

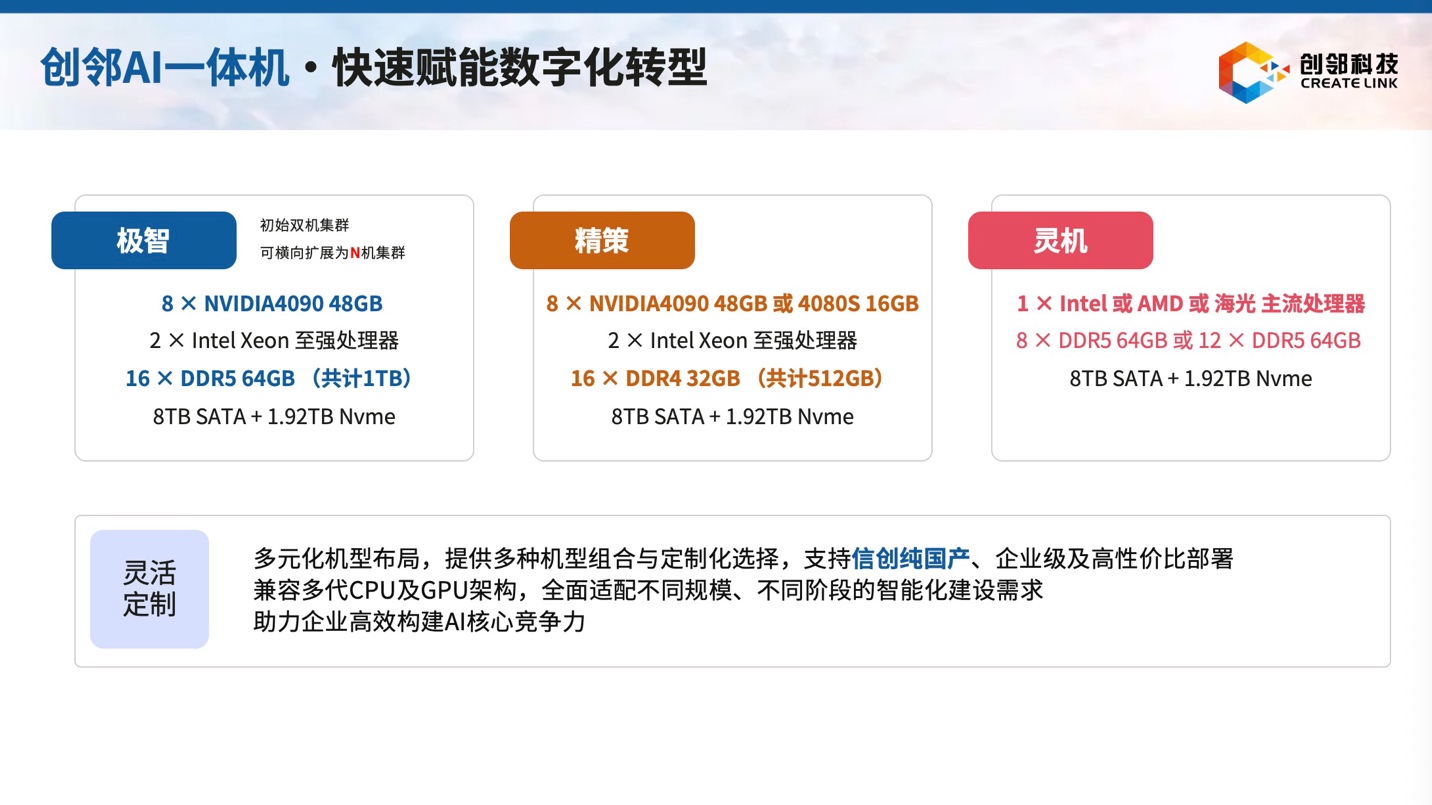
作为杭州市准独角兽企业,杭州市政府一直以来从人才政策到企业服务等方面给予了巨大的支持。Vaga 系列产品已经用「搬机器放在会议室桌上」的演示方式,向杭州市委相关领导完成了汇报演示,正推进支持杭州市委市政府内部 AI 创新应用,用低配高能的非 GPU 硬件解决 GPU 算力与并发不足的问题。相关产品也已在广州市等核心城市完成演示并推进部署。
创邻科技推出了只使用 1 颗 AMD/Intel/海光/鲲鹏 CPU,无需 GPU,无需超频或水冷系统,就可以运行大模型的一体机产品线「Galaxybase Vaga」,各机型可支持不同频谱的模型,deepseek671B 满血版最高可达 12tokens/秒、qwen3-235B 18tokens/秒、qwen3-30B 65tokens/秒(人眼阅读速度平均为 4-5 tokens/秒),支持上传 150 万 tokens 长文本(譬如 200 万字的小说)进行问答,配备支持 MCP 协议的 Agent 平台,以及能够让大模型充分使用本地知识的 Graph RAG 组件,能够实现大模型基于公域常识以及私域专识的知识问答与复杂任务编排、调度和执行,真正实现大模型廉价普惠应用!Galaxybase Vaga 系列无 GPU AI-PC 完全打破了美国 GPU 禁售,也不受限于国产 GPU 供货紧张和高昂价格,这标志着个人用户可以拥有、具备极致性价比的 AI-PC 时代来临了!
