
近期,中文大语言模型蓬勃发展,但却一直没有出现可应用于评测大模型能力的测试。
近期,中文大语言模型蓬勃发展,但却一直没有出现可应用于评测大模型能力的测试。甲骨易 AI 研究院提出一种衡量中文大模型处理多任务准确度的测试,并在此基础上制作了一套适配测试中文大模型的数据集,并将其命名为「超越」。
数据集的测试内容涵盖四大领域:医疗、法律、心理学和教育。通过综合评估模型在多个学科上的知识广度和深度,能够帮助研究者更精准地找出模型的缺陷,并对模型的能力进行打分。
简介
自 ChatGPT 发布以来,大语言模型 (LLMs) 保持着在计算机科学技术与自然语言处理领域的热度,并且仍不断升温。ChatGLM、 MOSS、文心一言、通义千问、商量、星火等众多具备中文能力的大模型也接连发布。这些模型有着庞大的数据规模,通过广泛的预训练以达到能够正确理解人类话语和指令并生成类似人类语言的文本的能力。
目前,针对英文大语言模型已经有较为完善的评测方式,如 2021 年由 Dan Hendrycks 等人发布的 MMLU。然而,针对中文大语言模型能力的测试仍然缺失,推出高质量中文评测数据集已经迫在眉睫。
于是,甲骨易 AI 研究院制作了一个大规模的多任务测试数据集——「超越」(Massive Multitask Chinese Understanding)。「超越」的意义是希望中文大语言模型「超」出多数模型只能基于英文数据集测试的现状,通过发现大模型的缺陷,从而促进大模型理解中文语言的能力,使其「越」来越强大。
「超越」所包含的题目由来自不同知识分支的单项和多项选择题组成。数据集中的问题是由专业人员从公开免费资源中收集,覆盖学科面广,专业知识难度高,适合用来评估大模型的综合能力。
为了测试数据集的可行性和效果,甲骨易 AI 研究院在正式公开前已经使用其对目前开源的大模型进行了评测。「超越」数据集预计于 2023 年 5 月 20 日正式公开发布获取方式,具体发布相关信息详见文末。
接下来,将对「超越」数据集 (MMCU) 中所收录的题目进行介绍,并基于测试结果分析数据在语言模型训练过程中的重要性。
多任务测试
「超越」数据集 (MMCU) 的测试内容来自医疗、法律、心理学和教育四个大类的题目,包含单项选择和多项选择题,目的旨在使测试过程中模型更接近人类考试的方式。
数据集共收集了 11900 个问题,将其分成 few-shot 开发集和一个测试集。few-shot 开发集每个主题有 5 个问题,共有 55 个问题;测试集共有 11845 个问题。
下面分别对不同领域测试题目的学科和子任务示例进行展示。
医疗
医疗类题目来自大学医学专业考试,包括医学三基、药理学、护理学、病理学、临床医学、传染病学、外科学、解剖学等,共有 2819 个问题。
示例:
首次急性发作的腰椎间盘突出的治疗方法首选:
A. 绝对卧床休息,3 周后戴腰围下床活动
B. 卧床休息,可以站立坐起
C. 皮质类固醇硬膜外注射
D. 髓核化学溶解
法律
法律类题目来自国家统一法律职业资格考试,包括中国特色社会主义法治理论、宪法、中国法律史、国际法、刑法、民法、知识产权法、商法、经济法、劳动与社会保障法等,共有 3695 个问题。
示例:
根据法律规定,下列哪一种社会关系应由民法调整?
A. 甲请求税务机关退还其多缴的个人所得税
B. 乙手机丢失后发布寻物启事称:「拾得者送还手机,本人当面酬谢」
C. 丙对女友书面承诺:「如我在上海找到工作,则陪你去欧洲旅游」
D. 丁作为青年志愿者,定期去福利院做帮工
心理学
心理学类题目来自心理咨询师考试和研究生入学考试心理学专业基础综合考试,包括心理学概论、人格与社会心理学、发展心理学、心理咨询概论、心理评估、咨询方法等,共有 2000 个问题。
示例:
把与自己本无关系的事情认为有关,这种临床表现最可能出现于:
A. 被害妄想
B. 钟情妄想
C. 关系妄想
D. 夸大妄想
教育
教育学题目来自中国普通高等学校招生全国统一考试(中国高考),包括语文、数学、物理、化学、政治、历史、地理、生物,共有 3331 个问题。
示例:
若圆锥的侧面积等于其底面积的 3 倍,则该圆锥侧面展开图所对应扇形圆心角的度数为()。
A. 60°
B. 90°
C. 120°
D. 180°
评测过程
依靠以上获取到的优质数据,可以开始对大模型的能力评测。下面将介绍本次评测的一些模型和评测方式。
评测模型:
Bloom 系列:bloomz_560m、bloomz_1b1、bloomz_3b、bloomz_7b1_mt
清华大学知识工程和数据挖掘小组:ChatGLM 6B
复旦大学:MOSS 16B
OpenAI:GPT-3.5-turbo
评测方式:zero-shot 和 few-shot
zero-shot 模式:题目直接输入到模型以获取答案并计算准确率。
few-shot 模式:先给模型提供 5 个问题和答案的例子,再附上问题让模型给出答案。
评测结果
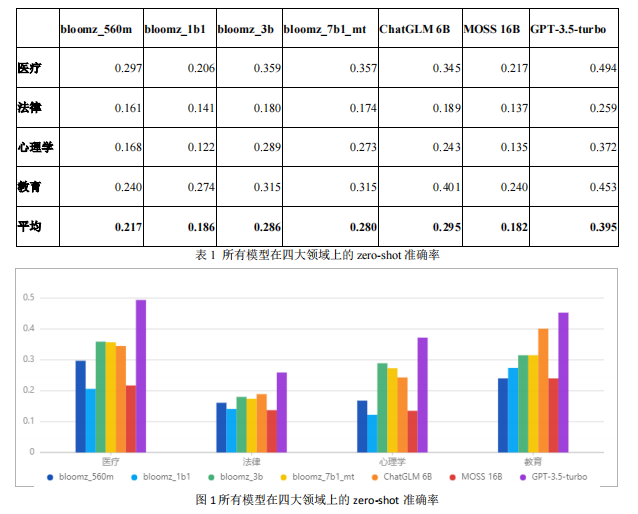
通过比较各个模型的 zero-shot 准确率(如图 1 和表 1),GPT-3.5-turbo 在四个领域的正确率都遥遥领先;MOSS 16B 模型虽然有 160 亿参数,但准确率却只接近随机准确率 (大约 25%);bloomz_560m 模型的参数量最小,表现却超越了参数量更大的模型。评测结果体现了大模型的参数量不是评价大模型的唯一标准,在训练过程中数据的质量也应得到重视。

