
近日,知名 AI 游戏创作者社区 LitGate 对腾讯音乐娱乐旗下的天琴实验室,正式发布了开源虚拟人视频模型 MuseV 进行了评测
近日,知名 AI 游戏创作者社区 LitGate 对腾讯音乐娱乐旗下的天琴实验室,正式发布了开源虚拟人视频模型 MuseV 进行了评测。文章将 MuseV 模型评为今年 AI 视频领域「王炸级」的产品,并从一致性、时长、自定义动作、口型驱动、通用场景视频生成、生成速度等多维度展示了 MuseV 的亮点和优势。LitGate 表示,测试中 MuseV 图生视频的稳定度表现超出了 LitGate 刚开始的预期。尤其是虚拟人微动长视频和口型生成部分有很大的优势,可以说是目前开源模型中最好用的一批。
以下是评测全文:
开源最强?腾讯音乐虚拟人视频模型 MuseV 首测
腾讯音乐娱乐的天琴实验室正式发布了开源模型 MuseV,现阶段支持图生视频和口型生成,可以丝滑生成虚拟人视频,目前可以在 Hugging Face 和 github 上直接拉取代码模型跑起来。

从 GitHub 描述来看,MuseV 是 2023 年 3 月份基于 Diffusion 世界模拟器的构想(听着有点熟悉?)启动的,去年年中模型达到里程碑效果,现在因为 Sora 的发布决定开源。
说个题外话,去年他们还悄悄发布了 AI 虚拟人陪伴产品「未伴」做落地尝试,LitGate 在抱着好奇心去试用后发现,和同类产品星野、筑梦岛等相比,它最大的优势其实是恋与深空的付费功能之一:免费上线了虚拟人实时语音对话和视频通话。
(并非抓取特定关键词回复,是电话形式的真·实时对话,沉浸感拉满)
这次开源的 MuseV 瞄准了视频生成这一领域,官方公布的成品在一致性和口型生成方面都有相当不错的表现,生成的虚拟人视频非常丝滑:

当然,具体表现还是要试试才知道,LitGate 立刻全速对 MuseV 进行了测评,看看它是否真的像宣传上说的那样靠谱优秀。
Part 1 一致性
由于发布时间比较突然,LitGate 先采用了 Gen2 和 Pika 这两款线上产品作为对比,后续会补上在工作流内与 SVD、AnimateDiff 等其他开源模型的测试。
根据官方的描述,MuseV 在微动的虚拟人视频制作方面有突出的优势,那就用一张图看看它生成视频的效果:

(从左到右依次为 MuseV、Gen-2、Pika)
可以看得出,在人物动作常规+背景不太复杂的情况下,MuseV 的画面一致性完胜,表情也很自然;Pika 画面一致性尚可,但画面细节丢失很多,清晰度感人,表情相对来说也没有那么自然;至于 Gen-2……为什么脸都变了呢(费解)
接下来是乐器弹奏的动作试验:


(从左到右依次为 MuseV、Gen-2、Pika)
MuseV 画面保持不错,细微动作没有硬伤(手部动作明显优于其他两个),Gen2 帮人整了容,Pika 模糊问题严重,还一直执着于蜜汁运镜……
不过 LitGate 也发现,MuseV 在画面主体有大动作的情况下表现稍差一些,但有些图片的背景也能实现比较自然的运动,而且和主体融合的效果也没有大问题,官方的示例视频中也有体现。
尝试了一下写实风格的图片和二次元平涂风格图片,视频效果也比较稳定:
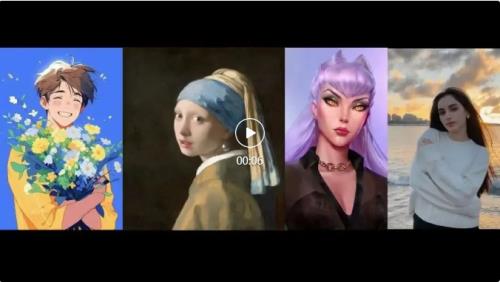
(真人图片效果比二次元自然很多,主要真人头发效果确实还蛮让人吃惊的)
Part 2 无限视频时长
这次的测评中,还有一个很重要的亮点。
在过去的 AI 生成视频模型中,大家生成的视频长度都普遍不长,稍微长一些的能够延长到 3-5 秒左右。
但是根据官方说明,天琴实验室设计了一种叫 Parallel Denoising 的新算法,所生成的微动虚拟人视频时长理论上可以达到无限长!
测试环境下,好像确实可以生成蛮长的视频……

