

以语音助手切入的多模态,是提高用户渗透率的一种尝试。
对话|张鹏
文|黎诗韵
编辑|靖宇
和多数人一样,在看到 OpenAI 最新发布的「AI 智能助手」GPT-4o 时,MiniMax 创始人兼 CEO 闫俊杰的第一感觉是「惊艳」。他也为那些演示效果着迷,如丝滑的语音交互、实时的视觉理解、语言捕捉甚至包括了「呼吸声」。
作为中国第一梯队的大模型创业者、OpenAI 的最重要追赶者之一,他迅速看穿了这场「魔术」背后的手法。在发布会结束两天后,这位以神秘、低调著称的从业者,罕见地做客极客公园直播间,和极客公园创始人、总裁张鹏进行了近 2 小时的实时访谈。
从这场发布会切入,他聊到了技术和成本、行业赛点、开源与闭源之争、投流和 PMF、超级产品等关键问题。
在他看来,这次 OpenAI 展现的技术难度并不高(比如语音模型处理速率更低、容易对齐到语言模型,实现丝滑语音交互)。使他感慨的是,这位对手在行业最重要的使命上迈出了重要一步——那就是让AI为更多普通人所用。
他说,GPT-4o 本质是多模态(文本、语音、视觉)的进步。而他很早就意识到,大模型在多模态的每一次进步,都会带来用户体验的提升、获得更高的用户渗透率。比如,当 GPT-4o 拥有更丝滑的语音交互(延时缩短、增加情感等)后,它就会走向更多人。
这也是他于 2021 年底创立 MiniMax 的初衷。彼时。ChatGPT 还没有出现、业内也没有人相信大模型。促使他一定要创业的动力是,「把人工智能做成通用、服务大众这件事是很重要的。」
在这个目标驱使下,MiniMax 是行业少有的同时做模型、产品的公司。目前,MiniMax 是国内 AI 产品做得最出色的公司之一。其产品主要分为两类:一是「星野」代表的娱乐类,对标 Character.AI,目前处于国内领先位置;一是「海螺 AI」代表的效率类,对标ChatGPT,尚在起步阶段、但是他目前最看重的产品。
GPT-4o 的发布,让他更明确了「海螺 AI」接下来的研发方向。他说,下半年的目标是,要把过去彼此独立的多模态大模型融合在一起。并且他认为,这会是未来行业的「必答题」,效率类产品必须跟上。不过他认为,从长远看效率类产品的本质方向,仍然是要提升底座语言大模型的上限。因为其最重要的指标是用户对回答的满意度,而现在连 ChatGPT 的回答满意度都只有 60%。
尽管 AI 在过去一年多引起了全球广泛关注,但它距离为普通人所用的未来还很遥远。闫俊杰做了一个演算,目前国内最好的效率类产品DAU只有 400 万、国外是 1000 万,这意味着 AI 在移动端的渗透率可能不到 1%。从业者们要做的努力还有很多。
用户满意度和渗透率、以及背后需要的技术进步,似乎一直是他思考的「第一性原理」。而当我们谈到成本、商业化、行业竞争等等关键问题,他的答案都围绕这点展开。比如他说,「投流是因为技术没有拉开足够差距」、「搞不懂 PMF,其实有了用户时长就会有商业价值」、「如果创业者没有做出足够创新,这件事就该大厂干」……在这场对话里,我们能看到这位技术向 CEO 难得的「简单」、少见的「坦诚」。
那么,最终我们何时能迎来大模型时代的 Super App、真正让 AI 普及大众?他说,也许目前的产品都看不到这个可能,但这并不是一个重要的问题。原因在于,AGI 的路很长,很多事情无法现在就看清,没有必要给自己这么大的压力。还是那个回答,做好技术和产品,有能力跟上一代代的创新,最终才有机会看到那一天的到来。
以下是这次直播对话的实录,经极客公园整理后发布:
谈语音助理:效果惊艳、能提升用户渗透率,且在技术上并不难实现
张鹏:你应该也是非常详细关注了 GPT-4o 和谷歌I/O的这两个发布会,它们的风格其实挺迥异的,你个人对哪个印象更深?更喜欢哪个?可以分享一下原因和理由。
闫俊杰:一方面,我自己其实是一个用户,会每天使用这些 AI 产品。另一方面,我自己又是从业者,所以有很奇怪的两种不同感受。
看 GPT-4o 的发布会的时候,作为用户来说,我觉得非常惊艳。特别是那两个演示,一个是(AI 听懂了)呼吸声,一个是拍照做一些事。我当时觉得为什么人工智能可以变得这么流畅,大家都觉得实时的语音交互是第一次有人实现。这个事确实很成功的,非常显然 GPT 发布会的风口和传播量是大于谷歌的。用户肯定觉得 OpenAI 的发布会更震撼。
不过发布会那天晚上,我就开始想这个东西到底怎么实现的。大概想了半个小时之后,就觉得实际上是很直接的事。为什么?原因是,说话是比打字要慢很多的。比如说现在正常的语言模型,基本上每秒可以处理的 token 是十几个到二十几个量级。但是说话其实每秒只能说 3-5 个字,大概只有 4-5 个 token。所以语音的速度是远远慢于现在标准的语言模型的处理速度的。
这个意思就是说,只要把语音的模态——就像之前做图片跟文本一样,只要把它对齐到语言模型上,把它改造成一个成纯流式的交互,这件事改造起来非常自然。
所以我觉得这件事体现出来两个事:第一,OpenAI 还是能够从非常底层思考这个事。第二,这个事的技术难度其实远小于 Sora 或者一开始 GPT-4 的技术难度,这就是我看 OpenAI 发布会的感受。
张鹏:那看了谷歌的发布会你有什么感觉?
