
AI 大模型 (LLM) 掀起的生成式革命, 正重塑各行各业, 连我们每天刷到的推荐系统也不例外。
AI 大模型 (LLM) 掀起的生成式革命, 正重塑各行各业, 连我们每天刷到的推荐系统也不例外。
传统推荐系统像一条多环节的「流水线」(级联架构), 容易导致算力浪费、目标冲突, 制约了发展。要突破瓶颈, 关键在于用 LLM 技术进行「一体化」重构, 实现效果提升和成本降低。
快手技术团队最新提出的「OneRec」系统, 正是这一思路的突破。它首次用端到端的生成式 AI 架构, 彻底改造了推荐系统的全流程, 在效果和成本上实现了「既要又要」:
· 效果猛增: 有效计算量提升 10 倍! 让强化学习技术在推荐场景真正「活」了起来, 推荐更精准。
· 成本锐减: 通过架构革新, 训练和推理的算力利用率 (MFU) 分别飙升至 23.7% 和 28.8%, 运营成本 (OPEX) 仅为传统方案的 10.6%!
目前, 该系统已在快手 App / 快手极速版双端服务所有用户, 承接约 25% 的 QPS(每秒请求数量), 带动 App 停留时长提升 0.54%/1.24%, 关键指标 7 日用户生命周期 (LT7) 显著增长, 为推荐系统从传统 Pipeline 迈向端到端生成式架构提供了首个工业级可行方案。

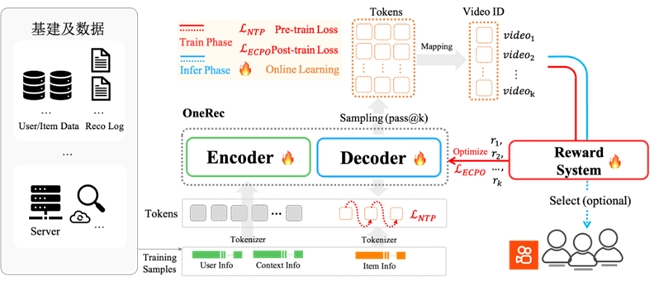
(图: OneRec 系统概览)
OneRec 基础模型剖析
OneRec 采用端到端生成式架构, 首创协同感知多模态分词器:通过融合视频标题、图像等多维信息与用户行为, 利用 RQ-Kmeans 分层生成语义 ID。其 Encoder-Decoder 框架将推荐转化为序列生成任务:
● Encoder 整合用户终身/短期行为序列实现多尺度建模;
● MoE 增强的 Decoder 通过 Next Token Prediction 精准生成推荐结果。
● 实验验证其遵循 Scaling Law——参数量增至 2.633B 时训练损失显著下降, 结合特征/码本/推理级优化, 实现效果与算力的协同突破。
强化学习 (RL) 偏好对齐
OneRec 突破传统推荐依赖历史曝光的局限, 创新引入强化学习偏好对齐机制。通过融合 偏好奖励 (用户偏好)、格式奖励 (有效输出) 及 业务奖励 (工业需求) 构建综合奖励系统, 并利用 个性化 P-Score 作为强化信号。采用改进的 ECPO 算法 (严格截断负优势梯度) 提升训练稳定性, 在快手场景中实现 不损失曝光量前提下显著提升用户时长, 达成工业级效果突破。

性能优化
在性能优化上,OneRec 突破传统推荐 MFU 个位数魔咒:通过架构重构+算子压缩 92% 至 1,200 个, 训练/推理 MFU 提升至 23.7%/28.6%, 算力效能达主流 AI 模型水平, 实现 3-5 倍跃升。首次让推荐系统达到与主流 AI 模型比肩的算力效能水平。
此外, 快手技术团队还针对 OneRec 特性在训练和推理框架层面进行了深度定制优化。训练侧采用请求分组特征复用与变长 Flash Attention 提升计算密度, 自研 SKAI 系统实现 Embedding 全流程 GPU 训练, 彻底消除 CPU 同步瓶颈;推理侧首创计算复用架构——Encoder 单次前向+Beam 间 KV 共享+Decoder 层 KV Cache, 支撑 512 大 Beam Size 生成需求, 并基于 Float16 混合精度与 MoE/Attention 算子深度融合提升吞吐。最终训练/推理 MFU 达 23.7%/28.8%(较传统模型提升 3-5 倍), 运营成本降至传统方案 10.6%, 实现近 90% 成本节约。
Online 实验效果
该模型经过一周 5% 流量 AB 测试, 在点赞、关注、评论等所有交互指标上均获正向收益 (如下图)。系统现已全量覆盖短视频推荐主场景, 承担约 25% QPS。除了短视频推荐的消费场景之外,OneRec 在快手本地生活服务场景同样表现惊艳:AB 对比实验表明该方案推动 GMV 暴涨 21.01%、订单量提升 17.89%、购买用户数增长 18.58%, 其中新客获取效率更实现 23.02% 的显著提升。目前, 该业务线已实现 100% 流量全量切换。

生成式 AI 方兴未艾, 正引发各领域根本性技术变革与降本增效。OneRec 不仅论证了推荐系统与 LLM 技术栈深度融合的必要性, 更重构了互联网核心基础设施的技术 DNA。随着其新范式的到来, 推荐系统将加速迎来「端到端生成式觉醒」时刻。
来源:互联网


