
近日,Soul App AI 团队 (Soul AI Lab) 正式开源播客语音合成模型 SoulX-Podcast。
近日,Soul App AI 团队 (Soul AI Lab) 正式开源播客语音合成模型 SoulX-Podcast。该模型是一款专为多人、多轮对话场景打造的语音生成模型, 支持中、英、川、粤等多语种/方言与副语言风格, 能稳定输出超 60 分钟、自然流畅、角色切换准确、韵律起伏丰富的多轮语音对话。
除了播客场景以外,SoulX-Podcast 在通用语音合成或克隆场景下也表现出色, 带来更真实、更生动的语音体验。
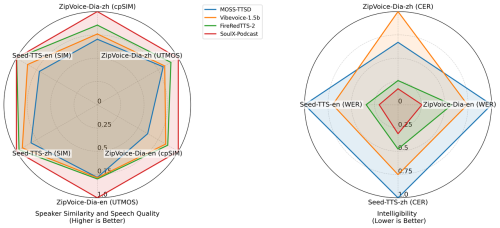
SoulX-Podcast 表现
SoulX-Podcast 亮点:流畅自然多轮对话、多方言、超长播客生成
零样本克隆的多轮对话能力
在零样本克隆播客生成场景中,SoulX-Podcast 展现出卓越的语音生成能力。它不仅能高度还原参考语音的音色与风格, 更能根据对话语境灵活调节韵律与节奏, 让每一段对话都自然流畅、富有节奏感。无论是多轮长时对话, 还是情感层次丰富的交流,SoulX-Podcast 都能保持声音的连贯与表达的真实。此外,SoulX-Podcast 还支持笑声、清嗓等多种副语言元素的可控生成, 让合成语音更具临场感与表现力。
多语种和跨方言的克隆能力
除中英文外,SoulX-Podcast 同样支持四川话、河南话、粤语等多种主流方言。更值得关注的是,SoulX-Podcast 实现了跨方言音色克隆——即便仅提供普通话的参考语音, 模型也能灵活生成带有四川话、河南话、粤语等方言特征的自然语音。
超长播客生成
SoulX-Podcast 可以支持超长播客的生成, 并维持稳定的音色与风格。
聚焦语音,AI 重构情感纽带
一直以来, 声音都是传递信息和情感的重要媒介, 也最能在沟通中赋予「情绪温度」和「陪伴感」。在 Soul, 用户积极通过语音实时互动, 表达自我、分享交流, 收获新关系, 语音成为用户构建链接的「情感纽带」,「语音社交」也成为平台颇具代表性的标签之一。
在推进 AI+社交的过程中, 智能对话、语音生成、情感化表达等语音能力是 Soul 重点布局的方向。此前, 平台端到端全双工语音通话大模型全面升级, 并在站内开启内测。新模型赋予 AI 自主决策对话节奏的能力,AI 可主动打破沉默、适时打断用户、边听边说、时间语义感知、并行发言讨论等, 实现更接近生活日常的交互对话和「类真人」的情感陪伴体验。
同时, 团队推出了自研的语音生成大模型、语音识别大模型、语音对话大模型等语音大模型能力, 快速应用于「虚拟伴侣」、 群聊派对 (多人语音互动场景) 等多元场景中。
例如,9 月,Soul 的两位虚拟人——孟知时与屿你——在群聊派对中发起了一场持续约 40 分钟的对话, 在没有任何额外投流、仅依靠虚拟人自身自然流量的情况下, 这场活动迅速引爆社区, 房间互动热度刷新平台纪录, 受到了广大用户的热烈欢迎。
这一成功案例让 Soul 的 AI 技术与虚拟 IP 运营团队深刻意识到:「虚拟 IP + AI 语音对话」正在成为虚拟内容生态的重要增长点。它不仅展现了虚拟人的人格魅力与表达张力, 更揭示了 AI 在内容创作与社交互动中的全新潜能。
