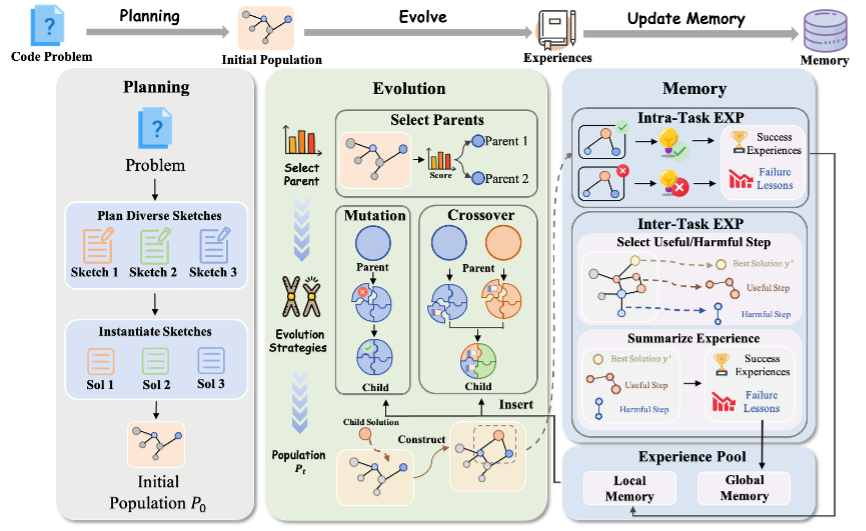
CSE方法:别靠运气,让进化「可控、可追溯、可复用」
传统的代码自进化大多是「生成—跑测试—选更好—再生成」的循环,问题在于:起步容易同质化、迭代容易随机化、经验容易蒸发。CSE 把这条循环改造成一条「可规划、可控、可复盘」的路线,核心由三部分组成:
1)多样化规划初始化:先把路规划出来
在写第一版代码前,先让模型给出多条差异明显的解题路线(不同思路、不同数据结构),再分别生成初始版本。目的不是「一上来就最强」,而是别所有人都挤在同一条路上。
2)遗传进化:只改该改的地方
进入进化阶段后,CSE 会优先选择表现更好的候选作为「父代」,但也会保留一部分有潜力的思路,避免过早陷入局部最优。
更关键的是:它把「突变」从随手乱改升级为可控改动——先把代码拆成若干相对独立的功能块,再让模型复盘定位瓶颈/故障点,只对问题区域做小范围修复,其它区域尽量冻结不动,从而降低「优化性能却把正确性改崩」的风险;同时,CSE 也支持把不同候选的优点进行结构化组合,把一段更快的逻辑和另一段更稳的边界处理「嫁接」到一起。