测试结果还表明,所有模型在 few-shot 模式下都有不同程度的性能下降。例如,与 zero-shot 准确率相比,GPT-3.5-turbo 在语文、化学、政治子任务上的 few-shot 准确率都有下降 (见表 2 和表 3)。

表 2 所有模型在教育子任务上的 few-shot 准确率

表 3 所有模型在教育子任务上的 zero-shot 准确率
结论
大模型训练通常采用海量互联网公开数据,因此数据高效筛选以及垂直领域高质量数据的标注也非常重要。通过测试发现,在四大领域中,所有模型的平均 zero-shot 的准确率均未超过 0.5,这就证明了目前所有模型的中文训练数据还存在明显不足。
测试的结果表明,更大的模型参数量不一定带来更好的性能,而训练方式和所用数据质量也是至关重要的,需要得到更多的重视。研究者们应该考虑如何设计更好的建模方式以便更好地学习文本数据中蕴含的知识,并且思考如何准备或者标注优质的数据集,去使中文大模型获得更准确的理解能力和文本生成能力。
写在最后
综上,就目前而言,用于评测大模型的高质量中文数据集仍是稀缺资源,但行业内却亟需一种公开、科学的方式来测试大模型的能力。甲骨易 AI 研究院率先提出要制作出一套高质量的中文数据集,并迅速搜集整合数据资源完成了「超越」数据集,成为国内首家制作中文专门领域多任务数据集的研究单位。
甲骨易 AI 研究院致力于推动计算机信息科技与自然语言处理领域的发展,希望扩大中文语言在大模型中的应用,促进中文大语言模型的理解力与生成力。「超越」数据集 (MMCU) 正是为了帮助每一位正在 LLMs 和 NLP 方向研究的学者、专家以及工程师,携手促进中文大语言模型向着更准确、更智能、更优质的方向发展。后续,甲骨易 AI 研究院也依旧会根据反馈持续优化「超越」数据集。
甲骨易 AI 研究院预计于 2023 年 5 月 20 日 14 点甲骨易第三空间举办「超越」数据集发布会。
来源:互联网