闫俊杰:谷歌的发布会不是看的直播,而是第二天看了完整的两个小时视频。它最前面是 DeepMind 负责人讲了很多技术的部分,这部分就很像是一个中年男人拖家带口来搞科研,一定既要满足股东、又要满足用户、又要满足市场对谷歌的期待。
张鹏:还得不能让社会质疑你有 ethic(伦理)的问题。
闫俊杰:对,相当于画了很多目标,几千人的研发团队大概做了一年,做出来了很多东西。每一点应该都不是最好的,但是能同时做这么多东西,从芯片到产品都做,可能也只有谷歌有这么多的研发力量能做。
但是我比较震撼的是它的 AI 搜索。AI 搜索在过去几个月很火,海外有 Perplexity,包括 ChatGPT 在内,以及国内很多助手,大家都会做搜索,甚至声称替代了传统的搜索。坦白说,我觉得目前这些产品的搜索和谷歌展示的那一套 AI 搜索,还是有非常大的差距。
因为我觉得里面非常核心的东西,可能只有谷歌才有。比如很多实时的本地的信息,这些信息对一些高价值的场景其实有非常大的价值。如果我是用户的话,我其实非常愿意用这样的搜索,这种体验绝对不会是在 ChatGPT 里外接第三方的搜索引擎就可以实现的。坦白说,我觉得这是谷歌真正的壁垒。
其次,目前大家用的其他的 AI 搜索产品里面,只有单步的推理,谷歌展示了多步推理,这对搜索体验的提升还是非常大的。这个事谷歌也是第一个做的。它本身不难,原来的语言模型能够支持就好了,但是说明谷歌已经想得非常深刻了。
最后,可能是谷歌独有的优势。实际上包括 OpenAI 在内,几乎所有公司的视频理解都做得比较一般。甚至 GPT-4o 里面展示的东西,它的 Camera 其实处理的也不是 video,而是静止的图像。真正能够做到非常流畅的视频理解,效果比较好的,好像只有谷歌。Gemini1.5 做的相当不错了。
我在想为什么这件事这么重要呢?为什么谷歌非得做这件事呢?其实也可以理解,原因是谷歌有大量 YouTube 的视频,但是这些视频无法被展示出来。因为之前的搜索只能有一个标题,或者非常简单的标签。现在这个技术,就可以把这些视频加到搜索的结果里面去了,这是非常独特的一件事。
总体来说,我比较受震撼的是有了 AI 之后,真的可以把搜索这件事有质的提升,并且这件事谷歌已经走得非常靠前了。
张鹏:感觉我们大部分都是观众,看完发布会的「魔术」都「哇」一下,但你是「魔术师工会」的,你看完了会琢磨一下这个「魔术」怎么实现的。比如语音这件事看起来很厉害,但没有想象中那么难实现。所以有人评价说,OpenAI这次主要是工程上的进展,它选择了一个明确的目标、甚至可能针对发布会的场景做了很好的想象,然后它的工程能力配合技术能力、完美的把这个点打爆了。而不像上次 Sora 那样是技术的本质变化。这么理解对吗?
闫俊杰:可能不同的人对系统、算法、工程的理解都非常不一样,我说一下技术上的理解。
虽然我也不知道 OpenAI 具体是怎么做的,但我猜 OpenAI 的语音技术可以分成两步:第一,用大模型做语音的合成。第二,把大模型的语音合成和语言模型合在一起。第一步其实去年有了非常多进展,但问题是在做交互的时候,要先把声音变成文字、再用语言模型生成回复、再用这个模型来跑一遍。
张鹏:当时不是端到端的实现,而是要分几步。
闫俊杰:对,这个会造成延时和信息丢失。这次 OpenAI 就更进一步,直接把语音模型和语言模型合在一起了。
这在技术上是比较容易做的,因为声音和语言模型都是 Transformer 的模型,本质上就是把声音模型的 incoder(编码器),对齐到一个语言模型上去。这个事在图片里面已经发生了,现在只是把图片换成了声音。而且因为声音的处理速度远低于文字处理的速度,所以改造成流式是非常自然的。
这带来的结果是,原来 ChatGPT 的语音交互、包括海螺 AI 的语音交互,大概延时会有两秒。现在纯流式了,延时只有 300 毫秒,就是说一个字的时间。
张鹏:所以这种语音技术路线其实并不难、而且很早就被证明是可行和明确的,这是否意味着它不会是OpenAI的独门技术,而是可以迅速扩散到更多的公司?
闫俊杰:我觉得如果一个公司或者组织,它之前能独立做好语言模型、并且能独立地做好利用这种 LLM 方式做声音的模型,如果这两个都具备了,把它合在一起是相对比较轻松的。不过这背后还涉及到很多工程链路上的优化。
但比较核心的还是你的目标是什么。比如 OpenAI 为什么要把语音延时降到 300 毫秒,本质上是因为在移动端,每当你降低延时、对用户体验就会带来特别大的提升。为什么线上会议没法替代线下见面,核心就是它有几秒的延迟。而延时优化的极限就是一个字的时间,300 毫秒,你在这个目标下最后就会推出来最合理的技术路线。
张鹏:延时的问题我很有感触,之前有声音赛道的创业者跟我说,如果延时超过一秒,用户就会发现对方跟自己不在一个地方聊。所以语音助理没有延时之后,你感觉它从云端,走到了你房间里,这个感觉给人的冲击感是非常强的。它对用户体验的提升有多强?语音是否会成为主流的交互方式?
闫俊杰:过去一年非常明显的变化是在车里面,你可以看到新能源车里的语音渗透率是显著变高的,这说明在一个场景里,如果你能够把语言的交互做得非常好用、且有实际价值,它的用户渗透率就会变高,至少在智能车舱里面已经实现了。这个事在现实生活中也会是一样,这也是为什么 AI 公司会越来越重视声音交互的原因。
过去一年大模型虽然是非常热的词,但现在全球每天使用 AI 产品的人只有四千多万,而这四千多万里有三千多万在用 ChatGPT,而这三千多万有两千万是用 Web、一千多万是用手机。而现在全球每天使用手机的人可能有 4 亿人,所以 AI 在移动端的渗透率可能不到 1%,这是非常低的数字。真正主流的产品,比如说短视频、或者长视频、或者社交,它的渗透率应该都是 50% 以上。
我觉得未来有志于做 AI 产品的公司,一定要思考一个逻辑,那就是怎么让用户渗透率变高。其实唯一的方式就是让更多的场景可用、让更多的人可用。我觉得声音应该是符合这个趋势的,它可以让一些不方便打字的人进来、并拉来更多场景。这是 AI 公司提高渗透率的一种努力。

在 OpenAI 发布会上,研发人员与 GPT-4o 对话 | 图片来源:OpenAI
张鹏:你觉得它是会增加存量用户的黏性、还是获取更多增量用户?
