

模型的可解释性,是AI下一个突破点
近日,上海交通大学上海高级金融学院联合世界知名高校及科研院所举办 2019 国际金融科技会议,氪信科技创始人兼 CEO 朱明杰博士代表年轻的 AI 创业公司,向与会者阐述了氪信深耕金融领域头部机构的「秘密武器」,这不仅是氪信首度公开的一份较全面的技术干货总结,也是在大规模工业实践基础上对 AI 金融痛点和难点的系统性梳理,因此对于 AI 时代如何抢占金融科技制高点,具有前瞻意义。
谢谢李教授,谢谢各位,很高兴又来到高金。我们公司成立第一年就在这附近的番禺路上,技术合伙人全是交大的,所以我们经常过来吃午饭,吃了饭以后溜弯转转。
今天讲这个题目非常得理直气壮。两方面的底气,首先我做了十几年的 AI,以前在互联网行业里用 AI 和算法解决问题,觉得理所当然。当时金融行业的朋友讲大数据给他们带来的挑战,我想算法或许可以用得上,于是开始进到这个领域实践。
从 15 年底做这件事,一不小心做了差不多 4 年;另一个底气,是氪信刚成立就和民生银行合作,解决小微企业信贷难的问题。在座的应该比较清楚,给小微企业放贷的风控压力很大,当时民生银行启动了以大数据为特色的小微 3.0 项目,我们合作尝试用大数据解决风险攀升的问题,效果很好,去年 6 月末,民生银行的小微企业贷款余额已经达到了 6500 余亿元。