作为杭州市准独角兽企业,杭州市政府一直以来从人才政策到企业服务等方面给予了巨大的支持。Vaga 系列产品已经用「搬机器放在会议室桌上」的演示方式,向杭州市委相关领导完成了汇报演示,正推进支持杭州市委市政府内部 AI 创新应用,用低配高能的非 GPU 硬件解决 GPU 算力与并发不足的问题。相关产品也已在广州市等核心城市完成演示并推进部署。
Galaxybase Vaga 打破 GPU 禁售的价值体现在多个方面:
首先,普惠 AI-PC 不再需要任何显卡,完全不受 GPU 禁售影响;最近英伟达向美国政府提出中国 500 亿的市场机会,但同时正在计划修改 H20 版本大幅降低显存特供中国,有了无 GPU AI-PC,也就不用等待阉割版 H20 单卡与 CPU 的组合了。
其次,极大降低企业大模型落地的硬件成本。8 卡非禁售 GPU 集群价格动辄百万元起步,以 8 卡华为某 GPU 机型为例,市场价格约 400 万元,这超过了大部分中小企业的预算。而创邻的一体机价格仅为 6 万/台,充分实现了 AI 普惠,能够激活更大面向个人和中小企业客户的 AI 应用市场。
其三,企业级应用通常面临多部门、多人员的同时使用大模型的高并发问题,会出现资源抢占而导致服务无法稳定响应。创邻方案可以通过多台普惠无显卡 PC 组建算力网络实现原来多用户并发下只有 8 卡 GPU 才能达到的平均吞吐率,并且每台 PC 资源单独分配给个人,确保资源隔离与独占,多用户的并发使用相互不受影响。该方案不仅在大模型服务的稳定性上更好,还实现了模型即服务的弹性部署方式,客户可以以单台 PC 为单位按需购买和扩容,降低一次性初始投入,方案更加灵活。
最后,除了硬件成本的降低与方案按需扩容的灵活性,创邻的 AI- PC 方案的运维和维护成本也更加低廉。1 台 8 卡 4090GPU 服务器月度耗电量按 80% 负载,约为 4608 千瓦时,以 0.78 元的工业电价为例,月电费大约需要 3594 元。但 1 台 Galaxybase Vaga 在相同负载情况下月电耗成本根据机型不同仅为 560-720 元/月,电费成本节省超 80%。
Galaxybase Vaga 适用日常通用大模型问答需求,对于智能体解决复杂业务计算任务和定制化的算力需求可以使用更加高配的硬件(如 4090 或 4080super 组成的 8 卡服务器)来满足。创邻科技推出了一体机矩阵,高低搭配。国产华为 910B 系列也可以替代 4090 系列满足相同的算力需求,缺点是成本较高,货源相对较少。

多台各系列一体机组建算力集群可以高低搭配混合在一起组成分布式并行异构算力网络,这里的异构算力是指不同的机器上运行的大模型也可以不同,各台机器上的数据不用全部汇总到 1 台机器上,实现真正意义上的分布式边缘推理。「Galaxybase EI」(Edge Intelligence)系统就是创邻科技针对该应用场景推出的 AI 网络控制大脑,可以一体化的协同异构资源一起执行同一个或多个智算任务。
使用 Galaxybase EI 系统,企业可以购置 1 套 Orion Ultra 集群系统,外加若干套 Vaga 系列无 GPU AI-PC,由 EI 系统控制,既可以实现日常每个人独占的大模型使用,也可以在闲时或紧急任务需要时,调动所有异构机器一起完成需要大算力资源的大模型应用。以企业面临的复杂任务需要超长文本输入(即任务的背景信息复杂/任务搜索域巨大),但传统方法在硬件资源有限条件下无法支撑超长文本输入的挑战为例,创邻的 AI 智控大脑可以智能的分解、分配、调度、整合文本处理任务,突破百万级别 token 上下文处理上限,轻松实现按并行化的 AI- PC 机器数量进行准线性扩展的千万 token 级别上下文处理能力,使企业本地的海量数据都可以上传到大模型,支撑更为精准有效的知识问答与决策推理!
