
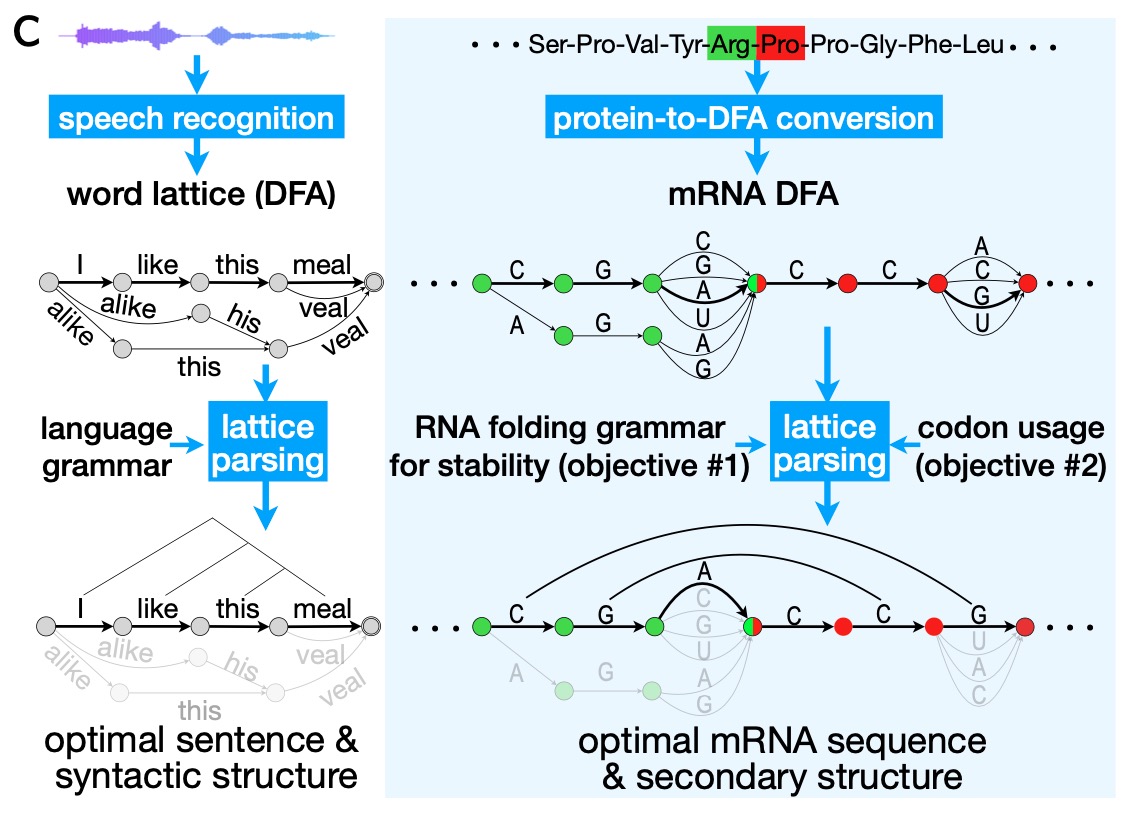
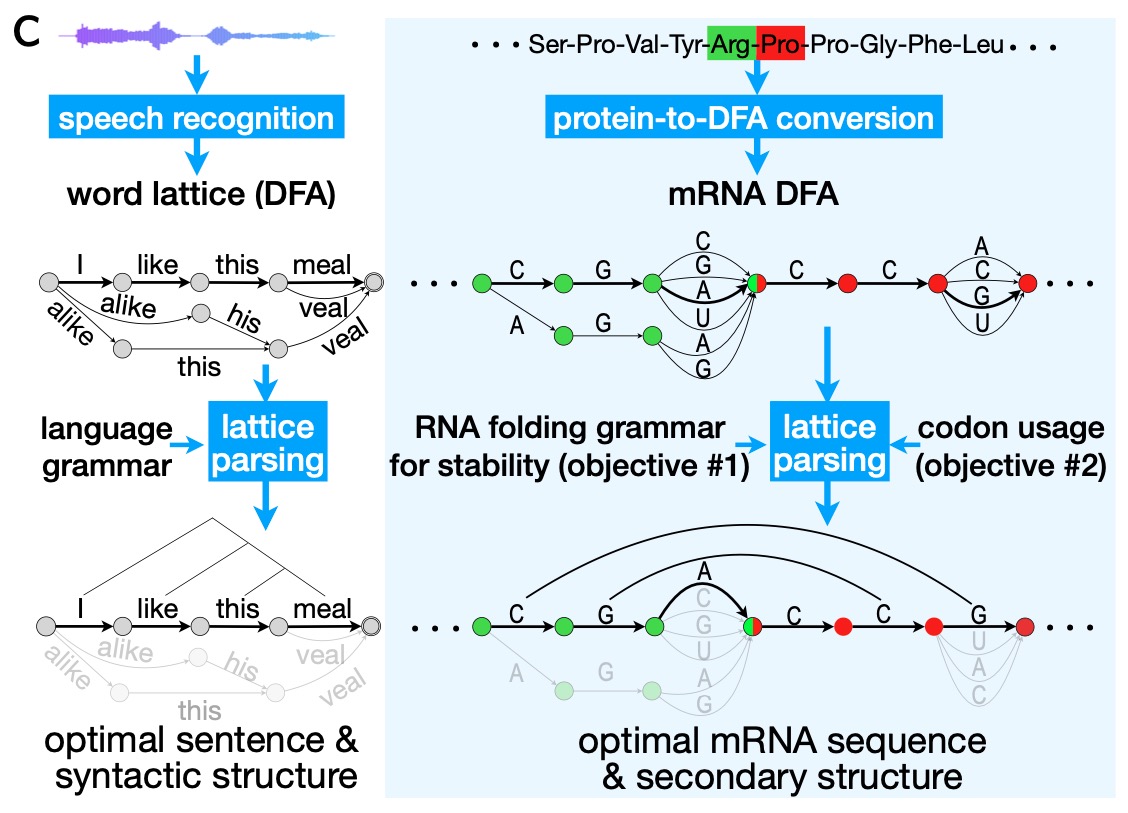
「找到最佳的 mRNA 序列,就类似于在自然语言处理中识别发音相似的备选句中最有可能的一句。」
ChatGPT 成功地让所有人意识到生成式 AI(AIGC,AI generated content)的强大,过去几个月里,生成图片、文案、程序等的应用层出不穷。
但相比这些人人可以感知的的产品形态,AI 在垂直产业领域正在引发更大的革新性影响。
以生命科学为例,AI 正被用于研究蛋白质、DNA、RNA 等微小的生物活性物质,这个垂直领域叫生物计算。随着海量生物实验数据的积累、计算机性能的快速提升、以及机器学习和深度学习等 AI 技术的广泛普及,AI+生物计算被寄予厚望。
其中,与你我有关的一个例子在于疫苗。
新冠疫情期间,mRNA 疫苗的成功研发,让 mRNA 疗法从前沿小众的研究领域走到了大众的实际应用中。而 AI 加持的生物计算则有助于 mRNA 疗法效力的提升,推向更加广泛的应用场景。
日前,百度作为第一发表单位被《自然》刊发的研究成果——LinearDesign 项目。在该项目中,百度与合作单位斯微生物、俄勒冈州立大学、罗彻斯特大学一起,形成了 AI 生物计算+生物实验闭环,验证了算法设计序列在 mRNA 疫苗关键指标上的显著提升。
这一切是怎么发生的?
更快制备的 mRNA 疫苗
在新冠疫情期间,人们广泛接种的疫苗有三种:传统灭活疫苗、腺病毒载体疫苗和 mRNA 疫苗。
相比最熟悉的传统灭活细胞,mRNA 疫苗在这场全世界大流行的病毒中被证明是高效的,mRNA 疗法也因此而进入了更多普罗大众的视野——mRNA 作为疫苗或药物,可应用于传染病预防、治疗肿瘤和蛋白替代疗法。
就新冠预防而言,mRNA 疫苗被注入人体后,人体细胞可以根据 mRNA 这张「图纸」记录的遗传信息,合成出与新冠病毒的棘突蛋白高度相似的蛋白质——即在体内表达出这种特异性抗原。再由这种抗原诱导细胞免疫和体液免疫,刺激产生相应抗体和免疫细胞,用以预防新冠病毒。
之所以研制这种疫苗,是因为制作「图纸」(mRNA)比制造「成品」(灭活病原体)更快、更简单、也更易于修改。当面对新冠这样随时会突变的病毒,具有这些特性的 mRNA 疫苗可以被快速制备,帮助免疫系统更快地防御变种病毒。此前,生产 mRNA 新冠疫苗的辉瑞制药表示,如果新冠病毒突变,他们可以在 6 周之内就生产出相对应的新疫苗,而传统灭活疫苗至少需要以年为单位来制备。