16 年开始,我们和招商银行合作,那时候招商银行希望通过智能方式拓展线上零售业务,我们开始陪伴招商银行智能升级,从风控、反欺诈延伸到营销、催收等,合作主体也从信用卡中心扩展到了零售信贷;去年开始,我们又和四大行合作,解决数亿账户业务体量带来的智能化挑战和对公业务问题。所以我们从成立走到现在,经过了发展理念最先进、要求也最高的银行考验。
同时我们在国际的顶级学术会议上也发表了一些论文。一个创业公司还有空发论文,感觉有点不务正业,其实是因为我们有挺多的实践和数据处理经验,就顺便发了一些论文。昨天跟几位教授和同行吃饭,有人说我们公司的论文已经成为一些公司的面试题,这让我压力很大。
AI应对另类大数据业务挑战
今天大家讲金融大数据,主要都在说强金融数据之外的「另类数据」。我们这些做计算机工作的,能感受到风控专家最痛苦的地方,是他们希望按照以前定规则的方式,把这些数据编码到以往的评分体系里。比如根据工资多少、纳税多少做评分卡,对那些金融概念之外的数据,比如一个人一天和多少人打电话,他的互联网行为、社交网络状况等,风控专家一开始也是想根据传统经验把它们变成特征变量,结果发现远远超出了评分卡可处理的范围。
我们刚好很擅长做这件事,因为以前我们在互联网处理的就是这些数据,我们训练机器在一堆照片里识别谁是章子怡,不是告诉它谁长得美长得白就是章子怡,不是这样的。