总体上,一体机主要是为了满足有私有化部署需求的场景,譬如内网数据不能传到公网等。这种情况下对终端客户而言,Galaxybase Vaga 系列产品解决了 GPU 买不到、买不起的问题,更快实现 AI 落地赋能;Orion Ultra 系列用 1/4 的价格实现了头部 8 卡 GPU 同样的性能和 5 倍的并发,性价比提升 20 倍,可以通过增加服务器台数实现算力的按需扩展;Orion X1 系列专门针对小型企业需求,降低初期投入成本,只需要 1 台 8 卡低配显卡(如 4080s)服务器,就可以实现大模型的部署使用;Galaxybase EI 系统则负责异构大模型算力与资源网络的管理,调度,使大模型应用执行具有确定性、可解释性,同时优化提升算力资源利用率。
英伟达(Nvidia)首席执行官黄仁勋提到,他希望通过新芯片、新互联、新系统、新操作系统、新分布式计算算法和新 AI 算法,将人工智能再加速一百万倍。创邻科技一直以来深耕分布式与并行计算领域,是国家「小巨人」企业,先后获得了百度、高瓴、腾讯、同创伟业、达晨等顶级资本的投资。创邻科技成立近 10 年来积累的分布式并行技术与系统架构能力成为了研发大模型一体机的核心底层技术积淀。
在 Deepseek 按下大模型发展的快进键之前,创邻科技已经聚焦软件驱动的大模型底层优化近 2 年时间。创邻依托的技术路线和 Deepseek 大模型有所不同。Deepseek 等大模型对于人类来说是「黑盒子」,这也是人们不能精细化控制模型的行为、需要海量训练数据和事件的原因。创邻的路径是「白盒」路径,把错综复杂相互关联、相互依赖的企业知识和资源,以可解释的方式组织在一起,完成资源调配与任务调位的可控管理。形象地说,如果现在 Deepseek 类推理大模型的内部逻辑主要是一个一个多轮多次的抽象的矩阵运算的话,创邻设计的路径是复杂而确定的生产资源网络(人、设备、数据、知识、流程、权限、制度以及它们之间的各类关联关系),同时允许因为关联的复杂性而涌现的非预设智能火花。
创邻科技的白盒设计具有它的先进性,在企业级 AI 应用中不可或缺。因为企业不可能盲目依赖一个不可控、有幻觉、没有确定性的黑盒子来做决策,更不可能完全把决策权给一个不可解释的黑盒子自动完成,尤其是各类核心业务系统、决策系统与企业级生产应用。这也是目前多数大模型应用停留在问答系统、许多已经建成的智算中心大模型问答服务调用低、利用率不高的深层次原因。
为了把大模型真正在企业业务中落地应用起来,创邻科技将多年沉淀的分布式并行技术、Graph RAG 技术、知识图谱技术与大模型相结合,推出了「算-调-用」三位一体的集成架构。底层的算力优化,使得在同等硬件下模型跑的更快,用分布式并行化的方式把「多个车道」的底层算力资源跑满;中层的调度大脑,使得跨机器、跨模型的分布式并行化协同与边缘推理得以实现,上层的应用创新,实现大模型应用的自主进化迭代与人类可控的精细化干预与控制。大模型安全、大模型可控是一个有关人类文明发展的重大议题,今年内创邻将发布相关上层大模型产品,全民共建,让大模型更自主、智能的同时,保证人类确定性的精细化可控。
创邻科技的核心团队由浙大竺可桢学院混合班几位同学们组成,他们早年保送进入浙大学习,毕业后出国深造,在海外工作、创业后带团队回国,带头人是国家级海外高层次领军人才,从 2004 年起研究分布式与并行计算机系统至今已经 20 多年,目前仍然活跃在科研一线。创邻会持续在新一代 AI 算力与应用生态中,发挥多年积累的技术优势,实现颠覆式创新与价值交付闭环两手抓,争取成为杭州的新小龙,聚有识之士共建 AI 未来。
1 中文中,1个token通常对应1.5-2个汉字。若以普通人500字/分钟(8.3字/秒)计算,相当于每秒4.2-5.5 tokens(8.3÷1.5至8.3÷2)