闫俊杰:这两个事都可能会发生。我们发现很多场景确实只有语音才会发生,举个例子,比如说在海螺 AI 里面,很多家长会让它给小孩讲睡前故事。这显然扩充了使用人群。
再比如,我们发现有很多用户会用它来学英语口语。从这个维度上来说,它应该是提升了用户的活跃。还有我自己亲身的例子,我今天春节回到老家看我外公,他已经 80 岁了。他在很破的安卓手机上装了海螺 AI,会跟它打很久电话、讨论历史人物。之前你很难想象一个 80 岁的老人会这样用 AI。
而他们在用这个产品的时候会真的把 AI 当成一个人,比如他会说你(AI)声音能不能大一点,其实潜意识里把它当成人了。
这也是我们为什么那么相信通用智能的原因,它就是服务普遍人的东西。问题是整个行业的渗透率确实没那么高,更简单的交互是很重要的一方面。
张鹏:你说过自己很早就坚信多模态,是因为产品每扩展一次模态、都能扩展一批新的用户。你预测ChatGPT改善语音技术之后,它的DAU、用户时长这些数据会有什么变化?
闫俊杰:实际上现在没法猜,因为它还没有上线。我觉得使用时长会变长,但是用户渗透率会不会有显著的变化,我其实比较怀疑。
张鹏:语音交互确实对人有门槛的,很多上一代做语音交互的朋友们复盘过,大家打开一个语音助理之后会突然不知道说什么,然后就停了,这件事跟技术其实没有关系。它其实需要用户有比较强烈的目标和意愿去用。
闫俊杰:对,我觉得对年轻或者比较年长的用户会更友好,对中间的用户反而不会。原因是因为,愿意使用 AI 的人、或者听过 AI 的人,大概率至少试用过一些东西了。
谈行业赛点:多模态融合是大模型行业「必答题」,决定效率类产品的成败
张鹏:你自己也在大模型领域创业,各项技术能力都在主动跟OpenAI、谷歌做对标。看完这两场发布会之后,你感到的更多是一种兴奋,还是一种挑战?
闫俊杰:我觉得有人跑在你前面是好事,这说明这个行业上限远远没有到。
我个人是非常期待 OpenAI 会出 GPT-5 或者其他的东西,即使作为一个业内人士,我也是希望 OpenAI 进步速度能保持这么快。反正也没有竞争,实际上没有任何的竞争。但是这不是因为不想跟他们竞争,是他们太强了,构不成竞争。
至少目前,真正把算法汇成产品,真正开拓 AI 行业边界的,主要还是 OpenAI,如果他们能够非常快地开拓 AI 的边界,至少说明 AI 的用户渗透率是有底层动力的,而且这个动力可持续的。
OpenAI 可能比中国公司多 10 倍的研发资源,如果他们都做不出来创新,这才是这个行业比较可怕的一件事。
张鹏:你有方法、有路径,有计划,未来可以在你们的产品里见到跟OpenAI今天类似的用户体验吗?大概多长时间可见?
闫俊杰:首先我觉得这个事肯定可见的,虽然他们怎么做的我不知道,但是我觉得我刚才的分析应该是对的,至少那种方法可以实现,至少它是有一条比较明确的路径。
其实对我来说,主要的挑战不是语音模型,主要还是把语言模型做得尽可能好。真正的原因是因为,现在的多模态实际上还是以语言模型作为核心的。今年我们在做上一版 ABAB6.5 的时候,我们其实把万亿量级的 MoE 这件事做通了,这还是个语言模型。
另外,我们在去年的时候,每个模态都是独立的,虽然它们有同样一套框架、里面都是 Transformer,代码也是差不多的,但是它的数据和模型是独立的。现在我在设计下一版的模型,我们下半年的核心考虑是如何能够能有一个上限更高的语言模型,以及把这些不同的模态合在一起。
我们还没有完全设计完,还有很多的实验需要做。但是它基本上已经是可见的东西了。接下来这个模型会分成两个阶段:第一,设计阶段,有很多假设,你要做很多实验验证你的假设。第二,假定,你认为你的假设验证得差不多了,把这些东西合在一起,最后训练这个模型。
这里面的 trade off(权衡)是说,你的这些假设,或者你设计的这些预测实验,到底要做到多好?这是我们正在经历的一个事。
MiniMax 旗下的效率类产品「海螺 AI」|图片来源:MiniMax
张鹏:最近听到谷歌提的比较多的是One network Moti-modelity,多模态是在一个神经网络里实现的。现在MoE 在训练万亿大参数的模型上是非常有效的方法,但下一步如果做多模态融合,方法上会跟以前有什么不一样吗?
闫俊杰:这个是两个维度,第一个是中间这步都是一堆巨大的 transformer,为了提升效率,不管训练效率还是推理效率,大家主流的选择都是一套 MoE,比如 GPT-4。据传 Gemini-1.5 也是长这个样子。如果你做一个大概几千亿参数的模型,基本上这就是必然的选择。
第二个,你有不同的模态,怎么样能够合到这个大的以 MoE 为基础的主干模型上,这就是多模态。现在已知的东西是,怎么把视觉的理解跟主干模型合在一起,比如说像 GPT-4v,你先有一个巨大的 MoE,再把视觉的东西对齐,就可以有比较好的视觉的理解。
未知的东西有这么两个:
第一,GPT-4o 里面展示的,把声音也对齐到里面去,这是 GPT-4o 干的其中一件事。
第二,生成的这部分,比如说图片的生成、视频的生成能不能合进来。至少现在,视频是没有实现的,比如说 Sora 是独立的模型。为什么会这样?原因是视频的 tokenizer(标记)是有损的压缩,基本上要通过 diffusion(扩散)才能恢复到一个比较正常的状态,现在还没法整。当然会有很多人做,可能明年才会整合一起。但是视频的生成目前还不知道怎么整合的。
图片的生成我不知道,比如说在上一代 DALL-E 3 的时候,其实也没有整合在一起的,也是独立的模型。但是这次看 GPT-4o 的话,我感觉它们似乎整合在一起了,但是我不是特别确定。我觉得基本上底层的技术就是这样了。
张鹏:那么紧接着多模态统一融合的能力,会不会成为下一个阶段大模型领域、尤其是中国的创业公司们要去提升的目标?这是不是所有人都必须要跟上、必须要解决的问题?