3)分层进化记忆:把每次试错变成可复用资产
很多进化方法的低效,来自「同样的坑反复踩」。CSE 把每轮迭代的结果做成两层记忆:任务内记忆记录「这一次改动为什么有效/为什么失败」,用于当前任务快速收敛;任务间记忆则把高价值的改进轨迹抽象成模板,在新任务里通过检索直接调用,相当于给系统配了一本会增长的「优化笔记」。
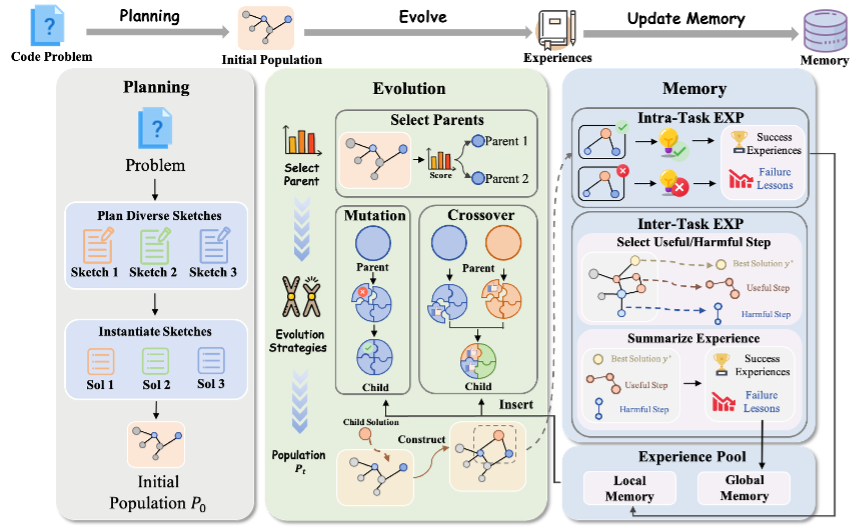
图 2. CSE 框架概览
实验评估:在623道算法题上验证,预算更省、效果更稳
为了验证 CSE 的有效性,团队在 EffiBench‑X 上进行了大规模评测:该基准包含 623道来自 LeetCode、Codeforces 等平台的复杂算法题,覆盖 Python 与 C++,重点看「时间 + 内存」的综合效率指标(MI)。
实验设定也很贴近真实成本约束:
每个任务统一预算 30 个候选解,并与 AlphaEvolve、SE‑Agent 等方法对比。
•开源模型:基于 DeepSeek‑V3,CSE 的综合效率指标 MI 提升到 55.09%,优于 AlphaEvolve 的 52.13%。
•强模型上仍有效:在 GPT‑5、Claude‑4.5‑Sonnet 等模型上,CSE 依然能进一步提升,体现出方法的普适性。
•迭代更稳、优势更早建立(图3):随着进化轮数增加,CSE 的 Best MI 持续上升且全程领先对比方法,体现出在同等预算下更稳定可控的优化收益。
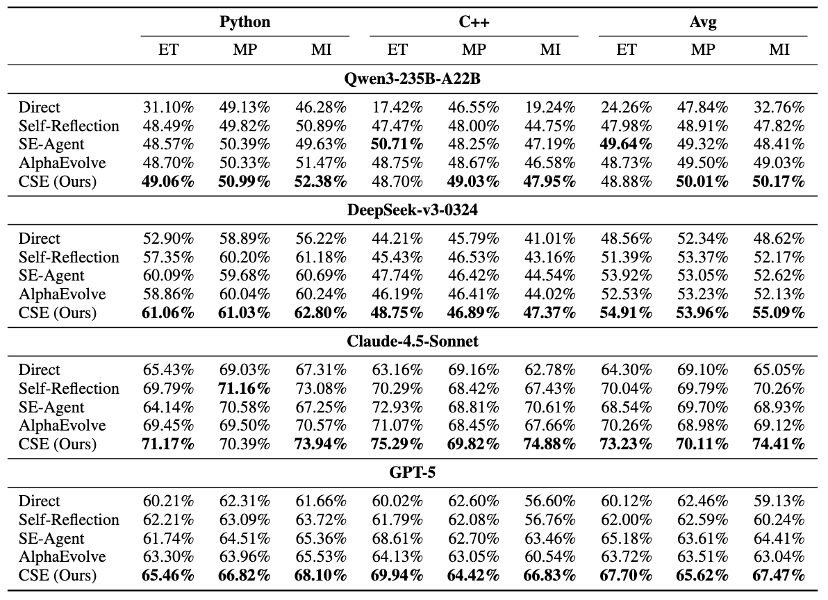
表 1. 在 EffiBench-X (Python, C++) 上的主实验结果
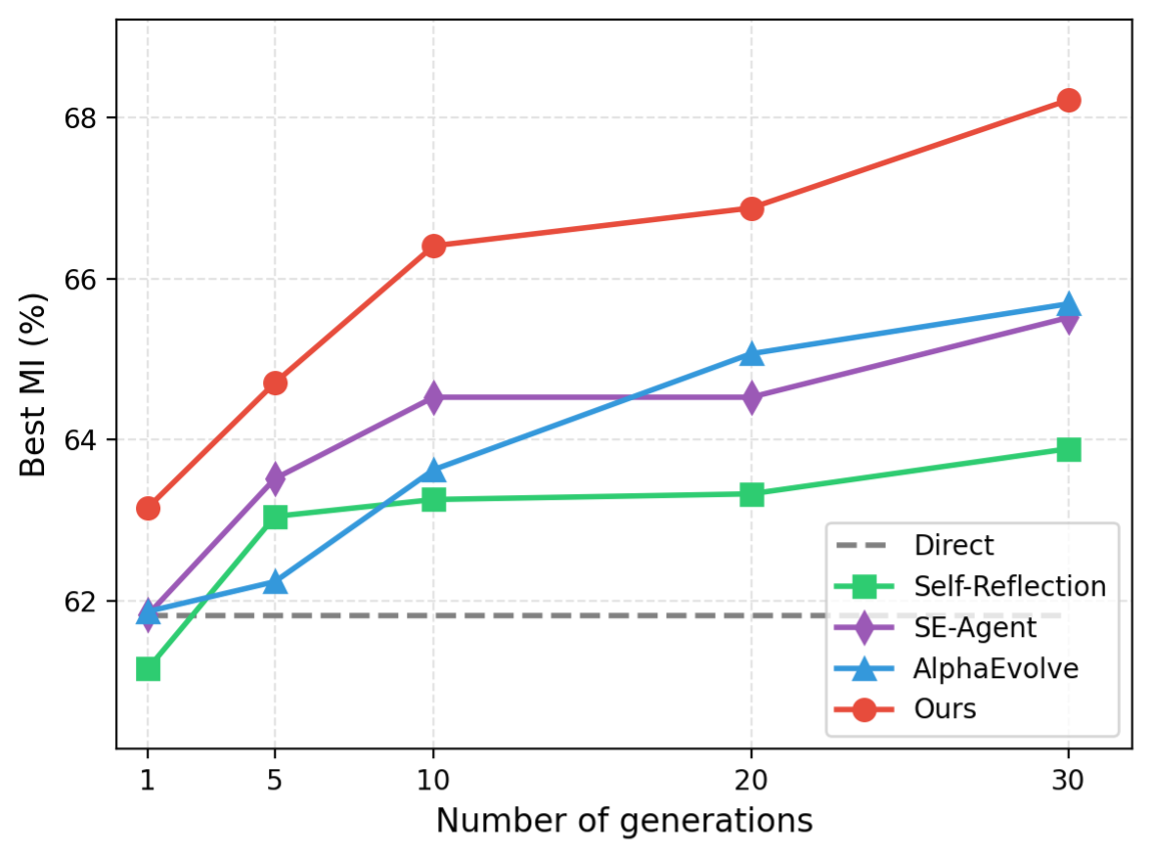
图 3. 最佳 MI 指标随迭代轮次的攀升趋势
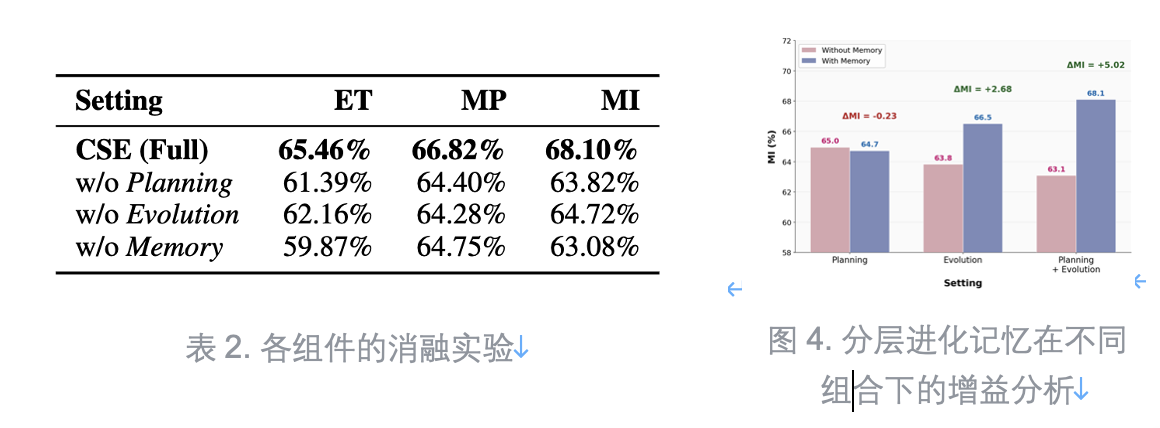
消融实验:为什么说「三件套缺一不可」?