但是我们依然能做出识别率非常高的模型,这里面没有什么神奇的单项技术,它是一系列技术。今天,我们用 AI 技术处理金融领域的另类数据,也不是围绕一个非常 fancy 的技术,不是首先要迁就人的理解范畴,我们是为了达到实际效果的提升才出发的。所以,我们发表的学术论文有着非常好的实际效果支撑,我也有底气站在这里跟大家讲一讲论文。

三种「另类数据」的处理方式
首先给大家展现的是一篇综述性质的文章,里面总结了一系列氪信用另类数据构建强风控体系的工作。
一般来说,难以做成评分卡的另类数据主要包括动态类、文本类、网络类三种类型,这些让风控专家束手无策的数据,通过构建有效的模型都能够让机器去处理。总的思路是在金融场景下,将专家的经验变成机器能够理解的语言和数据,不断训练机器,提高机器的学习能力,最后让机器处理人力无法解决的问题。
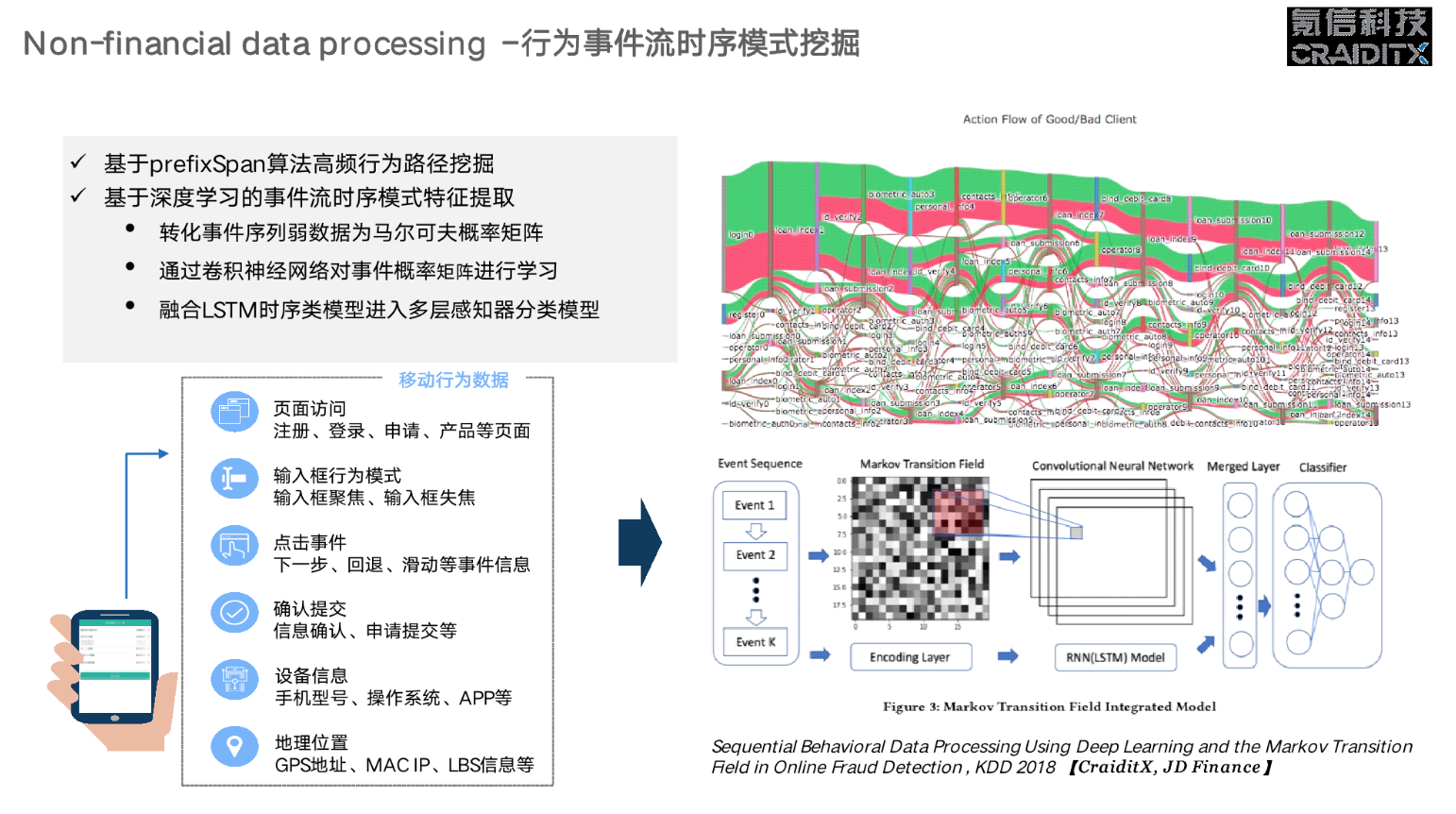
动态时序数据是基于时间的一系列数据,如果风控人员要用评分卡把这类数据归类成一个个特征变量会极其痛苦,但是机器不同,它可以存储和处理大量的时序数据,是一种关注总体而非个别节点的方式。这是我们跟京东金融的一个合作成果,相关论文发表在 2018 年的 KDD 上,主要是处理发生在 APP 上面的序列化行为,比如个人注册了一个页面,输入了一些信息,点击的速度快慢,从左边滑还是右边滑……这样一些数据,然后从中找出有欺诈嫌疑的一些人的特征,并提出了一套行为事件流时序模型框架。