

穿皮衣的他,还是那么自信。
作者|芯芯
编辑| 靖宇
英伟达这家公司,正在经历一种很矛盾的时刻。它看起来像所有泡沫叙事里最危险的那一个,毕竟市值已经冲到史无前例的高度,股价每一次波动都能牵动市场。但它又同时像所有 AI 概念股里最强的那一个,一个季度营收、净利润数百亿美元,毛利率能达到 70%。
这也解释了为什么在拉斯维加斯 CES 上,英伟达的任何消息仍然吸睛,其 CEO 兼创始人黄仁勋演讲开头就称,「我们有 15 公斤的内容要塞进今天这场演讲里,会场里坐着 3000 人,外面的庭院里还有 2000 人在看,四楼按理说该去逛展的人又挤了 1000 个,全球还有数百万人在线围观。」
但他很快把话题拽回称,计算机行业每 10 到 15 年就会重置一次,从大型机到 PC、从 PC 到互联网、从互联网到云、从云到移动。每一次平台迁移,都会逼着世界去写「新应用」。可他紧接着说,这一次不一样,因为现在是:
「两次平台迁移同时发生」 。
01
智能体,用户的新「界面」
哪两次平台迁移?第一次迁移大家已经听到起茧,就是 AI 来了,应用要建在 AI 之上。人们起初以为 AI 本身就是应用,他承认没错,AI 的确是应用,但真正的变化是,你会在 AI 上面再建应用。第二次迁移更隐蔽也更残酷,因为软件的开发方式、运行方式、乃至整个产业的「技术栈」正被重新发明。
黄仁勋称,那些规模动辄 100 万亿美元的传统产业,会把研发预算里「几个百分点」整体转向 AI。钱不是凭空冒出来的,它来自整个世界把研发从「经典方法」搬到「AI 方法」,来自旧世界的预算向新世界的迁移,这就是为什么你会觉得这行业突然忙到离谱。
他还把过去十年的 AI 历史重新串了一遍。2015 年 BERT 让语言模型第一次「有用」,2017 年 Transformer 奠定了基础,2022 年 ChatGPT 让世界第一次直观感受到 AI 的力量。
可他认为真正关键的拐点发生在一年后,第一个 o1 推理模型出现了,让模型在推理时真的「思考」。紧接着,2024 年 Agentic AI 这个新物种开始出现,2025 年它迅速蔓延。
这类系统不只是生成文本,它能查资料、用工具、规划步骤、模拟未来、拆解问题。它可以做「从未被明确训练过」的事情。这种能力,正在通过开源模型,向整个世界扩散。

图片来源:英伟达
过去一年,真正让黄仁勋感到「兴奋」的,不是某一家闭源模型的进步,正是开源模型的集体跃迁。
黄仁勋称,开放模型现在离前沿模型大约「落后六个月」,但每过六个月就会冒出更聪明的新模型,所以下载量爆炸,因为创业公司想参与,大公司想参与,研究者想参与,学生想参与,几乎每个国家都想参与。
很多人误解英伟达,说它只是「卖 GPU」,而黄仁勋在 CES 台上反复强调一件事,即英伟达正在成为一个前沿开源模型构建者,而且是完全开放的那种。