闫俊杰:我更觉得是必须要做的事。其实这分两个产品,目前AI产品有两种,一种是满足娱乐需求的,一种是满足效率的。娱乐的不说了,是运营的属性、产品的属性,更加偏综合产品能力的事。
偏效率的一定是需要做(多模态)的,因为从历史上来看,所有效率的产品基本上最终大家只会用最好的。比如说有两个产品,一个可以做很多东西,一个只能搜文字,那大家一定会用那个啥都能做的那个产品。当然这个前提是说,这个(多模态)赛道是存在的。关于这个赛道是不是存在,其实也是需要很多努力的。
张鹏:可不可以理解为 Sora 是「选答题」、可以不选,但是多模态的统一融合是「必答题」、如果答不好就会出局?
闫俊杰:我觉得你这个概述还是挺好的,之前没想到这样,确实更像是一个必答题。
Sora 这个东西其实有不同的用法,比如说有 PGC 的用法、作为工具属性的用法,也有 UGC 的用法、会涉及很多产品、内容的东西,不是 AI 都要做的东西。
但是在工具类、效率类、助手类的产品上,只要有公司做出来(多模态),其他公司必须跟上。因为基本上就这么点技术。
谈生态:「智能语音助理」争夺战,巨头和创业公司是复杂的竞合关系
张鹏:这次我们看到语音助理这个事,苹果想用到 Siri 里、谷歌想非常深层地用到安卓体系里,似乎它会是个很重要的入口级的东西,这个事最终会是巨头的 Game 吗?创业者还能干吗?
闫俊杰:首先,这个产品的所有用户体验几乎都来自于模型的能力。它不太取决于产品是巨头的产品、还是创业公司的产品,只是取决于背后是什么样的技术水平。它考验的是你能不能做出一个体验最好的模型。这里面涉及到你的技术模型怎么做、怎么做很好的对齐、怎么优化你的延时,怎么提高工程的效率、怎么降低计算成本等等。
其次,在商业层面,这个产品背后肯定要消耗成本。因为现在的AI产品跟早期移动互联网产品的本质区别是,以前我们不需要考虑每天维护用户的成本,现在我们都要考虑。所以这一代产品怎么变现是比较直接的。而手机上产品的商业价值有多大,几乎取决于它有多长的用户时间,因为用户时长总是有标准化的变现手段。
这样的产品,假设它能做到大部分的需求都在里面解决,比如说当我想要搜索的时候,我不需打开百度了。或者我需要看一个视频的时候,不需要在抖音里看了。只要它占有用户足够长的时间,那它的商业化效率就是足够高的,它的商业化跟时长是成正比的。
这个事最终会变成,产品的竞争力取决于技术能力,商业竞争力取决于你占有多少用户市场。
张鹏:我再具象一点,苹果属于完整的从硬件到软件的掌控者、安卓在操作系统上有天然的优势、OpenAI是新型的基于大模型能力的创业公司,如果未来这三家公司都在抢占语音助手这个最关键的入口,谁更有可能是赢家?创业公司能赢得这个位置吗?
闫俊杰:我觉得这里面有各种各样的博弈、竞合关系,在搜索里已经发生了。我们能看到苹果里集成了谷歌的搜索,谷歌每年给苹果很多钱,为什么谷歌愿意付钱?显然因为谷歌在苹果里做搜索的商业价值,要大于谷歌自己付的钱了。
但是我觉得不管怎么样,如果看第一性原理的话,那在这里面如果谁能把东西做出来、并且把体验做得显著地好,那至少在里面你应该会有一席之地。
这件事我觉得更利好于拥有设备的公司,为什么?比如说我买一个小米的手机,只要给小米付一次钱,之后这个小米手机创造多大的价值,其实都跟小米没有关系了。唯一有关系的是,小米商店里面的分发里面会有分成,其他的基本上没有关系了。
张鹏:也有一些负一屏的内容广告,都是比较薄了。
闫俊杰:负一屏的内容水平显然是没有抖音或者小红书高。其实手机提供了很多用户时间,比如说我在小米上装了一个抖音,一个用户在抖音上花了很多时间,但所有的钱跟小米一点关系没有,都被抖音转走了。
我觉得一个比较强的 AI 助手的好处是说,它确实能够让手机的操作系统这层占领很多用户的时间,因为可以满足很多多样化的需求。这个事相当于是说它其实是把很多价值从 APP 里拉到手机上。
张鹏:最近我们也看到传闻,苹果跟OpenAI有可能在智能助手这个层面产生合作。所以按照你的推理,一家在大模型里做的非常优秀的公司,和一个对生态硬件、软件有掌控力的手机巨头,最终大家合在一起、在未来的生态里产生新的价值分配,这是符合逻辑的?
闫俊杰:对,实际上就是用户时间的分配,而这又考验背后的技术和产品能力。
张鹏:反过来说,如果 OpenAI 没有跟苹果合作,而是成为最强的 Super APP,作为独立的力量去挑战现有的生态、甚至对原有价值链进行重构,你认为存在这种可能性吗?
闫俊杰:这主要看它的规模。现在 1000 万 DAU 的 APP 显然不够格。到 Mata 这种 10 亿 DAU 量级的,估计会有本质的变化。但即使是OpenAI,距离这个也有 100 倍的距离。
张鹏:现在想着做所谓大一统的 Super App、超级入口还是很难实现的,今天更现实的是怎么把DAU从一千万涨到 1 亿,这也是 OpenAI 很头疼的事。
闫俊杰:我猜这也是它们为什么这么在意语音的原因,因为这个东西确实有可能会提高渗透率。
谈技术路线:投入通用基础大模型、打造通用产品,能看到真正的未来
张鹏:前段时间在整个创业者的圈子里,大家围绕基础模型和开源模型争论很大。本质上是说,你要么自己做一个智能引擎,要么就买一个自己改。其实模型、产品双轮驱动,自己同时做基础模型和产品,滚动着往前走是最好的。但很多创业者说这风险很大,模型的一次迭代跟不上、或者产品 PMF 的一次失败,就不行了。你怎么看这两种路线?