这套框架的提出基于一个很自然的想法:这些年大家多用深度学习,尤其是 LSTM(基于深度循环网络的特征提取框架),它特别适合处理时序型数据。所以我们就把这类序列行为编码到我们的 LSTM 模型里去。
同时我们是一个非常看重实际使用效果的公司,所以做到这一步还不够,我们还有一套框架是用 CNN 的模型对序列行为进行衍生特征的提取。这个过程中我们会得到额外的信息量,今天我也很难解释这两者结合起来为什么效果会更好,对具体结果感兴趣的,可以看看我们在 KDD 2018 上面的论文。
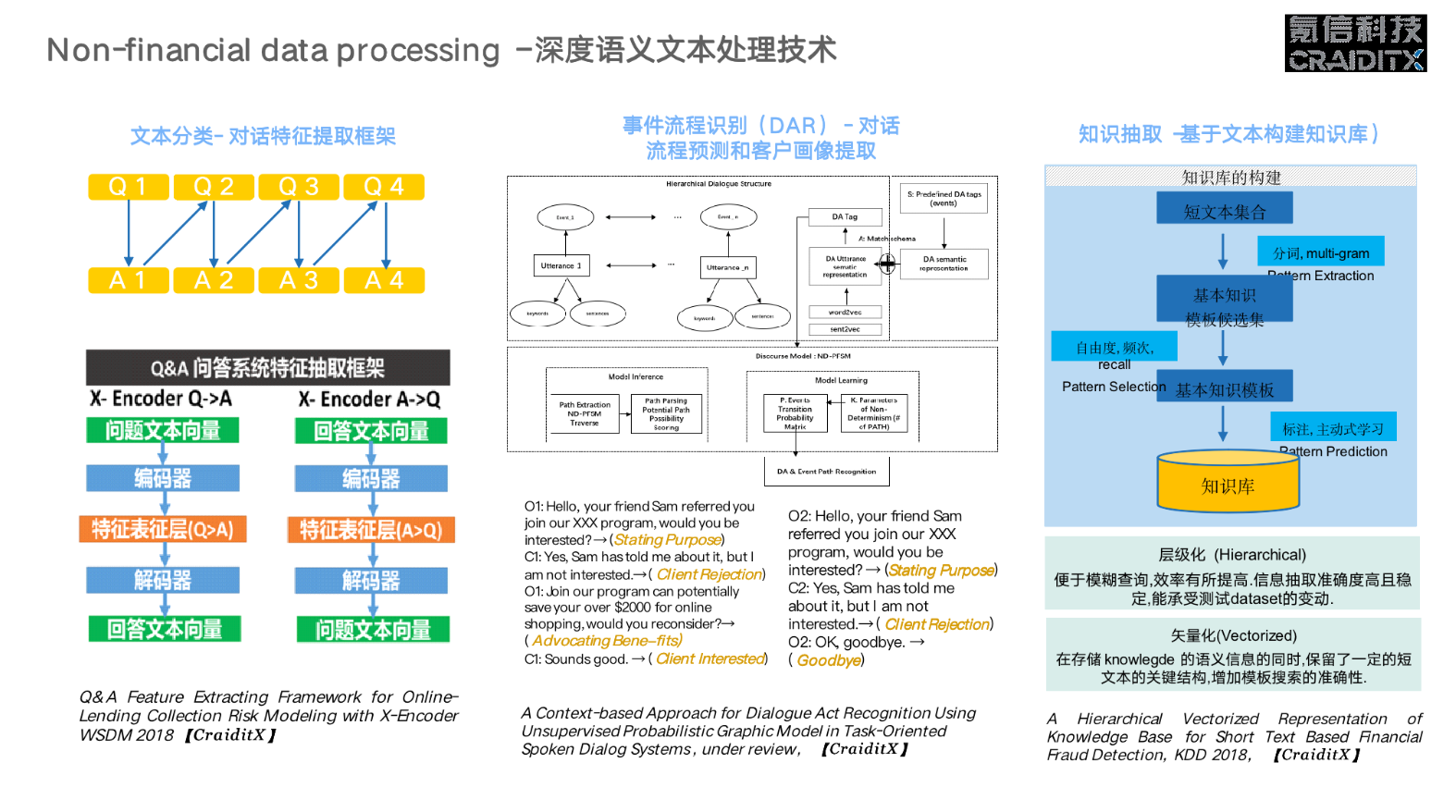
这是文本类数据的处理方式。在金融行业,以前大家可能对文本数据束手无策,因为你很难将一系列的对话文本转变成数字化变量,解释给计算机听,最后还能输出结果。当今全世界资源最多、最先进的 AI 公司,比如说谷歌和微软,也没有能完全解决人的自然对话难题。但是我们能做到什么呢?我们能做到在一个限定的场景里面,给出一个很好的结果。因为你每对它多做一层限制,你的计算复杂度就会降低很多,在有限的计算资源和技术条件下,就能得到一个足够好的效果。举个最极端的例子,如果能简化到一个问题,其实应用规则就可以解决了。这个领域的学术成果,我们也有几篇论文。