图片来源:英伟达
他在 CES 演讲上一口气报了一堆英伟达开源模型的工作,从混合 Transformer-SSM 的 Nemotron,世界模型 Cosmos,到人形机器人 Groot,黄仁勋称这些模型全部开放。连自动驾驶领域的 Alpamayo,不仅开源模型,还开源训练数据。
黄仁勋认为,未来的 AI 不只是多模态,而是「多模型」。最聪明的系统,应该在不同任务中调用最合适的模型,最真实的系统,天然是多云、混合云、边缘计算的。
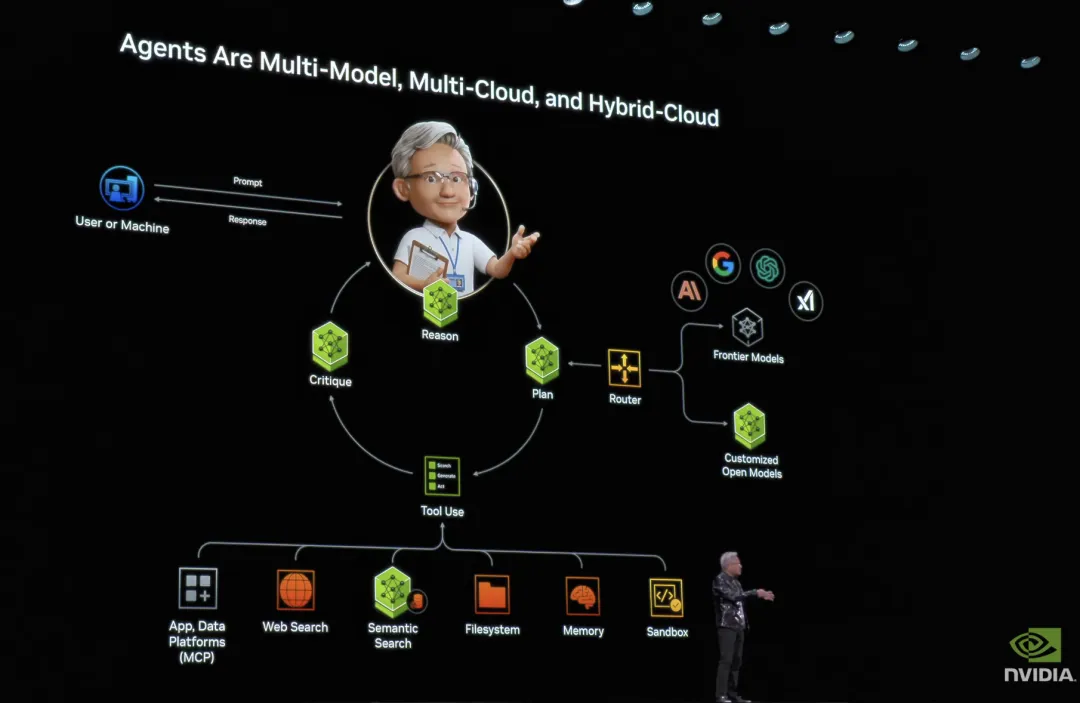
图片来源:英伟达
这意味着什么?意味着 AI 应用的本质,其实是一套调度与推理的架构。一个能判断意图、选择模型、调用工具、组合结果的智能体。
黄仁勋认为, 这种智能体正在成为新的「用户界面」,不再是 Excel,不再是表单,不再是命令行 。
02
物理 AI 的真正到来
如果说 Agentic AI 改变了软件,那么物理 AI,正在改变现实。
黄仁勋在台上花了极长时间讲一件事,让 AI 理解世界的常识,比语言困难得多。物体恒存、因果关系、惯性、摩擦、重力,对人类幼儿来说是直觉,对 AI 来说却完全陌生。而现实世界的数据,永远不够。

