
9月12日,阿里通义发布下一代基础模型架构Qwen3-Next,并“打样”开源 Qwen3-Next系列模型,总参数80B仅激活 3B ,性能就可媲美千问3旗舰版235B模型,实现模型计算效率的重大突破。
9 月 12 日,阿里通义发布下一代基础模型架构 Qwen3-Next,并「打样」开源 Qwen3-Next 系列模型,总参数 80B 仅激活 3B,性能就可媲美千问 3 旗舰版 235B 模型,实现模型计算效率的重大突破。基于这一架构创新,Qwen3-Next 模型训练成本较密集模型 Qwen3-32B 大降超 90%,长文本推理吞吐量提升 10 倍以上,为未来大模型的训练和推理的效率设立了全新标准。
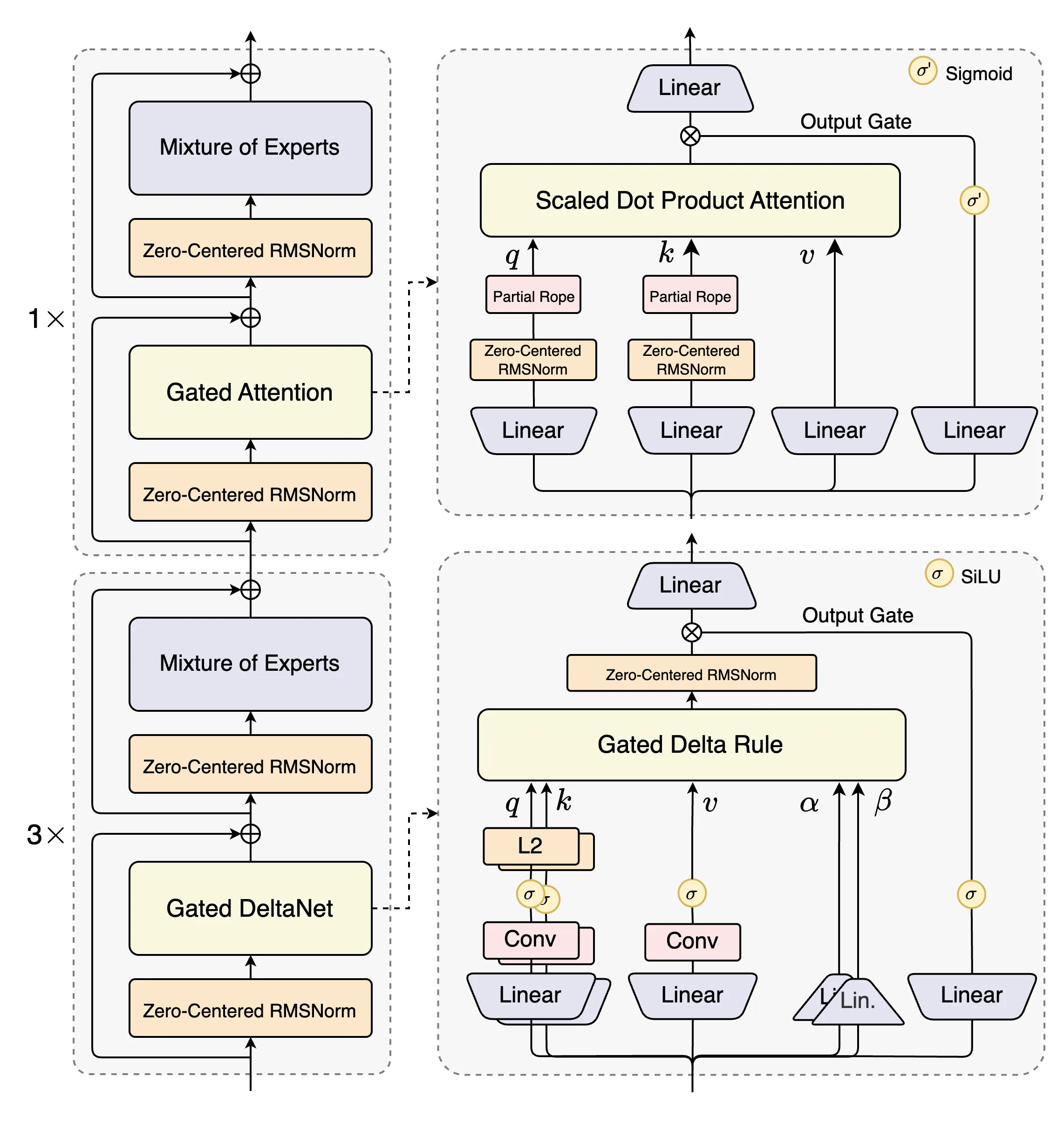
Qwen3-Next 针对大模型在上下文长度和总参数两方面不断扩展(Scaling)的未来趋势而设计,模型结构相较 4 月底推出的 Qwen3 的 MoE 模型,新增采用了多种新技术并进行了核心改进,包括混合注意力机制、高稀疏度 MoE 结构、一系列训练稳定友好的优化,以及提升推理效率的多 token 预测(MTP)机制等。