第一篇论文主要讲我们建了一套 QA 问答体系的特征,从一段文本最后变成数值化的向量,其实是有标准做法的。但是我们发现,在一个限定的场景里,比如说客服场景是一问一答的方式,单单用 X-Encoder(基于无监督深度学习的特征提取框架)是不够高效的,于是我们做了一套针对 QA 的基于 X-Encoder 的催收风险模型交互式特征提取框架,专门适合金融领域的一问一答。
第二篇论文是关于提取客户标签的,通过对话把你的 context 提取成标准事件。这件事的关键点在于,今天金融机构的客服人员,都是被训练成机器一样在工作,一个新人招进来以后,就用标准化的培训模板去教导他,告诉他比如客户讲了这句话以后,你要讲哪些话,怎么给客户打标签等等。所以我们的工作是构建一个知识库,建立标准对话流程预测体系,让这个新人可以更快地上手。我们更长远的打算,是希望机器训练机器,而不是机器训练人。今天我们和一些合作伙伴一起,已经在做这方面的探索,后续应该有更多有趣的工作出来。
第三类网络数据,因为个人数据非常有限,尤其在金融领域,我们大家都在讲大数据风控,其实需要大量的训练样本,但金融场景里面的训练样本是非常宝贵的,比如你想获得一个人是坏人的样本数据,那么至少得有一笔几万块的坏账,这个成本非常高。这跟我们以前做互联网预测分析不一样,用户喜不喜欢一部电影,一个广告,或者一个手机壳,这件事情的成本没那么高。