图片来源:英伟达
他说要做 physical AI,需要「三台计算机」:训练模型的、在车/机器人/工厂边缘推理的、以及用于仿真的。Omniverse 是数字孪生仿真世界,Cosmos 是世界基础模型,机器人模型则有 Groot 和他接下来要讲的 Alpamayo。
训练数据从哪来?语言模型有大量文本,物理世界的真实视频很多,但远远不够覆盖多样交互。于是他们现在准备做的是,用符合物理定律的合成数据生成,选择性地制造训练样本。
比如,交通模拟器输出本来不够丰富,他们把它喂给 Cosmos,让它生成物理可信的环视视频,拿来训练。Cosmos 还能从单张图生成逼真视频,从 3D 场景描述生成连贯运动,从传感器日志生成环视视频,从场景提示把「边缘案例」制造出来。还能闭环仿真,动作一做,世界响应,Cosmos 再推理下一步。
黄仁勋甚至说「 physical AI 的 ChatGPT 时刻快到了 」。
他在台上宣布了 Alpamayo,称之为「世界第一个会思考、会推理的自动驾驶 AI」。它端到端从摄像头到执行器,既学了大量真实里程的「人类示范」,也学了 Cosmos 生成的里程,再加上「几十万」极其仔细的标注样本。
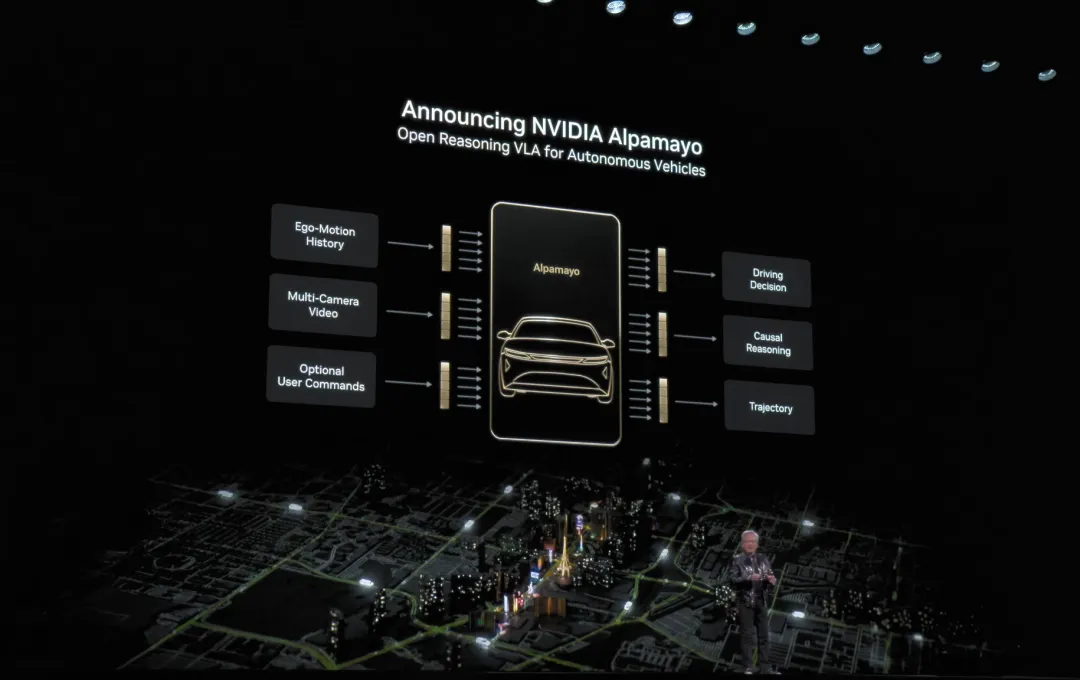
图片来源:英伟达
关键是它不只输出方向盘和刹车油门,还会告诉你它将采取什么动作、为什么这样做、轨迹是什么。因为驾驶的长尾案例几乎不可能穷举采集,但长尾可以拆成很多更普通的子情境,让车用推理去组合应对。
黄仁勋称,它能说清楚自己要做什么,为什么这么做,接下来会发生什么。这也是安全的前提。
他解释他们八年前就开始做自动驾驶,是因为很早就判断深度学习会重做整个计算栈。如果要引导行业走向未来,必须亲手把整个栈做一遍。他搬出「AI 是五层蛋糕」:最底层是能源和壳,在机器人里比如车;上一层是芯片、网络;再上一层是基础设施如 Omniverse、Cosmos;再上是模型如 Alpamayo;最上层是应用,例如奔驰。
Alpamayo 宣布「今天开源」,这套工程规模巨大,黄仁勋说他们的 AV 团队「几千人」,而奔驰五年前就与他们合作。他预测,未来可能有十亿辆车自动驾驶,「每一辆车都会有会思考的能力,每一辆车都会由 AI 驱动」。他还给出时间表:第一批在 Q1 上路,Q2 去欧洲,之后再去亚洲,Q3、Q4 逐步铺开,而且会持续更新 Alpamayo 的新版本。
黄仁勋把自动驾驶定义为 physical AI 的第一个「大规模主流市场」,并断言「拐点就在现在这段时间」,未来十年世界上很大比例的车会高度自动化。更重要的是,这套「三台计算机 + 合成数据 + 仿真」的方法会迁移到所有机器人,包括机械臂、移动机器人、乃至全人形。