闫俊杰:我觉得这本身是风险很大的事。先不说同时做模型和产品,只做模型、或者只做产品,本身就是风险很大的事。
张鹏:创业其实就是生死游戏。
闫俊杰:对,确实是很残酷的事。比如我们看美国的公司,OpenAI 是都做,Aanthropic 之前只做模型、昨天他们把 Instagram 的 CTO 也招过去了,我不知道是不是它们也有可能做产品。我觉得至少对做模型的公司来说,自己做产品几乎是必然的选择。我们算是比较坚决的,有些公司后面变成这样了,这是必然的。
反过来,其实对做产品的公司也是一样的。比如说我们国内的开放平台上,有很多做产品的公司和客户,其实规模还挺大的,大概有接近一千家。这里面有大的公司,也有小的创业公司。其实坦白说,对所有这些公司来说,如果它们的产品得很大,他们也希望自己掌控模型的。这也是必然的一个路。
所以这里面核心的考虑还是说,如果你觉得这件事是对的,本质上是说你现在有多少资源、最大化优化你们想优化的目标。对我们来说,我们的目标是要最大化地优化用户体验,那我们觉得这两个东西(模型、产品)都是重要的,只能两个东西都做,才能最符合我想优化的目标。
不同的人定义的目标不一样、路径不一样,就会出来很多不同的公司。
张鹏:所以产模一体归根到底是我们追求的最终目标,只是很多人基于今天已有的资源,会发现烧钱太高、风险很大,但这只是阶段的选择问题。
闫俊杰:还有一个更底层的原因。举个例子,假设有个需求要满足,而这个东西需要通过模型来满足——那如果是(模型和产品都在)一家公司,你的路径是优化这个业务指标就可以了。但如果(模型和产品是在)两家公司,你们干的事是把这个指标转成一个对模型的要求,让给你提供模型的公司优化这个指标。
这中间本身损失了很多信息,并且让周期变长。这个事一定不是最大化业务指标的方式。
当然这个事上,微软例外。核心原因是,微软的这些场景,Bing 的搜索、还有 office,其实都是一些能够变得非常标准化的东西,基本上主要依赖于模型的通用能力。OpenAI 的通用模型是最好的,那就可以给这些产品用。在这种情况下(模型和产品分开)是合理的,但是大部分情况下不是最优的选择。
张鹏:你提了一个非常好的问题,就是我们到底是要根据模型能力造产品,还是要根据产品目标去改模型?我打个比方,如果模型是一把枪,产品是靶子,我们今天到底是要造更通用的机关枪、在更多领域命中靶子,还是应该造一把高精度的狙击枪、就打中某个具体的靶子?
闫俊杰:其实这个事背后有一层含义,咱们讲这个时间点,AI 背后是有一些技术红利的。这个红利是说,全世界有这么多聪明的人、这么多资源、这么多社区在做这件事。这件事的价值或者能力远大于单个公司,也大于 OpenAI 的,显然也大于任何一个中国的创业公司。
所以一家公司的研发水平不是一家公司封闭做出来的,而是这家公司的自身能力加上整个行业整合出来的。只是不同公司利用的效率不一样。包括 OpenAI 在内,它们很多的东西不是原创的,可能是谷歌做出来的,但是它们把它很好的整合在一起,扩大规模,就变成现在的状态。
其实把模型做通用这件事,是一个比较容易来吸收到整个社区进展的途径。这件事本身是有巨大的红利的。
张鹏:今天你应该站在那个位置上,把更多的能力拿出来,让更多的人跟你共创,也许是用户、也许是产业里面的其他创业者兄弟们,OpenAI有这样的感觉。但如果今天你只是做某一个产品、维系你自己的「菜园子」,你可能失去了世界与你共创的机会。
闫俊杰:客观的说不是世界与我们共创,是我们与世界共创。
张鹏:我看 Sam Altman也不断提醒,大家不要基于今天模型的一些具体问题去打补丁,这其实是浪费时间。因为技术在滚滚向前,你在这个时空刚把补丁打完,这件衣服可能都已经换了,会出现这样的问题。
闫俊杰:客观上说能够做什么产品,其实是由技术的周期决定的。
比如说目前这一代,我们见过的所有产品基本上是以文字的交互为主,产品的功能基本上是助理这个层面的。不管是娱乐还是效率,基本上都是 copilot(辅助助理)这个框架。只是不同的人基于不同的理解、不同的资源、不同的团队,组成了不一样的东西。
假设我们有更好的模型,能力比现在再显著地提升,比如所有的测试都可以做得非常好,它可以独立来工作了,就不是一个 copilot、可能是一个 auto-pilot(全能助理),这显然会产生更多完全不一样的产品形态。
但是这个东西不是产品设计出来的,而是当你把技术 Push 到某一个阶段的时候,这个产品自然就清楚了。
谈成本:技术成本两年内可能降 100 倍,这比探索技术上限容易多了
张鹏:我想把话题延展到很具象的东西,前些天我跟投资人算了算账,今天千万级DAU的产品,恨不得一天花掉 200 万的成本,很高的。比如今天 GPT-4o 如果容纳了更多用户、获得了更大的用户粘性,它每天的成本得有多高?你肯定掌握一些成本结构的判断,能不能帮我们算一算?
闫俊杰:其实语音比文字便宜的,因为语音慢。比如文字一秒要生成 20 个 token,但语音一秒只有 4-5 个 token。而且人听的时候也慢,我看一千个字只需要一分钟,但是我听一千个字应该是很长的时间。
所以假设使用相同的时间,语音其实更便宜的。
张鹏:这挺反常识的。
闫俊杰:你觉得声音更贵,其实更便宜,这是第一点。
第二,优化或者降低成本一直是学术界非常经典的研究领域,很多年前我自己也在这个领域做了很多工作。但它实际上不是业界最高端的领域,最高端的领域一定是说如何拓展技术的边界。
一旦你能够拓展技术边界之后,怎么把成本降低 10 倍这件事,其实从最早的机器学习时期,比如我当年读博士的时候,到 2012-2022 年这 10 年用 CNN 来做(卷积神经网络)的时代,怎么来量化、减值、增流是有一套非常标准的 pipeline。
在 Transformer 这一代里面,其实也可以复用上一代的 pipeline。比如说做量化;比如说当你有一个非常长的 context window(聊天框)的时候,如何做缓存,效率更高、时间更低;比如说如何优化你的 attention(注意力)……有很多方法来做这件事,这其实是没那么难的东西,你只需要把每步做得足够好,拼在一起就会带来很大的变化。
张鹏:也就是说,相比于探索新大陆,现在掘地三尺把矿挖出来其实挺容易的?