我们的做法是找到类似的人,从他的申请资料和社交关系上面去抽取知识,做聚类。当你发现了一个坏人,那么跟他类似的那群人是坏人的概率就非常高。也就是说,当你找到有效的群体之间相似这种关系以后,是有助于对个体风险做识别的。当然仅仅个人的大数据还不够,我们还需要借助更多的大数据,最后用集成模型把个人的风险特征和局部网络、全局网络上建立的风险特征结合在一起,提升风险预测效果。
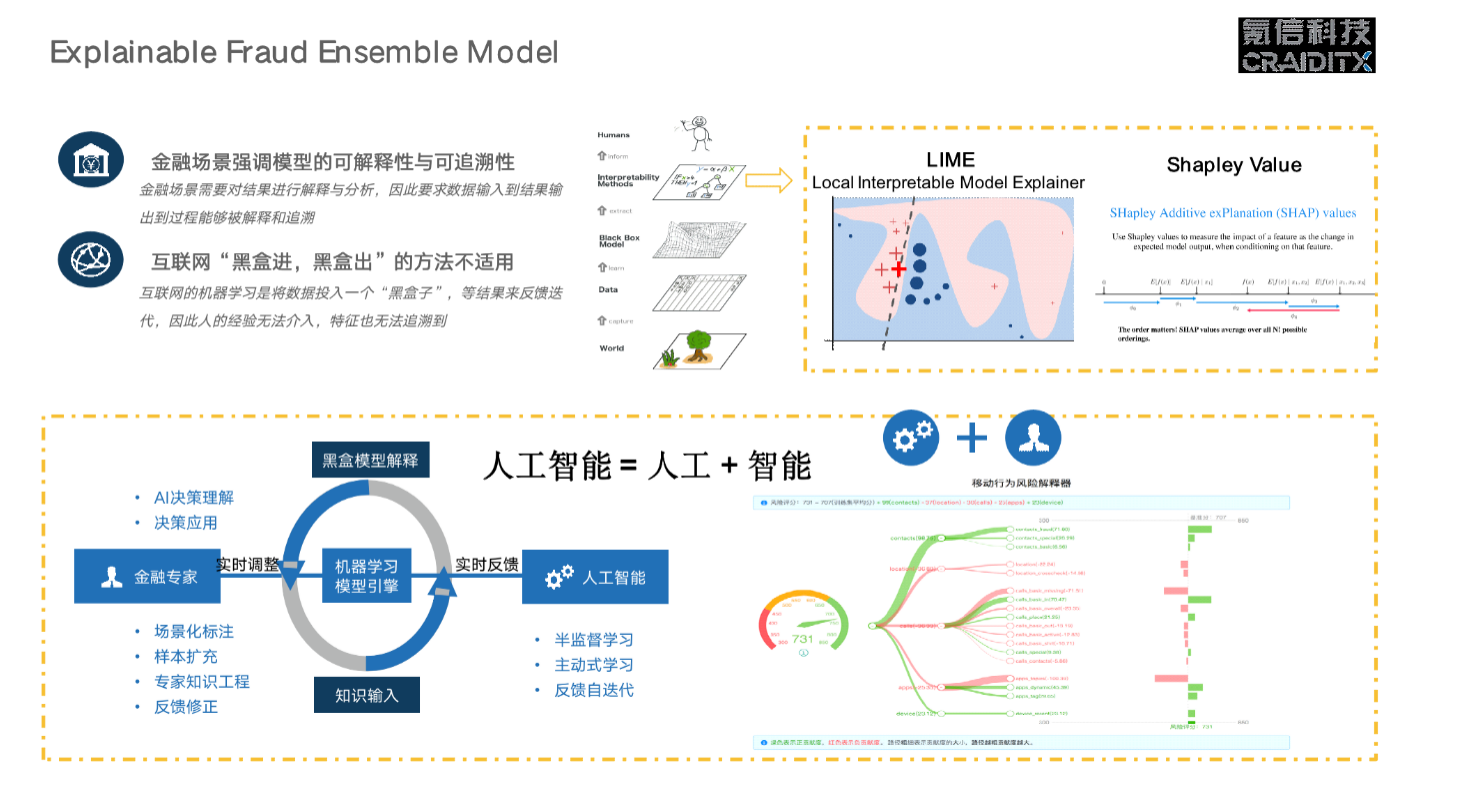
模型的可解释性:AI下一个突破点
刚才讲的是几种不同类型的另类数据处理办法,这个过程中我们始终有个挑战,那就是你做的模型是一个黑盒,没有办法解释。我不能告诉金融机构,谁用了这种方法效果很好,这对金融机构来讲是不能接受的,你一定要告诉他为什么。这其实也是整个 AI 领域最头痛的事情,在业务场景特别明显的地方,比如医疗领域,困难更加明显,比如 AI 诊断说要切掉一条腿,为什么?你不能说是 model 预测的,或者最后说 model 出错了,那这个医院肯定是会关门的。
所以模型的可解释性是深度学习突破之后 AI 面临的新挑战,在通用模型上目前我还没有看到特别好的解决办法。但是在具体的金融场景里,我们可以在某种程度上给出解释。有两个办法:一个是局部的近似,用低维模型拟合高维模型,它参考了博弈论里面的东西,最后得到最优的决策,是倒推博弈论的过程,这个我们有成型的产品,用在了我们的风险解决方案里面;第二个是把 AI 模型里最重要的几个特征变量找出来,解释给业务专家听。