团队还做了消融实验,结论很清晰:
去掉分层记忆,性能下降最大——MI 从 68.10% 降到 63.08%,说明「经验复用」是打破重复踩坑的关键。
更有意思的是「协同效应」:
如果只有「规划阶段引入记忆」但没有完整进化过程,性能甚至会下降(‑0.23%);而把记忆接入「规划+进化」的完整闭环后,增益可达 +5.02%。这也印证了:CSE的价值在闭环,而不是单点技巧。
案例一瞥:代码真的会「越进化越像老工程师」
团队展示了一个任务的完整 30 轮进化轨迹:从早期预计算策略,到中期搜索结构重构,再到后期针对瓶颈的精准修复与逻辑交叉,最终生成的方案在设计与实现上都达到了非常高的效率水平。
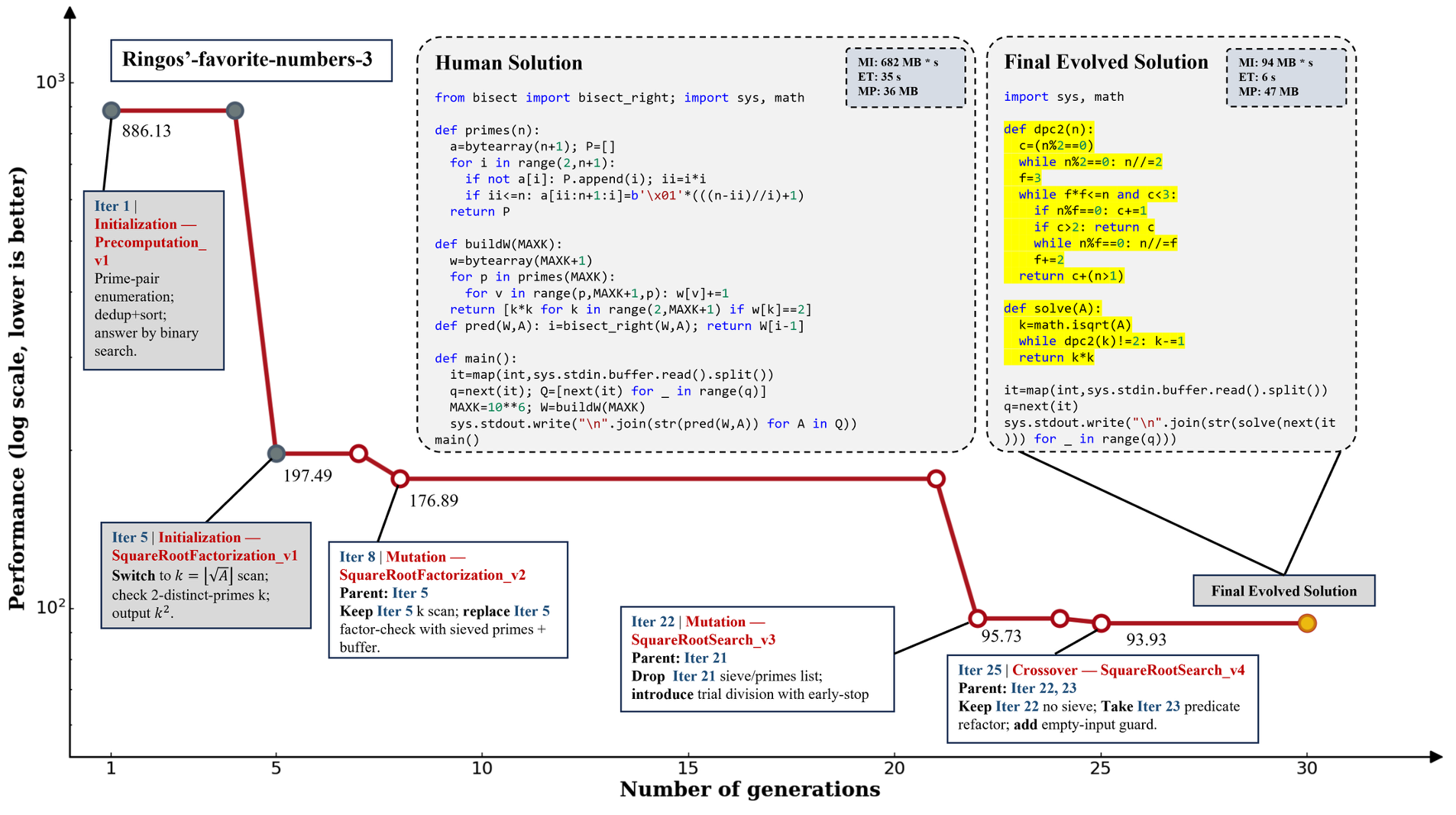
图 5. 算法进化轨迹的全流程案例研究
结语:下一步,让「进化成本」沉淀进模型本身
CSE 证明了:在预算受限的真实条件下,多轮进化依然能持续提升代码效率。
而未来更值得期待的方向,是把进化过程产生的高质量轨迹进行知识蒸馏,让基础模型逐步具备更强的「内生优化能力」,最终实现更接近 One‑pass 的高效代码生成,在推理成本与生成质量之间取得更优的平衡。
|
Plain Text 论文标题:Controlled Self‑Evolution for Algorithmic Code Optimization |