但更快的 mRNA 药物目前还没有办法大面积推广,因为 mRNA 分子易降解、不稳定,在人体内无法长时间表达。因此,对于特定的药物,比如需要长期表达的抗癌药物,目前还没有成功上市的 mRNA 药物。
在这个大背景下,设计出更稳定、成药性更好的 mRNA 序列,也就成为 mRNA 疗法亟待攻关的一大难题。
具体来说,由于同义密码子的存在,mRNA 序列设计空间极其巨大。以新冠 mRNA 疫苗(抗原为棘突蛋白)为例,需要在 10 的 632 次方个海量序列中找出最优序列,如果一个个枚举,则需要 10 的 617 亿年,是一个不可能完成的任务。即便由一台超级计算机每秒计算一个序列,那么从宇宙诞生到现在的 138 亿年,连潜在 mRNA 序列的亿万分之一都无法计算完毕。
5 月 2 日,国际顶级学术期刊《Nature》加速发表了一篇论文——《Algorithm for Optimized mRNA Design Improves Stability and Immunogenicity》,对这一难题发起了挑战。论文显示,百度提出的 LinearDesign 算法,已经可以使计算机在 11 分钟内找到最稳定的 mRNA 候选序列,并高效的设计出既稳定,又蛋白翻译水平高的 mRNA 序列。

为了进一步验证算法设计序列的有效性,百度与论文合作单位斯微生物开展了生物实验。实验数据显示,算法有效性在新冠 mRNA 疫苗和带状疱疹 mRNA 疫苗两种疫苗中得到验证。与传统方法设计的序列相比,LinearDesign 设计的序列在 mRNA 稳定性(半衰期)、蛋白质表达,使抗体反应水平上均有显著提升,其中在新冠 mRNA 疫苗上抗体反应水平最多增强了 128 倍。
不仅有助于疫苗的研发,该项研究成果还可应用于包括单克隆抗体和抗癌药物在内的药物研发,具有重要的实际意义和广泛的应用前景。
建模关键技术——动态规划算法(Dynamic Programming)和网格解析(Lattice Parsing)
LinearDesign 算法之所以如此高效,首先源自主创团队采用了计算机科学领域里一个非常经典的算法——动态规划算法。通过对随序列长度指数级增长的计算状态做等效合并,该算法可以无损地对海量的搜索空间进行压缩,最后把一个指数级复杂度的问题变成了一个在多项式时间内就能够解决的问题。
更重要的是,主创团队把语言学和生物学这两个看似风马牛不相及的领域联系在了一起,将 mRNA 序列设计问题转换为自然语言中的语音识别问题,并借助经典的「网格解析」算法来求解。具体来说,找到最佳的 mRNA 序列,就类似于在自然语言处理中识别发音相似的备选句中最有可能的一句。