效果第一
刚才讲的是技术,现在可以看看实践的结果,左边第一个是带有时间先后序列特征的结果。指标得话主要就是模型区分度,KS 值和 AUC。按照 KNN 的通常做法 KS 值是 0.142,再用一个神经网络去做 MLP,KS 值达到 0,167。加上这些特征以后,进一步提升到 0.203,在一个典型的场景上,加上行为数据,KS 值可以做到 0.216,差不多提升了 50% 以上。
第二个是短文本信息提取模型效果,传统做法和利用 AI 模型的做法在数值表现上差不多,但是后者的扩展性更强,因为原来要求人非常有经验,时时想着应对策略,有了这个框架以后就不用人费力去调参了,机器会替代部分人力工作。
第三个是对社交网络数据的使用效果,如果只是单纯用个人的风险数据,KS 值是 0.3,加上我们基于图的特征以后,有类似于人群的特征,很明显提升到 0.38,这是非常了不起的结果。
右边是加入上述三种类型数据以后的综合表现,我们也可以看到 KS 值是不断增长的。
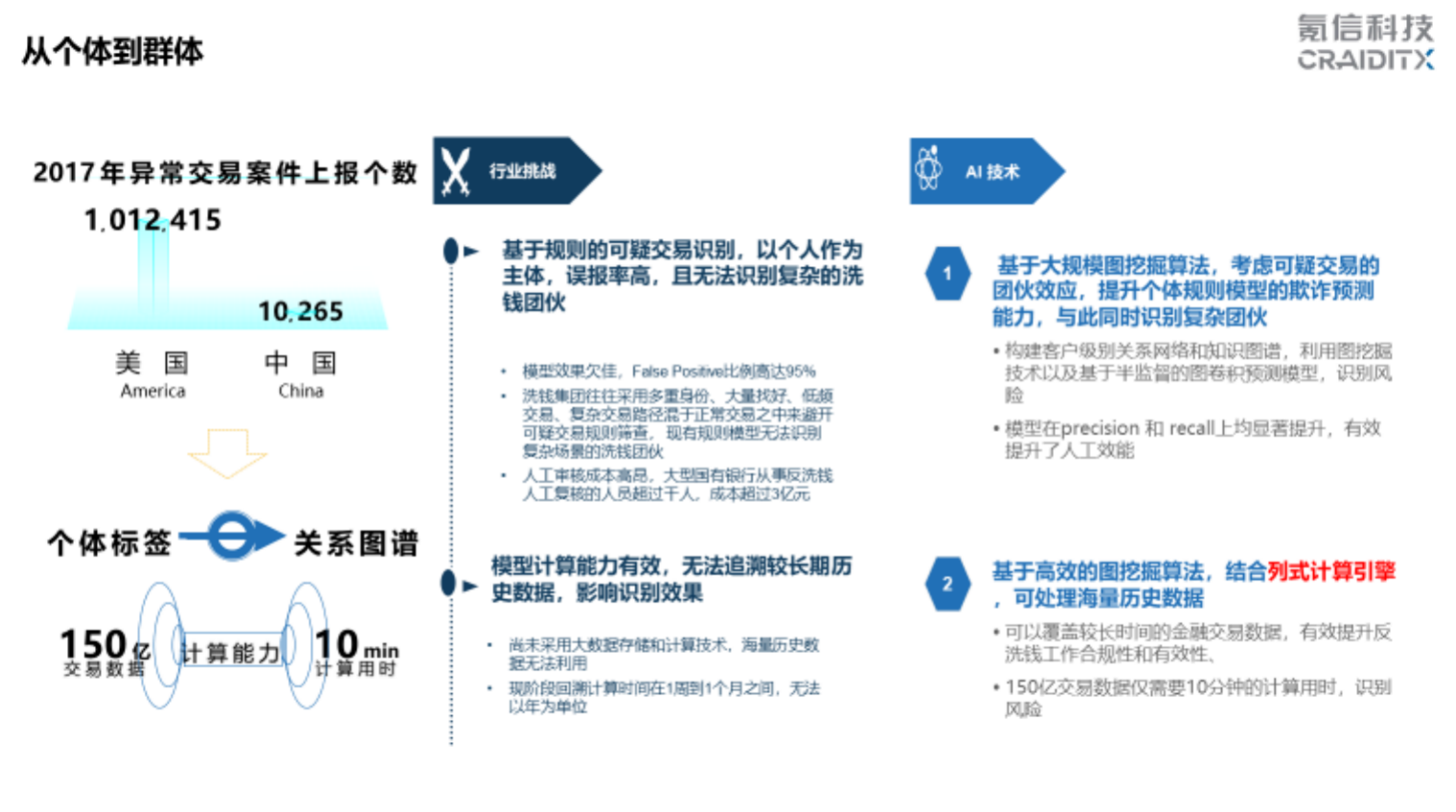
从个体数据处理经验迁移到群体