闫俊杰:这个事我们想一下就知道了,比如说去年 3 月份刚有 GPT-4 的时候,那个时候又慢又贵,但是我们现在其实看 GPT-4o,包括之前的 GPT-4turbo,又便宜又快,效果又好,这只是过去一年发生的事。价格可能降了 10 倍,但实际上 OpenAI 比这个价格的降低还要更多。
我们大概算过,如果有两年的时间,成本可以下降近 100 倍。其实我觉得,技术的上限这件事相对来说没那么确定,需要更多的探索。但是成本下降这事,一定是有办法的。这个事在学术界已经发生了三次了。
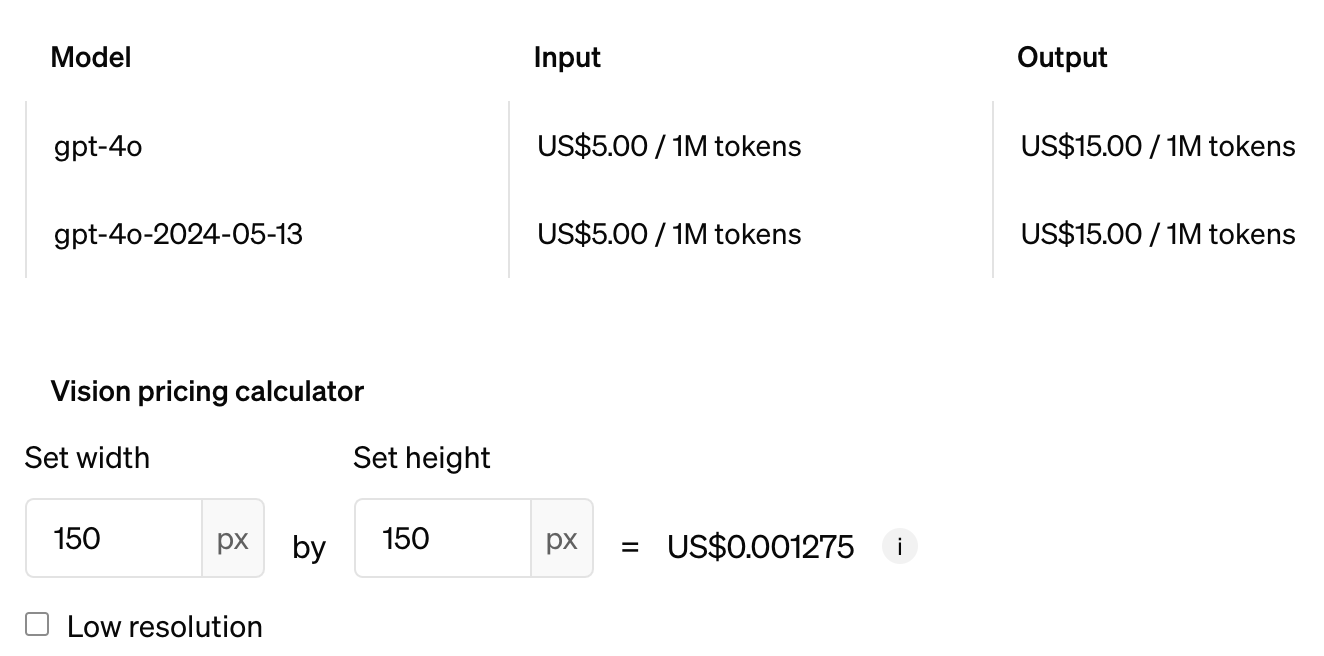
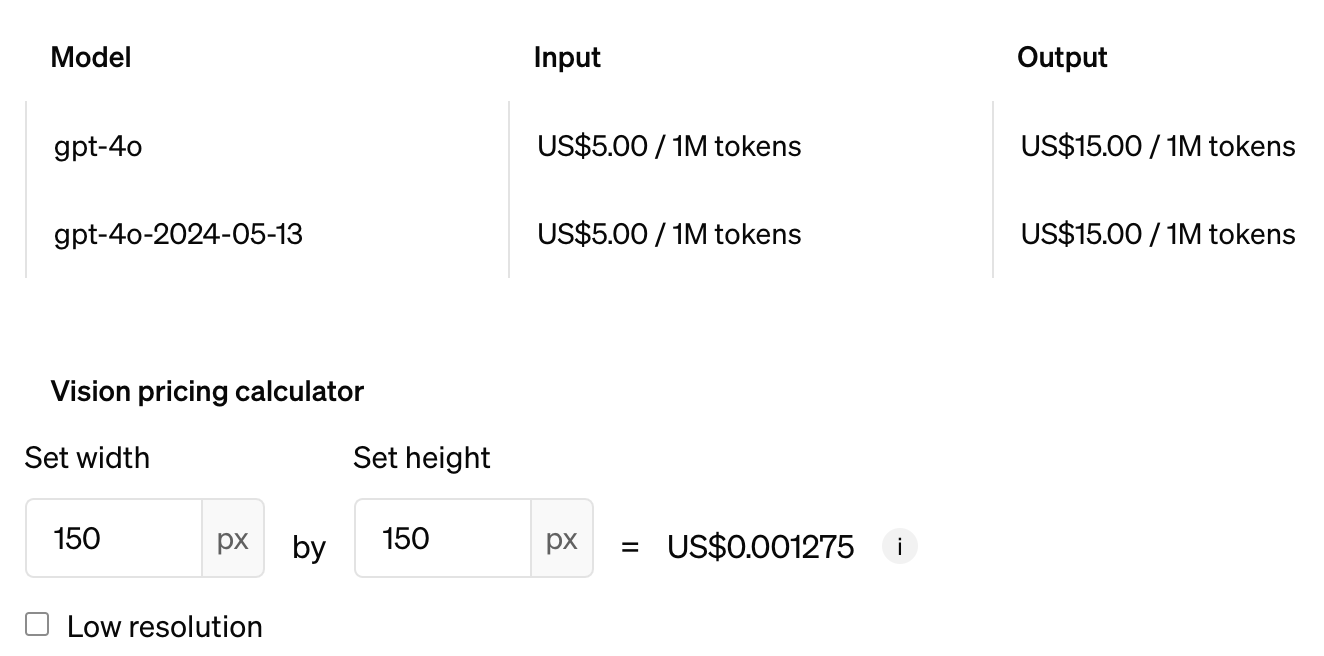
GPT-4o 成本|图片来源:OpenAI
张鹏:今天有的人在拼命地优化技术成本,有的人在拼命提升模型能力、想做到最 top,在你看来后者是不是更重要?