论文共同一作、百度研究院资深工程师张贺表示,这也是团队在论文中阐述的此项研究的一个亮点。有了这个成功的案例,此后可能会有更多研究沿着自然语言处理和生物计算的联系,做出新的研究成果。
「因为我们能够抓住它最底层的、根本的相似性,把两个问题结合在一起」,他进一步解释了这一开创性的想法。
本质上,这两者在底层的数学逻辑是一致的。mRNA 序列,它本身是由 A、U、C 和 G 四个碱基组成的序列,就像自然语言是由一个个词语组成的序列一样。
找到最优的 mRNA 序列,就像从很多个发音相似的这个句子里面去找到最有可能正确的语句一样,都是通过「网格解析」来做。具体来说,「对于 mRNA 序列设计问题本身,给定一个蛋白质序列,可以把这个蛋白质序列想象成一个语音。这个蛋白质序列对应有成千上万个海量的 mRNA 候选序列,所有这些候选序列都可以翻译成同样的一个蛋白质序列,就像我们有很多个句子的文本,对应着同一段语音。我们想从海量的 mRNA 候选序列里面去找到最好的一条,就像从众多句子中找到最符合语音的这个句子。」
明确的优化目标——二级结构稳定性和密码子 提升稳定性和有效性
有了高效的算法框架,还需要对齐正确的优化目标。此前,美国国家科学院院刊发表的一篇论文揭示,同时优化 mRNA 二级结构稳定性与密码子适应指数,能够提升蛋白质表达。因此,LinearDesign 在设计时主要考虑了这两个特征因素作为优化目标。张贺也指出,「人体是一个非常复杂的机器,实际影响 mRNA 效力的因素很多,目前看结构稳定性和密码子适应指数是其中重要的两个因素。」
生物计算的广阔前景
事实上,LinearDesign 是百度在生物计算领域广泛布局的一个方面。
百度研究院从 2018 年就已经开展了 RNA 相关的研究。除了 RNA 领域,据介绍,百度还在生物计算领域进行了很多探索,包括小分子、蛋白质、多肽、生物计算大模型等等覆盖了新药研发多个方面。截至目前,百度已打造完整的基于飞桨的生物计算平台-螺旋桨 PaddleHelix,涵盖文心大模型-生物计算大模型,探索 AI 技术在小分子、蛋白/多肽、RNA 等场景的应用。其中生物计算等大模型属于百度文心大模型家族中的一员。

文心大模型体系里,生物计算领域的模型未来也会逐渐开放给行业。目前,百度文心大模型形成了系统性的大模型技术体系,包括自然语言处理、视觉、跨模态、生物计算等,最近火爆的文心一言就是百度自主研发的知识增强大语言模型。文心一言通过百度智能云对外提供服务,为企业构建自己的模型和应用,未来医疗、工业、金融等重点领域效率将会大幅提升,快速形成新产业空间。


