
当今的自动驾驶行业是一个百舸争流的局面,总体来看,还是西方引导东方的探索摸索,以google为主的以激光雷达为主的流派和以Tesla为主的机器视觉流派引导了整个市场......
本文作者为雪湖科技创始合伙人杨付收,专注在芯片算法相关领域十多年,曾就职于中兴,华为,展讯等知名芯片公司。文章主要讨论了自动驾驶最主要的感知部分:机器视觉,以摄像头为主的计算机视觉解决方案,为汽车加上「眼睛」,从而有效识别周边环境及物体属性。
一. 万马嘶鸣风云际, 感知为王路先行
当今的自动驾驶行业是一个百舸争流的局面,总体来看,还是西方引导东方的探索摸索,以google为主的以激光雷达为主的流派和以Tesla为主的机器视觉流派引导了整个市场.从发展趋势来看,两种方法正在进一步融合,最终会各取优势而相互补充发展。对整个自动驾驶领域,其核心技术是个拟人化的实现过程,即: 感知->认知->决策->控制->执行五部分.感知,是所有智能体所要拥有的基本属性,自动驾驶要解决的第一个问题,就是汽车的感知系统,AI算法的核心就是要解决感知问题.汽车的感知系统是多种传感器融合的系统。

(图1 自动驾驶技术框架图 来源:亿欧智库 )
如上图所示,多传感器融合共同组成自动驾驶的感知层已经成为行业共识,这是一个复杂的技术体系,本文主要讨论最主要的感知部分:机器视觉,以摄像头为主的计算机视觉解决方案,为汽车加上“眼睛”,能有效识别周边环境及物体属性。随着AI算法的蓬勃发展,机器视觉由基于规则向基于CNN神经网络转变.

( 图2 汽车传感器示意图 来源:亿欧智库)
国内的主要发展方向集中在视觉上的突破,一种原因是激光雷达和毫米波雷达被国外几个大公司控制,核心技术短期内难以突破,成本居高不下。而做机器视觉,则成本低廉,且容易上手,国内摄像头的供应链很完善,所以在这种情况下,国内厂商更倾向于CNN网络的机器视觉能做更多的事情,其实这种选择是正确的,国内厂商突破的最好的一个点就是视觉突破,视觉方案相对成熟和完善,可以利用国内的一些特点,找到差异化竞争的突破口,快速形成优势,再逐步迭代更新技术。如开车时任意变道的行为,这个国外的汽车检测方式是等尾部进入车道内再进行检测,这明显不符合国情,所以算法本土化,解决国人开车遇到的问题,就是差异化竞争,这也更需要对算法有自己的把控能力.
车载系统对CNN网络的目标检测识别的要求是很高的,而且越高越好,这不仅仅是为了检测车道和障碍物,还会在自动驾驶中的另一个必不可少的条件:高精度地图上有巨大的利用空间。因为传统的地图模式无法满足自动驾驶的需求,它需要更多的维度信息,更新更及时,精度达到厘米级。精度要想达到厘米级,仅仅依靠卫星是远远不够的,目前两个解决方案,一个是RTK方案,即在地面上建立大量的基准站,由基准站来弥补GNSS定位的不足,这个方案精准,但却很贵。另外一个方案就是先将地图上的多维度信息保存到数据库,然后通过车载上的多传感器(摄像头,雷达)所获取到的特征信息和数据库进行匹配,从而修正和弥补定位的精度问题,毫无疑问,这个方案更加实用和快速部署。国内地图公司更倾向于用这种方式,这就更加要求摄像头检测物体特征精准度的问题了。
由算法的精度问题,不得不提算法的实现芯片方案,现在的精度最好的算法还是基于CNN的AI算法模型,CNN算法要求的计算量是很大的,目前很多厂商都是直接用nvidia的TX2做为运算主要载体,在TX2上运行对GPU友好的算法,
这里其实有个误区,当算法对GPU不友好时,就直接宣判了该算法的死刑,这样操作是不合理的,GPU成了前进路上的一个拐杖,拐杖用的多了就产生了依赖性,反而丧失了发现更多空间的创造性,我们用两条腿走路,还是要回归到问题的本质,根据问题的具体需求来寻求最优的解决方案。自动驾驶车载系统的基本要求 低延时 低功耗 以及算法的复杂性和多变性,决定了用FPGA做车载加速方案是一个理想的选择。用FPGA做加速方案的另外一个不可忽视的好处是:成本可以做的很低。
所以机器视觉的好的方案已经不单单是好的算法,而是一个在合理的硬件成本里得到一个最优算法的求解问题。由算法来保证识别精度,由硬件来保证算法的实现速度,由成本来保证两者都需要性价比最优的搭配,这才是正确的解决思路。当然,想同时实现上述几点,并非易事。路,要一步一步的走,坑,要一个一个的趟,我们上述的问题一个一个的分析。
二. 算法同源不同行,孰高孰低检测忙
在整个AI算法的大环境下,车载视觉系统的算法也是基于CNN的分割算法,这就引出目前主要的两个算法Faster RCNN系列和yolo系列,两者各有千秋,前者精度更准,后者速度更快。前者是two-stage的方案,即先用最好的网络来找出特征值,然后再调整框来检测目标。后者是one-stage的方案,即找特征值和画框在一个网络里完成。
通俗的理解,Faster RCNN更符合人类“强强联合”的概念,即:找出目前性能最好的网络,然后再组装成一起,产生更优的效果,它是基于多网络融合的方案,所以它的特点就很明确:算的准,但是算的慢。yolo的诞生,恰恰是解决了这个问题,yolo的最大的特点就是快到没朋友,但在精度方面却逊色于Faster RCNN。
数据对比:

(图3 Faster R-CNN是精度最高的 来源:网络)
COCO数据集上,前 10 名中有 9 项都是来自于Faster R-CNN 的变体。
这两种方法都有很多变体,one-stage 的方法在精度上不断想与 two-stage 的方法抗衡,two-stage不断的在加快计算速度,但在数据集上的结论以及越来越快的 Faster R-CNN 变体的可以说明,Faster R-CNN 的 检测精度始终保持领先。但在速度上,yolo是遥遥领先的。

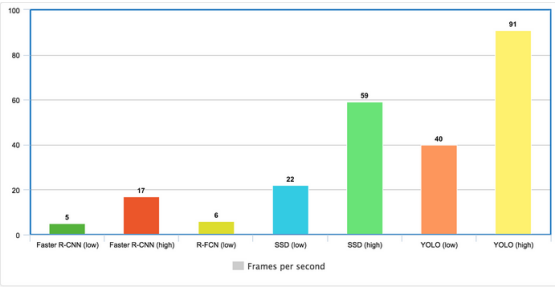
(图4 yolo的速度是最快的 来源:网络)
正是Yolo在速度上明显提高,YOLO的确受到车载系统的青睐,Yolo真的是车载系统的首选吗?答案未必,正如上文所述,Faster RCNN的精度是最好的,如果能将其速度也提上去,岂不是更好的选择。
为此,我们先分析下Faster RCNN精度高的原因:
首先,前景背景分离的区别。Faster RCNN是有前景背景分离的。这会要求在训练该网络时需要进行正负样本都要训练,也就是说正确的范畴我要负责,错误的范畴我也要负责。这会大大减少误检率的概率,所以Faster RCNN的查全率(recall)会特别的高。
而yolo则没有这样的算法结构,它只有正样本训练,不会区分前景和背景的区别。 其实这一点是对自动驾驶不太友好的,例如 之前Tesla的自动驾驶事故就是因为检测算法没有区分前景和背景,将迎面开来的白色卡车和背景中的白云混为一体,从而导致事故发生。
其次,画框方式的区别。Faster RCNN和画框的方式和yolo是不一样的,yolo是将框的问题作为一个聚类问题解决,由算法去自适应物体形状。而Faster RCNN是按照一定规则的框去逼近物体形状。如下图所示,9个矩形共有3种形状,长宽比为大约为(1:2,1:1,2:1)三种,通过anchors就引入了检测中常用到的多尺度方法。