闫俊杰:我觉得从结果上来是这样的,但是从过程上两个事是相互转化的。这个其实是大模型里面一个非常重要的规律是,效率跟效果其实可以相互转化的。
假设训练精度一样,而你的算力是别人的 1/10,这意味着你能把效率做得很高,那你一定是能够把模型的上限变得足够高的。或者反过来说,如果你想要能力达到那个足够高的上限,那你一定只有把效率变得非常高,这个事才有可能。
所有人的资源都是有限的,一定是你的效率足够高、你的上限才能更高。实际上并不是我先冲到边界后再来做优化,实际上两边是要一起做的。
这也是为什么大部分研发越往上越难的原因,它要求你综合考虑。
张鹏:所以 Sam 说「给我多少万亿、我就能把 AGI 迅速实现」这种话,是不是太不现实了?
闫俊杰:如果类比的话,比如台积电现在是 7 纳米,那他接下来肯定是 5 纳米、3 纳米、2 纳米一代代往下做。他不可能把 5 纳米、3 纳米都跳过了,突然间说自己能做到 2 纳米。我觉得这个不太对,你很难把中间几步跳过去。
张鹏:远大的目标还是要一步步走,不能奢望直接通向目标,这也是创业的本质。
闫俊杰:当然可能它们太强了,我没有理解它们的精髓之处。不过正常情况下应该是这样的。
谈投流和 PMF:国内 AI 产品不得不投流,还是技术没有拉开足够差距
张鹏:说到成本,前段时间我们看到,业界AI 产品都开始投流了。我感觉以前移动互联网时代,大家好歹是产品达成了 PMF 之后以后再投流放大,而现在产品需要花钱来测 PMF。一方面整个中国互联网流量板结了,都在巨头这。另一方面 AI 的能力有限,没有办法直接推到用户面前。这种投流导致的 PMF 成本上升,对这一代 AI 创业会不会是很大的挑战?
闫俊杰:我们在这个事上吃过亏的。你发现这个事在中国,和在美国非常不一样。比如美国的产品,ChatGPT 显然没有投流的,最早期的 Character.AI 也是没有投流的。偏工具的东西,比如像 Midjourney,它显然也是没有投流,更多的是运营。但是反过来说在中国,基本上所有的产品都会投流,这其实是非常明显的差别。
相当于说,美国公司更多的是靠技术能力和产品能力,大家都不会投流。但是这背后其实也是有代价的,代价就是美国的研发成本还是会非常高的。在中国反过来了,中国工程师的红利和产品的红利相对比较充裕的,但是中国的流量是头部聚拢的。
但是投流更底层的原因还是因为,目前为止在助手类的产品上,没有哪家公司能拉开差距。大家在同一个维度上,产品比较同质化,技术能力相对也是比较同质化的。为了获取更多用户,只有靠投流,这是目前这类产品的困境。
这个东西大家都会有一些解释,比如说有一种人认为获取 query(用户询问)是比较重要的事,如果把 query 本身的价值换算成钱的话,投流是值得的。就看你怎么看这件事了。在技术不突出的时候,这个东西就是没办法。
张鹏:我觉得你选择了某种「简单」,就是把技术做到最好、绝对的领先,这个世界也会变得简单。如果你不能在这件事上简单地领先,世界就会对你变得复杂。你也不会省下多少成本,没准成本更高,无非是押在这还是押在那。
闫俊杰:对,所以我们没有认为要花钱买用户的 query。
我觉得 PMF 这件事是这样的,一般创业的时候要写 BP(商业计划书)讲你的 PMF 是啥,我们其实一开始没有搞懂这件事,目前也没有写。其实我觉得可以做一些假设:核心就是类似这种产品,只要有用户时长就能变现。本质上,PMF 是以用户时长来量化的,这是比较标准的东西。目前这类产品是没有变现逻辑的,但是如果这个东西能做的更大,或者能够做到某个状态,是能够出来一些东西的。
张鹏:其实我觉得在不同的阶段,大家需要面对不同的东西,并不是说有技术的纯净信仰,就一定要做 PLG(产品主导型增长)、就绝对不要投流。我也想到当年滴滴在很多的城市都没有 PMF,都在烧钱,结果有一天它突然把用户习惯和产业逻辑烧出来了,PMF 出现了。你觉得AI行业会走跟当年网约车一样的路吗?
闫俊杰:我觉得不是,因为其实网约车是非常典型拥有网络效应的业务,如果你有更多的司机、你就会有更多的用户,反过来也是一样。
大模型产品目前为止没有网络效应,有可能有微弱规模效应。不过还是需要拆成不同的产品类型,比如效率类、娱乐类,单独来看。
比如单纯在效率类产品上,用户体验的提升主要不是看用户是不是变多了,其实主要是看研发速率、模型迭代效率。相当于说,你的技术能力提高跟你的用户数量增长,其实不完全成正比。但在星野这种娱乐类产品上,如果你有越来越多的内容,规模效应还是挺明显的。
张鹏:我觉得今天的创业确实比移动互联网那一代更加不容易了。今天你去投流,所有的流量基本上在巨头手里,甚至你的 PMF 在它面前都是透明的,因为你不断地投就说明你找到 PMF 了,它随时可以跟。创业者一直在打明牌,巨头钱多、人多,也有流量,你做产品测试还要给它们「交税」,这就是这个世界非常真实的真相,你作为创业者怎么保持自己的希望?