图片来源:英伟达
03
Vera Rubin 的硬件秀
讲完产业,黄仁勋最后把话题拉回硬件,介绍 Vera Rubin。

图片来源:英伟达
他花了几十秒讲 Vera Rubin 的命名来源。Vera Rubin 这个名字本来是是 20 世纪的天文学家,她观察到星系边缘的旋转速度与中心差不多,这按牛顿物理学说不通,除非存在看不见的物质——暗物质。英伟达把下一代计算平台命名为 Vera Rubin,因为他们面临的「看不见的东西」也在膨胀:计算需求。
黄仁勋描述了算力需求的疯狂,模型规模每年 10 倍增长,o1 之后推理变成「思考过程」,后训练引入强化学习,计算量暴增;test-time scaling 让每次推理 token 量再涨 5 倍;而且每次冲到新前沿,上一代 token 成本会以每年 10 倍速度下跌,这反过来说明竞赛极其激烈,
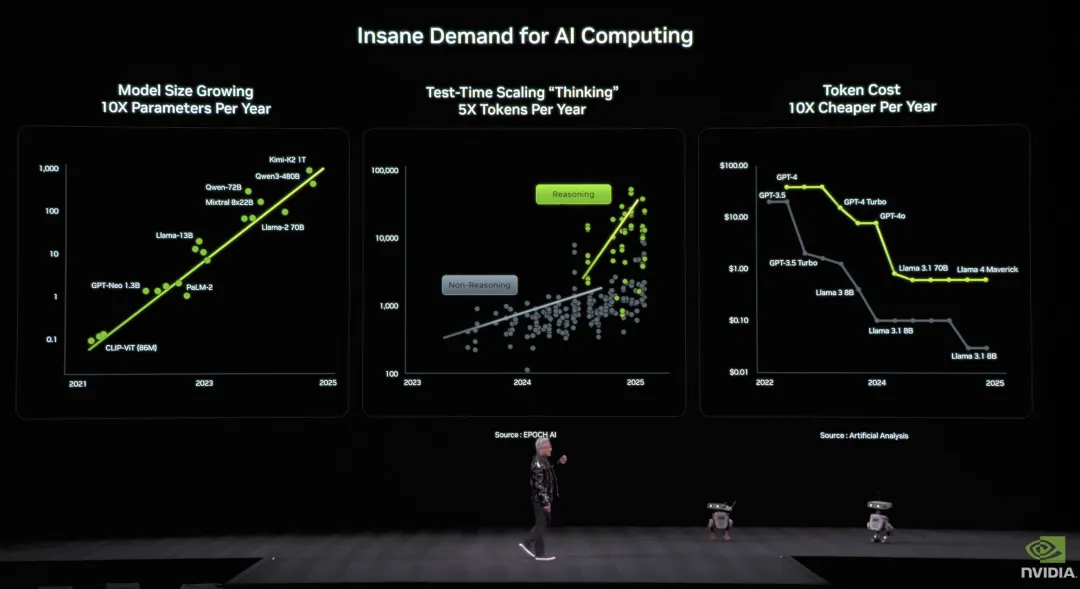
图片来源:英伟达
他说因此英伟达必须「每年推进一次计算的 state-of-the-art,一年都不能落下」。他们已经在出货 GB200,在全规模量产 GB300,而 Vera Rubin「今天可以告诉你,已经全面投产」。
Vera Rubin 的系统是一套「六芯协同」的架构,Vera 是定制 CPU,性能翻倍;Vera 与 Rubin GPU 从一开始就双向一致性共享数据,更快更低延迟;一块计算板上有 17000 个组件;每块板可以做到 100 PFLOPS 的 AI 算力,是上一代的五倍。
网络侧 ConnectX-9 为每 GPU 提供 1.6 Tbps 的横向带宽;BlueField-4 DPU 把存储与安全卸载出去;计算托盘被重新设计到「没有线、没有水管、没有风扇」的形态;第六代 NVLink 交换把 18 个节点连成一体,扩展到 72 个 Rubin GPU 像一个 GPU 一样工作;再往外是 Spectrum-X 以太网光子学,512 通道、200G、共封装光学,把成千上万机柜组成「AI 工厂」。

图片来源:英伟达
黄仁勋还提到现实的行业难题。英伟达内部原本有条规则,新一代产品最多换一两个芯片,别把供应链折腾死。可摩尔定律放缓后,晶体管增长跟不上模型十倍、token 五倍、成本十倍下滑的速度,你不做「co-design(协同设计)」就不可能追上,所以这一代不得不把每一颗芯片都重新设计。
Rubin GPU 浮点性能是 Blackwell 的 5 倍,但晶体管只有 1.6 倍,这意味着单靠制程堆晶体管已经到天花板了,必须靠架构与系统级协同设计才能搞出性能。
另外,英伟达还宣布推出针对 AI 上下文记忆的存储平台。模型每生成一个 token,都要读模型、读上下文、写回 cache,对话越长,上下文越大。黄仁勋称,你希望 AI 记住「一生的所有对话」,HBM 装不下了,Grace 直连 GPU 做「快速上下文内存」也不够了,继续往外走到数据中心存储又会被网络堵死。
于是他们做了「机柜内的超高速 KV cache 存储」,由 BlueField 跑整套上下文管理系统,把它放得离 GPU 极近。

图片来源:英伟达
在一个节点里,每 GPU 本来大约 1TB,而通过这套机柜内存储,每 GPU 还能多拿到 16TB 的上下文空间;每块 BlueField 后面挂着 150TB 级别的上下文存储,走同一套东西向高速织网,这不是「再加点盘」,而是「新增一类存储平台」。