基于 Qwen3-Next 新架构,通义团队现开源了 Qwen3-Next-80B-A3B 的指令(Insctruct)模型和推理(Thinking)模型。新模型预训练在 Qwen3 预训练数据的子集 15T tokens 上进行,仅需 Qwen3-32B 的 9.3% 的 GPU 计算资源,便训练出性能更好的 Qwen3-Next-Base 基座模型,大幅提升了训练效率;而后又在强化学习训练中解决了长期存在的稳定性与效率难题,实现模型性能的新飞跃。
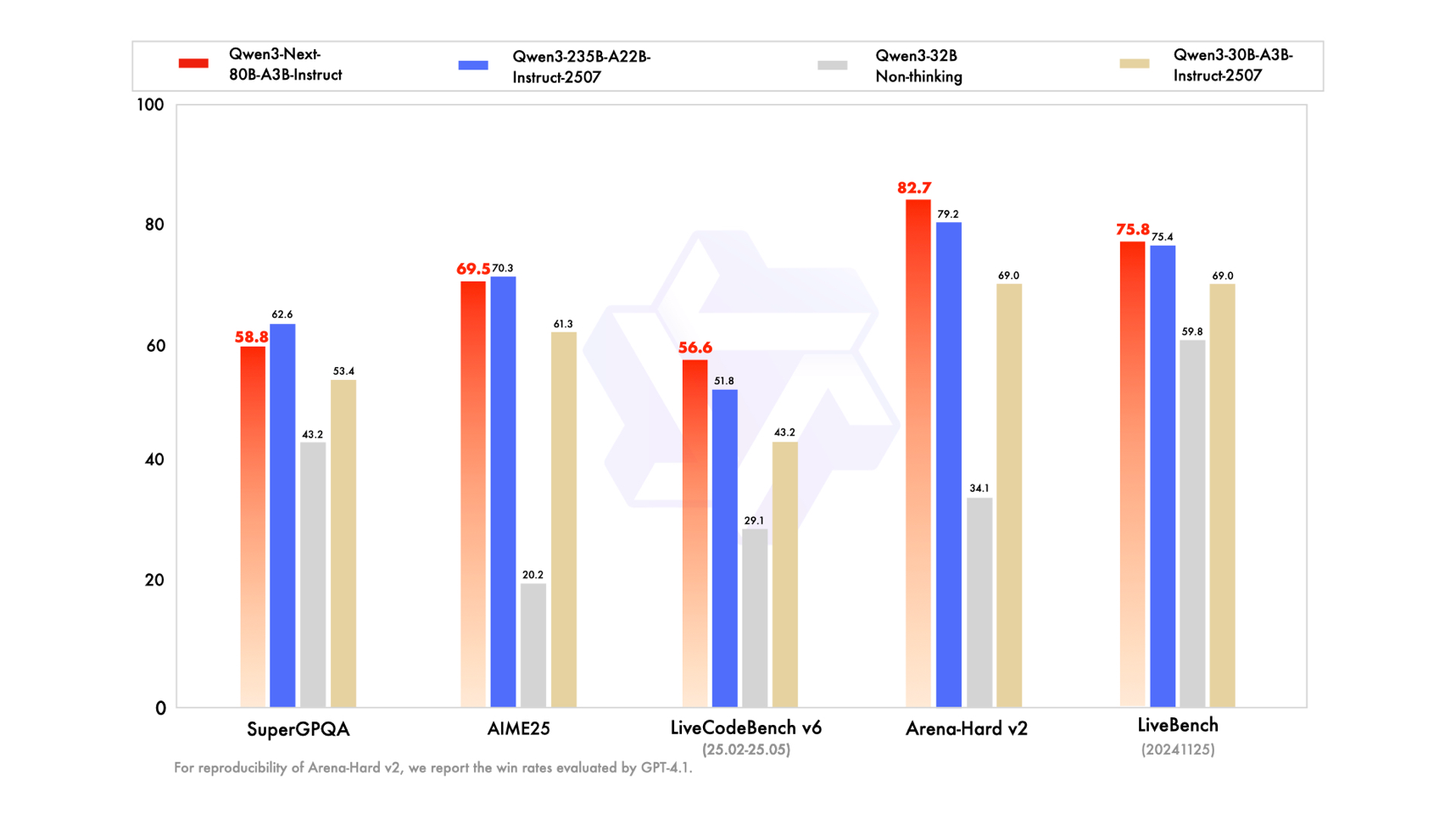
图说:Qwen3-Next-80B-A3B-Instruct 性能评测图
在编程(LiveCodeBench v6)、人类偏好对齐 (Arena-Hard v2) 以及综合性能力 (LiveBench) 评测中,Qwen3-Next-Instruct 表现甚至超过了「开源王者」旗舰模型 Qwen3-235B-A22B-Instruct-2507,并在包含通用知识(SuperGPQA)、数学推理(AIME25)等核心测评中全面超越了 