然而, 当时业界能够稳定支持多轮自然对话的开源播客生成模型相对较少, 并且当场景从单人独白扩展到多人对话与长篇播客时, 也普遍面临一些问题。为此,Soul 团队决定开源 SoulX-Podcast, 希望能携手 AIGC 社区, 共同探索 AI 语音在内容创作、社交表达与虚拟生态中的更多可能。
开源新阶段, 探索 AI+社交更多可能
相比传统的单说话人语音合成系统, 播客语音合成系统不仅需要保持文本与语音的精准一致, 还要具备更强的上下文理解能力, 以实现多轮对话间语音衔接的自然流畅与节奏的动态变化。此外, 面对多角色交互和超长对话场景, 系统还需在音色一致性、风格延续性以及角色切换的准确性上实现更高水平的控制与建模。
近来, 已有部分开源研究开始探索播客或对话场景下的多说话人、多轮次语音合成能力。然而, 这些工作仍主要聚焦于普通话或英语, 对中文受众广泛的方言 (如粤语、四川话、河南话等) 支持不足。此外, 在多轮语音对话场景中, 恰当的副语言表达——如叹息、呼吸、笑声——对提升对话的生动性与自然度至关重要, 但现有模型对此普遍关注不足。
而 SoulX-Podcast 正是希望解决这些痛点:不仅支持多轮、多角色的长对话生成, 同时兼顾方言覆盖和副语言表达能力, 使播客语音更贴近真实交流场景、富有表现力与生动感, 从而提升听众的沉浸体验和内容传播力。
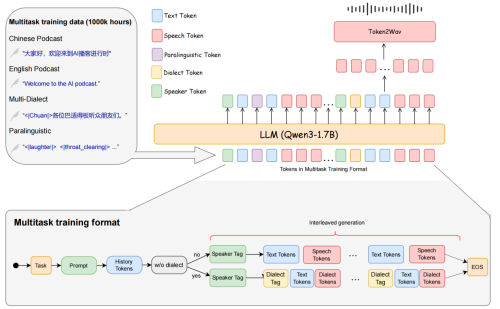
整体 SoulX-Podcast 模型基础结构上采用了常用的 LLM + Flow Matching 的语音生成范式, 前者建模语义 token, 后者进一步建模声学特征。在基于 LLM 的语义 token 建模方面,SoulX-Podcast 以 Qwen3-1.7B 作为基座模型, 并基于原始文本模型参数进行初始化, 以充分继承其语言理解能力。
尽管 SoulX-Podcast 是专为多人、多轮对话场景设计的系统, 但在传统的单人语音合成与零样本语音克隆任务中同样表现优异。在播客生成任务中, 相较于近期相关工作,SoulX-Podcast 在语音可懂度与音色相似度方面均取得了最佳结果。
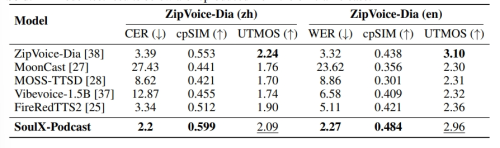
SoulX-Podcast 在播客场景下的表现
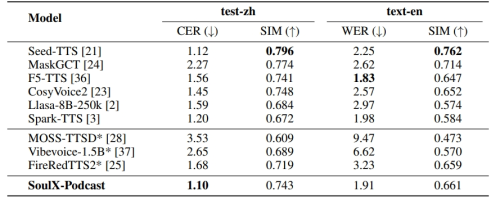
SoulX-Podcast 在通用 TTS 上的表现,*官方模型的复现结果
此次 SoulX-Podcast 的开源, 是 Soul 在开源社区领域的一次全新尝试, 也是一个新的起点。Soul 团队表示, 未来将持续聚焦语音对话合成、全双工语音通话、拟人化表达、视觉交互等核心交互能力的提升, 并加速技术在多样化应用场景与整体生态中的融合落地, 为用户带来更加沉浸、智能且富有温度的交互体验, 持续提升个体的幸福感与归属感。同时, 团队将进一步深化开源生态建设, 与全球开发者携手, 共同拓展 AI 语音等前沿能力的边界, 探索「AI +社交」的更多可能。
来源:互联网