图片来源:英伟达
黄仁勋还提到了新硬件的三种系统级能力。第一,45 摄氏度水就能冷却,整体能效提升巨大,他称这能省掉全球数据中心约 6% 的电力;第二,机密计算,传输中、静止时、计算中都加密,PCIe、NVLink、CPU-GPU 互联全部加密,让企业敢把模型交给别人跑;第三,电力平滑,因为 AI 工作负载在 all-reduce 等阶段会瞬时拉高电流,可能尖峰 25%,过去不得不多预留 25% 供电预算,现在通过电力平滑能把预算用满,不必浪费。
在他们模拟的 10 万亿参数、100 万亿 token 训练任务里,Rubin 的吞吐高到只需要 Blackwell 四分之一的系统规模就能在同样一个月窗口里训完。
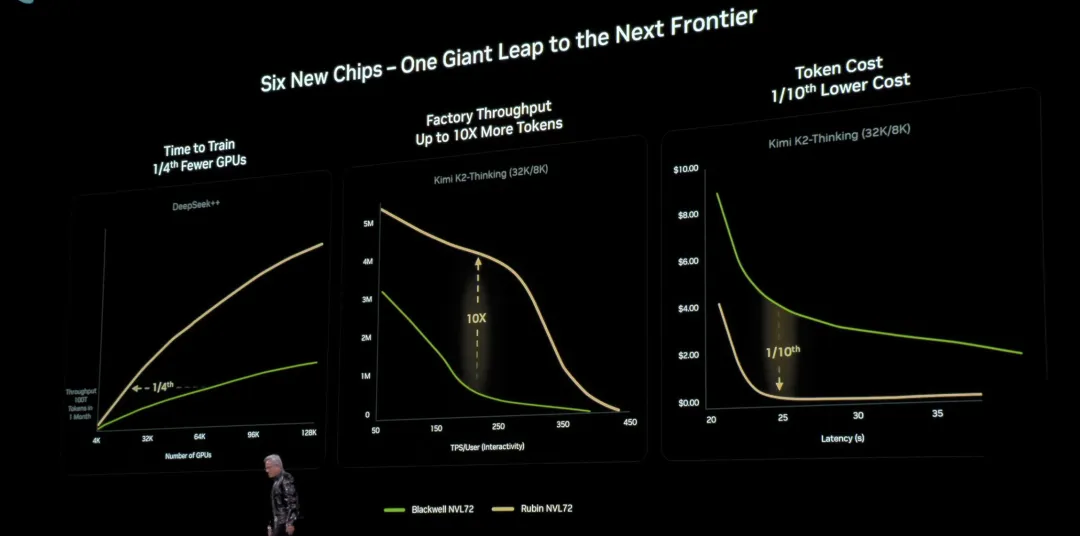
图片来源:英伟达
Rubin 相对 Hopper 的提升、相对 Blackwell 的再提升,被他形容成一轮接一轮的数量级跃迁,而 token 成本又能再降一个数量级,这就是他们所谓「把所有人推到下一前沿」的方式。
黄仁勋认为,英伟达今天不是只做芯片,而是做从芯片、基础设施、模型到应用的「全栈」,而 AI 正在重做全世界的计算栈,他们的工作是把整套栈造出来,让所有人去造应用。

图片来源:英伟达
在 CES 这种偏消费电子的舞台上,英伟达占据高光位置,可以说它也是一种情绪资产。乐观时,它是 AI 的石油,悲观时,有人直接说它像 2000 年的思科。市场不仅在乎它赚了多少钱,还在乎「AI 还会不会继续烧钱」。它的波动甚至开始影响指数本身,因为它太大了,大到一个公司的涨跌可以改变整个市场的体感温度。
当一家公司同时掌握技术叙事、产业链重要位置、以及金融市场注意力时,它就会变成图腾。图腾的好处是信仰带来溢价,坏处是溢价意味着你不能犯错。
所以问题来了,英伟达会不会掉下去?当然可能。任何站在山顶的公司都可能犯错,尤其当它大到一定程度,增长本身就变成一种负担。
但同样必须承认的是,英伟达也在用尽一切办法降低这些风险。
其目前主要战略仍是努力把自己从卖芯片变成卖生态。当硬件、网络、调度、软件工具链都握在手里时,英伟达就不再仅仅领先于竞争对手一代 GPU,而是在领先系统复杂度。
目标至少是,让对手即便追上算力,也很难追上生态摩擦成本。


