
AI 进入普惠阶段, 但 AI 的全周期建设未必「普惠」。
AI 进入普惠阶段, 但 AI 的全周期建设未必「普惠」。显卡资源、模型资源、运维管理等, 每个环节都存在巨大的成本挑战。
深信服 AI 创新平台全新升级, 为用户向上承载各类大小模型, 向下开放兼容, 广泛适配各种硬件设施, 并最终实现【为用户不断降低端到端 AI 应用建设 TCO】。
一、全模型全场景, 低成本起步
对用户来说, 一旦决定进行 AI 建设, 快速起步非常重要。但其实,低成本起步也同样重要。AI 建设起步阶段, 涉及大小模型部署、模型试用选择、多种显卡适配消耗等环节, 想要快速起步, 必须找到低门槛启动的方式。
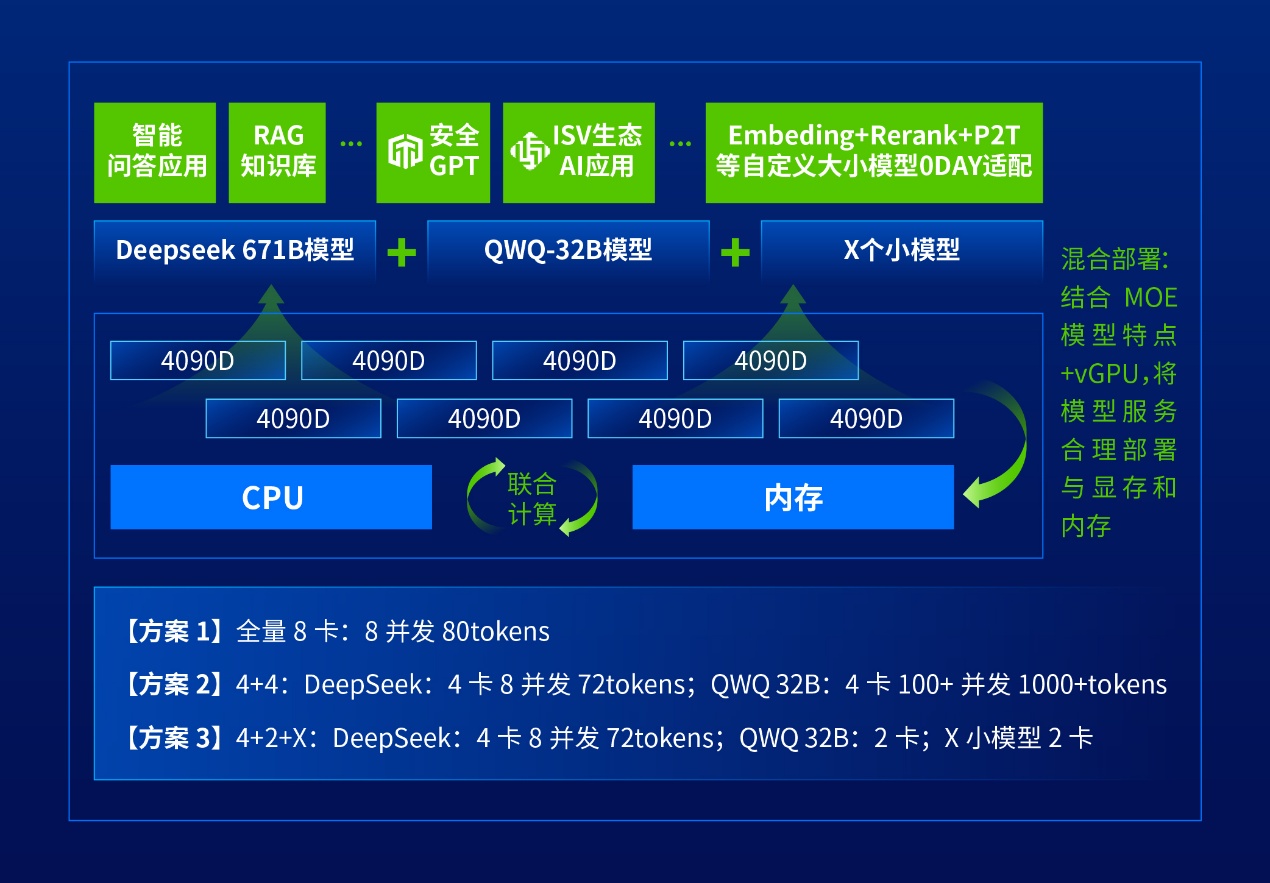
深信服 AI 创新平台率先发布商业化4090D 起步运行含 671B 的端到端 AI 应用场景。也就是说,用户只需要用 8 卡的 4090D 即可运行满血版 671B 的端到端 AI 应用场景, 满足大参数、小参数模型在更低硬件和显卡上的部署, 让用户在 AI 建设起步阶段, 能以更低成本体验各类模型的效果, 选择出最适合自身的模型。

二、全模型承载, 实现快速部署
在快速部署这件事上,AI 创新平台也为用户提供足够的资源。AI 创新平台可承载 DeepSeek、Qwen、LLAMA 等各类最新大模型及丰富的小模型, 支持统一运维管理的同时, 也支持从外部上传自定义大小模型服务,不仅满足用户快速部署、随时尝鲜大模型的需求, 也能为用户的个性化选择提供支撑。
三、显卡利用率数倍提升, 大幅降低显卡资源成本
RAG、智能客服、Copilot 智能体等应用落地伴随大量大小模型的混合部署使用, 尤其小模型的使用更为广泛。小模型一多, 为防止显卡资源争抢, 不得不按卡进行资源模型算力隔离, 带来严重显卡资源消耗。
AI 创新平台的最新版本通过vGPU 支持 1% 级别的显卡切分,大幅提升显卡资源利用率。在这种情况下,用户显卡越高端、模型使用越多, 反而更节省成本。用户在落地 AI 的过程中, 不必操心用卡成本。

四、多卡兼容, 摆脱锁定, 用卡更灵活
而为了满足用户在 AI 扩建过程中, 越来越多样的用卡需求,AI 创新平台不断兼容适配国内外显卡厂商, 同时摆脱单一硬件供应商锁定,让用户用卡更灵活, 持续用上性价比最高的显卡。
五、起步→生产→规模化, 平滑演进
AI 创新平台为用户提供从异构统一管理的低门槛 AI 平台, 平滑演进到未来 AI 算力中心的完整路径。
从 AI 起步阶段开始, 以低门槛方案落地轻型一体化 AI 算力平台;随着业务发展, 更多 AI 应用需要落地, 进入 AI 生产阶段, 搭建中型 AI 算力平台;再到 AI 规模化应用阶段, 落地中大型 AI 智算中心。
在逐步演进的过程中, 深信服 AI 创新平台可以对算力资源实现多集群、多品牌、多型号的异构管理, 同时不断丰富更多成本优化、稳定可靠、简单安全的能力,让用户充分利用持续积累的 AI 能力, 平滑扩展自身 AI 平台。
AI 大爆炸时代, 各行业用户遇到的挑战不尽相同, 但如何克服繁杂需求与多样尝试带来的成本, 却是大多数用户的痛处。新智算时代, 深信服希望为用户提供这样一个 AI 基础设施, 让用户在 AI 建设的每一个阶段, 都能以更轻松、更高效、更安全的方式落地 AI。
来源:互联网