闫俊杰:这确实是非常关键的问题,而且是一个很本质的问题。
我觉得偏信仰层面是这样的。如果你没有做很多的技术创新、产品创新,或者说没有在合理的时间内找到足够的非共识,这个事就不应该你干,就是该被大厂干。这不怪大厂垄断。
我们要思考的是你作为一家独立的公司,你真正能创新的东西在什么地方?是研发效率、认知、产品体验还是什么?你如果没有,创业就应该失败,也不能怪别人。
张鹏:很务实的想法,大厂的竞争反而能验证创业公司是不是真的有价值。
闫俊杰:是的。不过国内的流量被巨头垄断,但海外的流量其实相对比较开放,至少很多市场可以自由竞争。所以我觉得虽然很难,但是空间还是存在的。
谈产品:虚拟社交比智能助手受欢迎,但 super app 可能并不诞生其中
张鹏:说到产品,MiniMax 也是国内AI产品做得最早、最好的公司之一,能不能介绍一下你们「星野」、「海螺 AI」这两款主打产品?它们的发展情况怎么样?
闫俊杰:「星野」基本是一个主打 fantasy(想象)的产品。你看它的时长、用户分布、包括留存数据,其实它很像小说类的产品。
像「海螺 AI」这种,我们叫它智能助手,但其实它是没有定义的。原因是目前这类产品最大的都只有 400 万 DAU,不能算很大的产品,不太能定义这个行业。
我们的 fantasy 产品算是做的比较领先的,就用户量来说,它可能比助手类产品要高个 100 倍。我们的助手类产品才刚起步。
张鹏:fantasy 产品这么好,它的交流轮次、使用时长怎么样?
闫俊杰:我觉得挺夸张的,是很长的时长。
张鹏:为什么当年你会做「星野」这种 fantasy 的产品?当年的决策逻辑是什么?
闫俊杰:两年多前我们创业的时候,大模型还不是共识。我们当时认为把人工智能做成通用、服务大众这件事是很重要的,而且恰好看到非常明显的技术拐点,所以就开始创业了。当时,我们也不知道技术会变成什么样、产品会变成怎么样、商业化会变成怎么样。
「星野」的前身是「Glow」,我们当年做「Glow」的时候既没有 ChatGPT、也没有 Character.AI。当年我们不是做了很多分析、发现了机会,决定要来做它。我们的产品都是撞出来的。

MiniMax 旗下娱乐类产品「星野」|图片来源:MiniMax
张鹏:所以是先有了对 AGI 的信仰,做出了模型的能力,再顺着模型能力看能做啥就做啥,是这个逻辑吗?
闫俊杰:真实的情况是这样的。为什么这个产品最后变成了「Glow」了、没有变成 ChatGPT,是 2022 年 10 月份我们当时第一版的模型大概只有 30B(参数),它只能做娱乐的事,因为没有那么好。
张鹏:你得把 hallucination(幻觉)当作它的优势,而不是缺点。
闫俊杰:实际情况是,最开始的时候我们只有一个 pre training,对齐还根本没有跑通。所以这种东西是撞出来的,是非常随机的一件事,就变成这样了。
如果我们那时候更强一点,可能能做出来ChatGPT,但是很遗憾,那个时候能力就是没有那么强。
张鹏:创业归根到底还得看实际状况,当时你技术没准备好,做不出来很正常,这反而说明了为什么技术是AI产品最重要的部分。
闫俊杰:对,因为技术的发展就是有红利的。
张鹏:现在你们有了「海螺AI」,是不是还改过名字?我记得去年你们还叫「海螺问问」?
闫俊杰:的确是,我们改名是想让产品更加大众化。首先,我们觉得「海螺问问」有 4 个字,减掉两个字之后,「海螺 AI」的用户覆盖率会更高。其次,我们发现用户更深层次的需求不完全来自于问答,所以叫了这个名字。
张鹏:更深层次的需求不只是问答,所以那时候你们已经开始往未来的「智能助理」方向做思考了吗?
闫俊杰:是的。
张鹏:随着 GPT-4o、Astra 的发布,「智能助理」这个领域可能会有越来越多竞争者,你怎么看这类产品的发展目标?
闫俊杰:这类产品核心的东西应该就是一个,提升用户解决问题的效率、或者说回复的满意度。
我们客观来看,比如你问 ChatGPT 一个问题,它有多大概率给你一个满意的答案?我们自己的测试结果是,只有 60%。这也是为什么 AI 的用户渗透率只有 1% 的原因。可能只有对 AI 特别热忱的用户,在它给了你无数次错误答案的时候,你还能选择相信它、容忍它、甚至引导它来得到一些答案。
举个例子,我们用更大用户量级的产品,比如百度搜索、小红书搜索、甚至抖音搜索的时候,大概率能得到想看到的东西,满意度显然比 60% 高。只有这样,产品才能走向更广大的用户。
这也是作为从业者来说,我觉得 GPT-4o 没有让我觉得那么好的原因。因为它其实并没有提高这类产品真正重要的指标,也就是用户满意度。这个指标如果从 60% 提升到 90% 甚至更多,它就能变成可以信赖的产品。这也是我们在「海螺 AI」这个产品上要努力的方向。
张鹏:我相信最终你们的目标还是想创造 Super App,或者用AI native 的方式解决主流用户的大问题。你觉得今天不管像「星野」、还是像「海螺 AI」,它们会是 Super App 的侯选吗?还是说我们今天未必能看到 Super App 的最终形态,它会像你说的,随着未来技术的发展随机涌现出来?
闫俊杰:其实我们的基本假设是这样的:第一,现有的产品都不是。第二,我们认为现在的单个产品都能够长到足够大的用户规模,能给用户带来更大的价值,也能为我们带来商业上足够的成功和回报。这也是我们努力的目标。
至于说现在的产品到底是不是最终那个 Super App,我觉得其实是不重要的。为什么?因为 AGI 是一件长周期的事,显然不是 2024 年或者 2025 年就实现的,我们其实不需要给自己特别大的压力。
我们真正需要做的事是,让技术能够足够快地进步,同时基于当前技术能力做出的产品,能让公司的运转效率变得更高、能给用户创造一定的价值、能给公司创造商业回报。同时,我们还能有能力做更多的产品,一代一代往上滚,这就已经够了。
美国公司不一定是这样的路径。但作为一家中国公司,这至少是有先例可寻的一条路径。