(示例视频大约 10s,实际效果可以再延长)
这下想多大杯就多大杯,再也不用想方设法拼接短视频还要保持稳定性了。
Part 3 自定义动作生成
让图片跳舞这个事儿,通义千问之前已经小火了一把了,MuseV 也支持放入传统工作流通过 Openpose 来控制动作生成,LitGate 先来看一下官方效果:

在真实风格上 MuseV 的表现还是可圈可点的,动作比较流畅而且没有硬伤。由于 MuseV 是直接开源的,所以可以融入工作流内进行动作调试,比只能用现有模板的通义千问自由很多。
时间关系 LitGate 只选了个几个简单的动作进行测试,来看看生成结果:


目前来看,MuseV 是基于 pose 生成图片首帧的,效果不错。但对于任意输入图片的情况,还有待 posealign 模块进一步开源。
Part 4 口型驱动
口型生成一向是虚拟人视频的重点之一,开源页面有提到口型生成技术 MuseTalk 将于不久后开源,暂时先看下官方成品的效果吧:

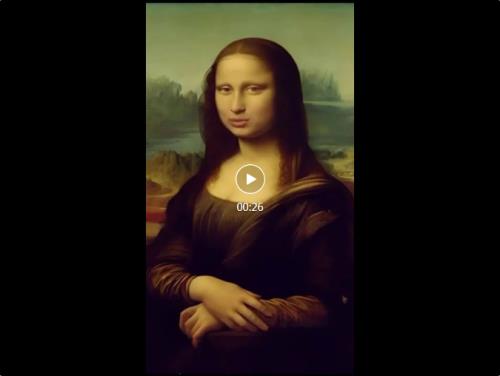
目前看起来效果还是相当自然准确的,对比 HeyGen 和 Pika 有一定优势,等开源了 LitGate 再来详细测评。(从 MuseV 开源的实诚风格来看,应该不会像隔壁某厂……)
Part 5 通用场景视频生成
需要注意的是,虽然 MuseV 的主要数据集来自于人像,但它在场景上的表现也不错(还记得刚刚视频中的背景也会动吗?)
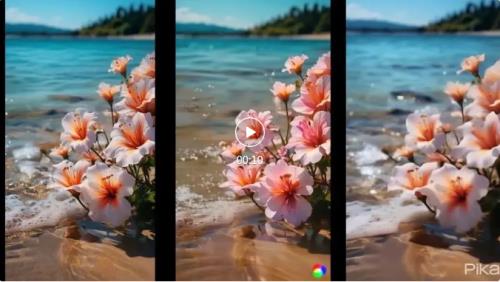

(从左到右依次为 MuseV、Gen-2、Pika)
MuseV 的一致性最高,海浪的运动细节也没有硬伤,唯一的问题就是前景的花基本没怎么动;Pika 出现了模糊问题,运动有点怪怪的并且依旧执着运镜;Gen2 运动非常自然,但是出现了熟悉的画风问题,可以说看视频知 Gen2,味儿很冲……
当然,如果用户有更加个性化的需求也可以通过拓展数据集来实现,反正都开源了,在工作流内进行拓展以及后续的数据集补充训练也不是问题。
Part 6 视频生成速度
顺便一提,在部署到本地环境测试后 LitGate 发现,MuseV 的视频生成速度对比其他模型是有速度优势的,生成 10s 视频的速度,对比其他模型生成 4s 左右的视频速度要快。
具体看了一下,步数仅需要 10 步,而别的视频生成大部分都需要 30 步,50 步,这一点有待天琴实验室放出论文后才能具体了解有没有针对性的优化。
另外 LitGate 留意到,天琴实验室的 HuggingFace 上有大量的大模型加速开源工作,后续也可以期待天琴实验室在 MuseV 上的加速。
评测结语
MuseV 这次的开源确实给 LitGate 带来了不小的震撼,测试中图生视频的稳定度表现超出了 LitGate 刚开始的预期。
尤其是虚拟人微动长视频和口型生成部分有很大的优势,可以说是目前开源模型中最好用的一批。
AI 图生视频的效果方面,常常会受到数据集等多种因素的影响,天琴实验室也表明开源只是一个开始,后续他们会朝着 Sora 的路线继续追赶,也希望更多团队能够参与到社区的开源共建中,给 AI 更多学习和进步的空间。
还记得在 23 年年底 LitGate 推出的 AI 产品总结中,视频板块的发展尚不尽如人意,但今年从 Sora 到 SVD,再到如今 MuseV 对虚拟人细分领域长视频的突破,一切都似乎处在前所未有的飞快发展中。
2024 年还未过三分之一已经全是王炸,期待今年的视频生成领域能给 LitGate 更多的惊喜。
AI 视频什么的,今年真的是卷起来了啊!
来源:互联网