SOTA 密集模型 Qwen3-32B;Qwen3-Next-Thinking 则全面超越了 Gemini2.5-Flash-Thinking,在数学推理 AIME25 评测中斩获惊人的 87.8 分。而达到如此高水平的模型性能,仅需激活 Qwen3-Next 总参数 80B 中的 3B。
高稀疏 MoE 架构是 Qwen3-Next 面向下一代模型的最新探索。当前,MoE 混合专家架构是主流大模型都采用的架构,它通过激活大参数中的小部分专家完成推理任务,计算开销更小,反应速度更快。此前,Qwen3 系列的 MoE 专家激活比约为 1 比 16,Qwen3-Next 通过更精密的高稀疏 MoE 架构设计,实现了 1 比 50 的极致激活比,创下业界新高。
未来的大模型必须学会高效处理超长上下文,Qwen3-Next 表现卓越。Qwen3-Next 对经典 Transformer 核心组件进行了重构,采用基于 Gated DeltaNet 的线性注意力和通义团队自研的门控注意力机制的混合注意力机制,更省内存,并大幅降低了计算复杂度,更易处理超长上下文。同时,Qwen3-Next 在预训练时就采用多 Token 预测技术 MTP(Mutiple-Token Prediction),模型推理速度大幅提升:在处理超 32K tokens 的长上下文时,Qwen3-Next 的推理吞吐量比 Qwen3-32B 高出 10 倍以上。
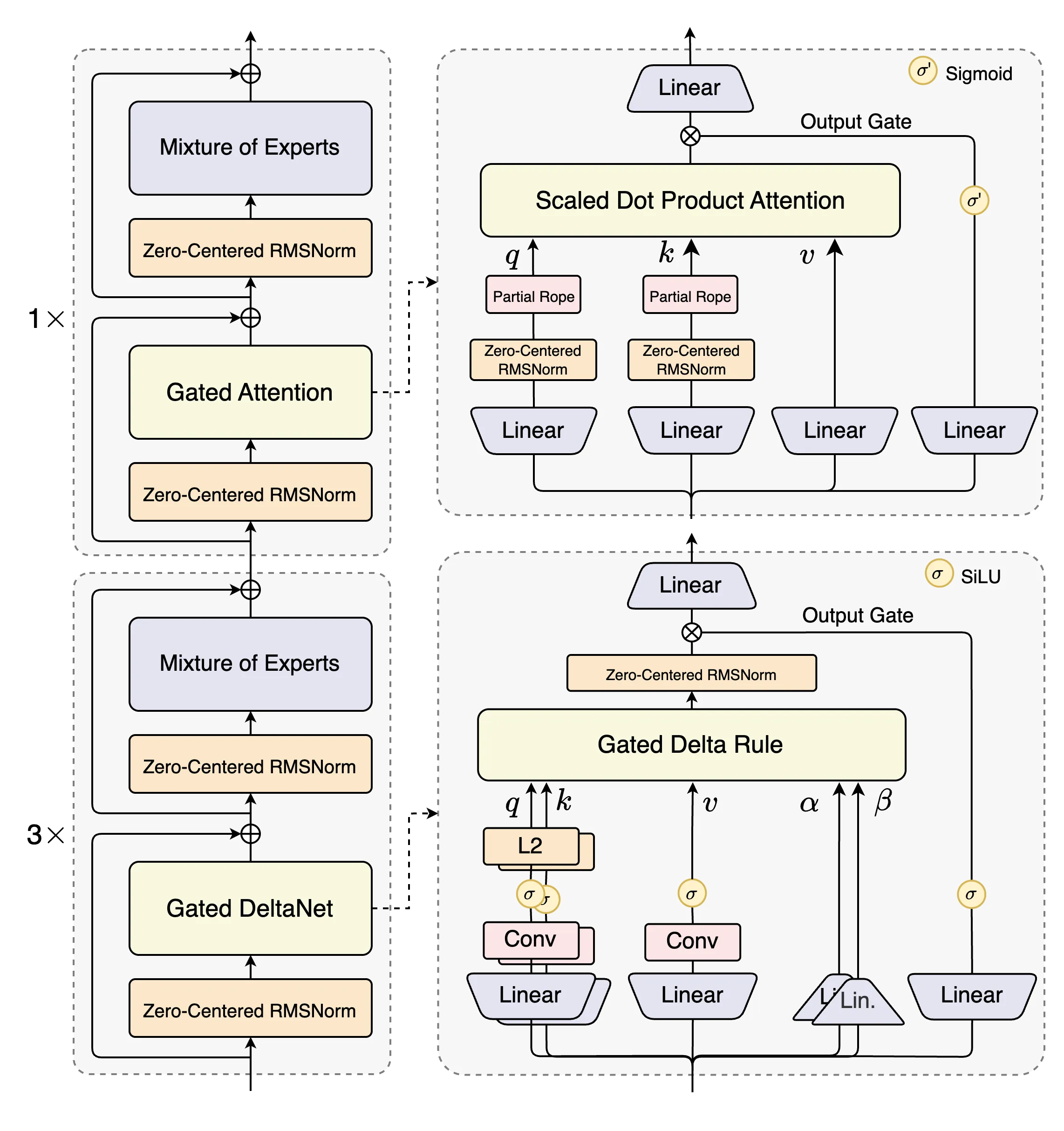
图说:Qwen3-Next 模型结构图
近期,阿里通义动作频频,推出超万亿参数的 Qwen3-Max-Preview、文生图及编辑模型 Qwen-Image-edit、语音识别模型 Qwen3-ASR-Flash 等,并持续推进「全尺寸」「全模态」开源。全球 AI 开源社区 HuggingFace 最新数据显示,通义千问 Qwen 衍生模型数已超 17 万,稳坐全球第一开源模型。通义千问也是中国企业使用量最多的模型,沙利文报告显示,2025 年上半年,在中国企业级大模型调用市场中,阿里通义占比 17.7% 位列第一。
(完)


