

近日, 快手可灵 AI 正式面向全球推出「多图参考」模式。
近日, 快手可灵 AI 正式面向全球推出「多图参考」模式, 该功能能够理解和整合多个图片中的不同主体, 根据用户的文字描述, 创造性地生成融合视频, 进一步攻克了 AI 视频生成中的一致性难题。

目前, 全球用户均可在可灵 1.6 模型下, 使用「多图参考」功能。用户只需选择图生视频, 上传 1-4 张参考图, 框选图片中需要使用的人物、动物、物品或场景, 并通过「提示词」描述它们之间的变化或互动, 可灵 AI 即可结合所有参考内容并遵从指令生成视频。
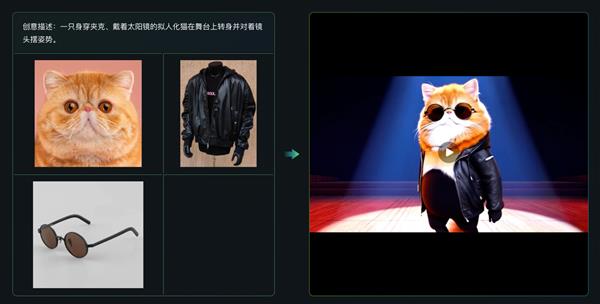
用户可以上传一张或多张同一主体 (人物、动物、影视角色或物品等) 的图片, 模型会以这些图片为参考, 生成统一风格的视频, 帮助用户在制作 AI 视频时保证多镜头中的主体一致。例如, 用户上传猫、夹克、太阳镜三张图片, 并输入提示词「一只身穿夹克、戴着太阳镜的拟人化猫在舞台上转身并对着镜头摆姿势,」随后进行生成, 就可以得到符合指令的视频。
此外, 用户还可以通过参考图来指定场景、服装和动作等, 让人物在特定环境中完成特定「演出」, 大幅提升创作的可控性。例如, 我们分别上传一个老爷爷、一杯咖啡、咖啡馆场景三张参考图片, 并输入相应提示词「一个卡通风格的老爷爷在咖啡馆里, 端起咖啡杯」来进行生成, 便可得到老爷爷坐在咖啡馆里喝咖啡的视频 。

同时,「多图参考」还可以支持不同角色之间的互动。用户可以上传多个人物、动物或者影视角色等图片, 并用文字描述他们之间的互动。例如, 我们分别上传小男孩、柯基犬两张参考图, 并输入提示词「一个可爱的小男孩在抚摸一只柯基犬」, 即可生成下图所示的视频。

此前, 可灵 AI 已在全球上线「人脸模型」功能, 支持用户通过上传多段视频来训练、定制人脸模型, 并参照该人脸模型继续生成视频内容。作为业内首个视频模型定制功能,「人脸模型」创新性地满足了用户创作多个包含同一人物镜头的需求。
随着「多图参考」功能的推出, 可灵 AI 进一步解决了视频生成中的一致性难题, 帮助用户充分发挥创造力, 自由组合各种图片元素, 打造独特的创意场景, 探索更多可能。
来源:互联网