(图5 框的类型 来源:网络)
这种人为定义的框的结构更能精准的标定物体,当然,任何优势都是有代价的。Faster RCNN为每一个点都配备这9种anchors作为初始的检测框,所以在原始图上,anchors的个数特别多,然后让cnn来判断哪些是有目标的前景,哪些是没有目标的背景,然后再对目标anchors进行排序和NMS(非最大值抑制),即能得到最好的效果。能量是守恒的,当获得优势A时,并将付出B的代价,关键看代价是什么。feature map每个点设置9个Anchor,所以他的anchor是很多的,如下图所示(网络截图):

(图6 anchor的框图 来源:网络)
当然,好处也是很明显的,举个例子,如下图:

(图7 框的平移转换示意图 来源:网络)
每个Anchor的平移量和变换尺度 ,显然即可用来修正Anchor位置了。红色为提取的foreground anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机,每个Anchor的平移量和变换尺度,即可用来修正Anchor位置了,表现结果即是由只标出主体的红框转换为标记更准的绿框,显然,绿框的精度更准。
相对来说,Yolo系列不区分前景和背景,画框的方式也是做一个回归的问题,这会对密集的目标的画框方式导致不准,yolo会把密集的目标会画成一个框。

( 图8 yolo密集目标检测 来源:雪湖实测 )
除了精度高之外,能做多网融合是Faster RCNN的另外一个很重要的特点。
特别对于车载系统,由于现实的复制性和应用的广泛性,经常会需要添加不同的网络和良好的性能,如增加车道检测等,可以将不同的网络通过interp(双线性插值)层来进行实现不同网络之间的平滑过渡。
利用这个特点,我们可以做很多启发性的探索,前面提到,多传感器融合来构建自动驾驶的感知层是行业共识,如激光雷达在自动驾驶中是个很核心的传感器,有没有将激光雷达和视觉同时融合到一个网络中的方案呢?有人提出这样的方案,如下:

(图9 用FasterRCNN来融合激光雷达和视觉算法 来源:网络)
上图的方案,总体上沿用了Faster RCNN的检测框架,但是在输入、proposal的形式以及Faster RCNN网络上做了较大的改动,以实现视觉与激光点云的信息融合。
这个网络给了我们很大的启示,多传感器融合方案框架是自动驾驶的必备技能,我们必然要考虑不同的传感器的特性和适应该传感器的算法结构,然后将多种算法结构融合到一个算法框架中来,而Faster RCNN网络本身就是基于多网络融合的方案制成的,所以用Faster RCNN来做车载系统有其兼容多传感器方案的巨大优势。
既然Faster RCNN这么多的好处,为什么用的人少呢?主要原因就是算的慢,如下图所示

(图10 FasterRCNN 在TX2上的运行结果 来源:雪湖实测)
由上面图表可以看出,Faster RCNN在TX2的运行结果是非常慢的。算法慢,便无解了吗?未必。因为这里所谓的慢,是针对GPU而言的,是因为算法对GPU不友好导致的结果,而对GPU不友好,未必对其他异构计算平台不友好,事实证明,这恰恰是FPGA的优势所在。
三. 安能得来偷天技?兼顾精度与速度。
在GPU运行慢的网络,可以在FPGA上进行加速实现。而要想提高速度,就要对网络进行具体分析,是哪些层运算速度慢以及慢的原因在哪里?

(图11 Faster RCNN的框架图 来源:网络)
如上图所示,前半部分是基础网络来提取特征值,后半部分在画框,RPN网络负责前景背景分离,排序算法负责筛选,最后全连接输出结果。
总体运行结果,进一步分析每层的耗时:

(图12 Faster RCNN在gpu中每层的耗时 来源:雪湖实测)
关键层interp层的分析:

(图13 Interp层分析 来源:雪湖实测)
通过图12 的分析结果我们得出结论,耗时最长的都集中在了proposal(排序)及以后的层(FC层)。通过图13 Interp层(双线性插值)的分析,我们也得出结论,GPU对Interp层的加速有限,速度没有CPU的运算快。通过这些数据的分析,我们就能很明白的知道GPU的优势和劣势在哪里,GPU的优势在于能重复数据切片,在运算cnn图片时它是有优势的,因为图片可以分成不同的tile片,然后GPU会对每个tile进行并行计算,当算法并不能很好的完成切片动作时,GPU便没有什么实质的优势,从上图可以看出,proposal和FC6都很耗时,proposal层就是在排序,排序对GPU是不友好的。Interp层也是不好切片操作的,所以proposal模块及以后耗时比较大。
知道了相应的数据和原理,在FPGA上就能很好解决这些问题,对FPGA来说,FPGA是可编程的,是可以将整个算法一分为二的,在proposal之前是一部分,在proposal之后是一部分,两者在全流水运算后是一个并行的状态。这样用并行的计算来抵消后面的耗时时间,就能大大的缩小计算时延。
针对Interp层,FPGA可以将相应放大的系数存入BRAM中,这样的时间更短,是CPU的3倍左右的速度。Interp层的意义是很大的,因为前面我们分析过,自动驾驶的感知层很适合做多网络融合的方案,而Interp层正式这些网络结合的连接层,经过大量实验证明,用Interp做分辨率的上下采样切换,能最大的保留原始图片的特征信息,从而使多个网络间能够平滑过渡。这也就意味着多网络融合的方案更适合用FPGA来实现。
除了前面的优化方法之外,我们还可以考虑层合并,切割featuremap,权重共享,减少IO读写时间等方式来进行进一步的优化。另外一个不得不提到优化方向就是量化成8bit数据进行计算,这样FPGA中的DSP每次都能运算两个数,这就可以使用性价比更高的FPGA芯片上进行运算,从而得到更高的收益。雪湖科技就是这样做的。

(图14 雪湖科技开发的Faster RCNN的性能参数)
当然,并非说yolo算法没有优势,雪湖也对yolo系列做了FPGA加速的方案。

(图15 雪湖开发的yolov3-tiny的性能参数)
雪湖做的工作只是说明用什么样的算法应该根据真实情况而定,而不单单是看GPU的运算指标,FPGA有很多很惊艳的东西,它的潜力一直摆在那里,只是尚未被挖掘出来,雪湖在FPGA领域深耕多年,能把FPGA的潜力充分挖掘,只要能做到这一点,出来的结果就足够惊艳。
四. 风景莫道塞外好,江南深处藏雪湖
开发FPGA是有难度的,要对FPGA的逻辑实现和算法优化有很深的理解之外,
没有一支精干的团队,没有一个好的验证平台,没有强有力的EDA开发工具,
将这么复杂的算法要在一个资源有限的FPGA芯片上实现并达到很高的吞吐量,难度是可想而知的。
雪湖科技在这方面下足了功夫,十年磨一剑,打造出一套完全自主产权的完整的先进的工具系统,同时,针对CNN的AI算法这块,专门打磨出一套完整的开发/验证系统。

(图16 雪湖CNN算法实现框架图 来源:雪湖科技)
如上图所示,我们将所有的计算模块都进行封装,并通过不同的command来执行不同的算子操作,最终会加快CNN算法的实现和落地。
可以参考之前写过的相关文章链接:
https://mp.weixin.qq.com/s/QmIuRLtk0thLhD6i7zumWw
将AI算法快速落地,是雪湖的优势所在。雪湖,以算力为根本,为加速而存在,不止步于自动驾驶,不畏惧于技术变迁.以拥有完全自主产权的核心技术为荣,以创新和拼搏为荣.在FPGA芯片加速计算领域(包括但不限于AI算法)绝对是一道亮丽的风景线,正所谓:风景莫道塞外好,江南深处藏雪湖 !
作者简介:杨付收,雪湖科技创始合伙人,一个在硬件圈里努力写诗的软件程序猿。专注在芯片算法相关领域十多年,曾就职于中兴,华为,展讯等知名芯片公司。白天代码几千行,晚上咖啡伴梦香。每天也就一件事,处理bug一箩筐。


