

360开源全网首个 RL-LoRA 训练方案,开启 AI 高效进化新时代
在大模型的训练中,强化学习算法一直是提升模型性能的关键。然而,其面临着计算资源要求高、训练速度慢等问题,让普通企业机构望而却步。面对行业共性难题,近日,在 360 数字安全集团冰刃实验室主导下,打造出「轻量化、高性能」的 AI 训练方案:RL-LoRA,在保持模型泛化能力的前提下,体积仅为原始全参数模型的 1%-5%,实现强化学习训练技术引领性突破。目前,360 安全大模型已深度融合 RL-LoRA 技术,相关核心代码也已正式对外开放下载使用。
大模型强化学习训练困境:更高性能,更高门槛
当 DeepSeek-R1 凭借卓越的推理与泛化能力惊艳全球,其背后的核心引擎——强化学习算法 GRPO(Generalized Reinforcement Learning Policy Optimization)也备受瞩目。GRPO 的训练能够简洁有效的提升大模型的推理能力,同时保持更优的泛化能力。然而 GRPO 训练对显存消耗高且速度缓慢,这就对于大模型的强化学习训练设置了更高的门槛要求,让一些资源有限的企业以及在垂直领域的模型应用望而却步。
一方面,强化学习训练方法对显存资源要求巨大,在配备 TRL+FA2 的 GRPO 设置中,Llama 3.1(8B)在 20K 上下文长度下,训练需要 510.8GB 的 VRAM,而主流的娱乐级显卡容量通常为 2GB、4GB 或 8GB。
另一方面,强化学习训练相对速度慢,需要持续对训练效率优化提升。GRPO 执行过程中,需同时运行策略模型、参考模型和推理模型,每一次权重更新操作需要频繁切换模型,不仅引发效率瓶颈,还会产生显存占用尖峰,使得强化学习训练速度缓慢。
最后,显卡资源有限的机构或垂类领域应用大模型时,常面临在单一服务器上同时推理多个不同功能大模型的需求。LoRA 这一低资源训练方法的重要性愈发凸显,为高效利用有限资源、实现多模型协同推理提供了关键技术支撑。
重大突破:360 实现全网首个强化学习 LoRA 训练方案
面对行业共性难题,由 360 冰刃实验室主导,联合加州伯克利大学 BAIR 顶尖学者 (S.Xie、T.Lian、J.Pan) 及字节跳动 Seed 团队专家,在开源项目 Volcengine/VERL 中贡献了里程碑式方案:RL-LoRA 集成支持,其主要具备以下技术优势:
更少资源、更高性能
RL-LoRA 训练方法将 LoRA 引入至 GRPO 等强化学习训练全流程,能够以更低的资源支持更大规模模型的强化训练。以往 8 卡 A100 无法触及的 32B+模型,如今可轻松训练 70B 甚至更大尺寸。
实际测试中,对于 LoRA_rank=32 的 0.5B 模型,采用 RL-LoRA 训练方法,训练收敛速度和最终性能与常规 GRPO 训练几乎相同,节省算力资源的同时,保证了训练的正确性和稳定性。
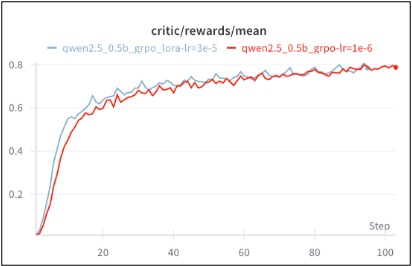
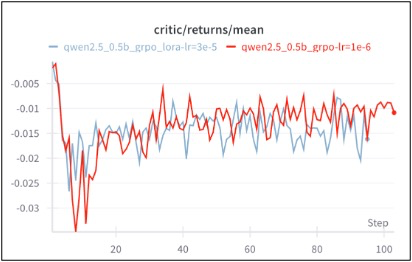
![]()
![]()
更多批次、更高效率
RL-LoRA 训练方法降低了显存尖峰,在同等硬件下显著提升训练批次(Batch Size),可以支持更多数据并行处理,提升计算资源利用率,进而加快训练速度,助力模型高效训练。
轻量化、易部署
训练产出的 LoRA Adapter 体积仅为原始全参数模型的 1%-5%,微小体积使其复制、分发、加载异常便捷,彻底摆脱动辄数百 GB 巨型模型的部署枷锁。
落地实践:360 安全大模型率先落地应用 RL-LoRA 技术
针对安全垂直领域多场景化的应用需求,360 独创了紧凑型多专家协同大模型(CCoE)架构,该架构与模型基座解耦并具备迁移能力,使得专项任务无需训练大规模基座参数。在模型基座之上,360 针对各类安全研判、分析、生成等任务设计了相互独立的「专家」,即插即用,少许训练路由参数就能即可完成新任务「专家」扩展工作。
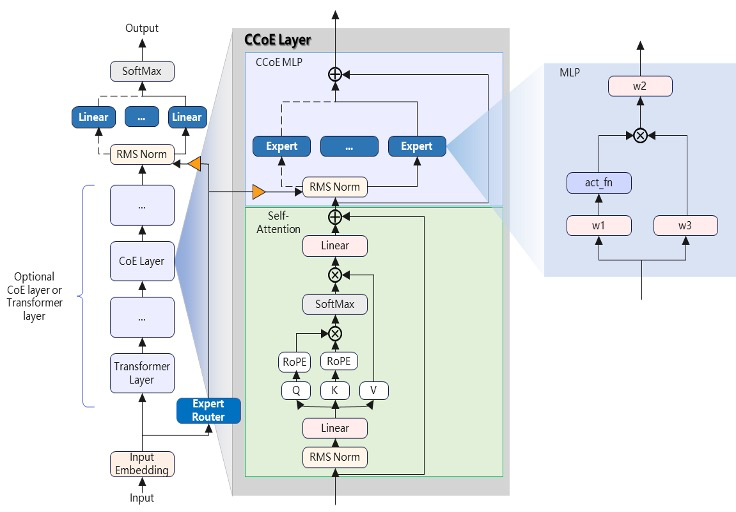
![]()
360 安全大模型已深度融合 CCoE 与 RL-LoRA 技术,面向安全运营、威胁狩猎、钓鱼研判等众多安全场景,实现专项微调显存占用降低、训练效率提升、集约化部署应用。同时,360 通过专项训练推出 100+安全专家智能体,已经为北京市朝阳区政府、重庆大学等近 500 家用户在真实环境中完成测试应用与交付,加持政府、金融、央企、运营商、交通、教育、医疗等行业客户实现智能化安全防御。
目前,RL-LoRA 相关核心代码已正式对外开放下载使用。未来,360 继续深耕 AI+安全实践应用,以创新技术赋能行业智能化、高效化转型,为国内 AI 研发生态贡献力量!