刚才讲了个体风险的一些数据处理经验,现在讲讲群体的风险及解决方案。这两年监管对反洗钱和可疑交易监测要求很严格, 以前国内监测个人的欺诈风险,主要是基于规则和个人上报,风险运营部门会用很多人工去找,效率很低,现在欺诈的手段层出不穷,就需要用人的规则和以前发生过的欺诈事件训练机器去抓。原来为了抓可疑交易,假设要雇一百个人人工去看,现在是一百个风险运营的人等着看机器提供的样本是不是对的,再反馈给机器,让机器训练得更加准确。
这里的关键是使用图算法。在互联网行业专门有做图算法、图解决方案的公司,它们提供解决方案,但一直没有很成功。总结原因主要是两点,一是要根据行业知识来做降维;二是需要一套有效的计算体系。我们的列式计算引擎能够在 15 分钟内处理百亿级别数据,这在以前是很难想象的。
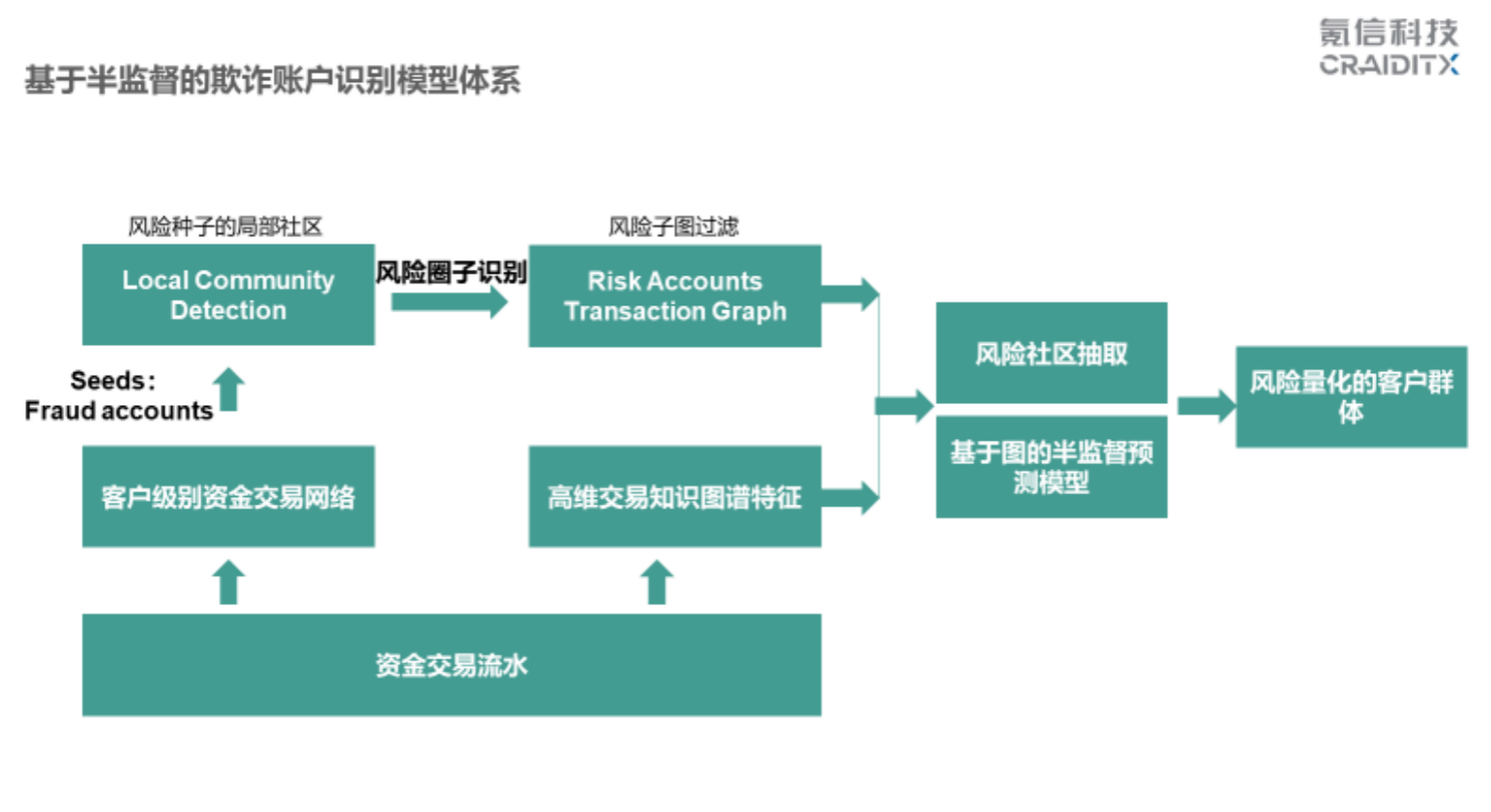
还有五分钟,我大概讲一下处理的方法。最下面是原始资金的交易流水。我们知道银行的交易流水量非常大,不大得话,人工就可以解决了。交易流水形成两个东西:
首先互相帐户往来会建立起一个大的 Graph,我们会给定以前的可疑种子结点,经过局部社区算法找到跟它关联的可疑子社区,比如说放进去 10 万个可疑种子,找到 10 万个跟它相关的社区。这 10 万个社区里一共是上亿的帐户。其中 90% 以上的都是好人,我们就对其余 10% 的人群进行重点布控。
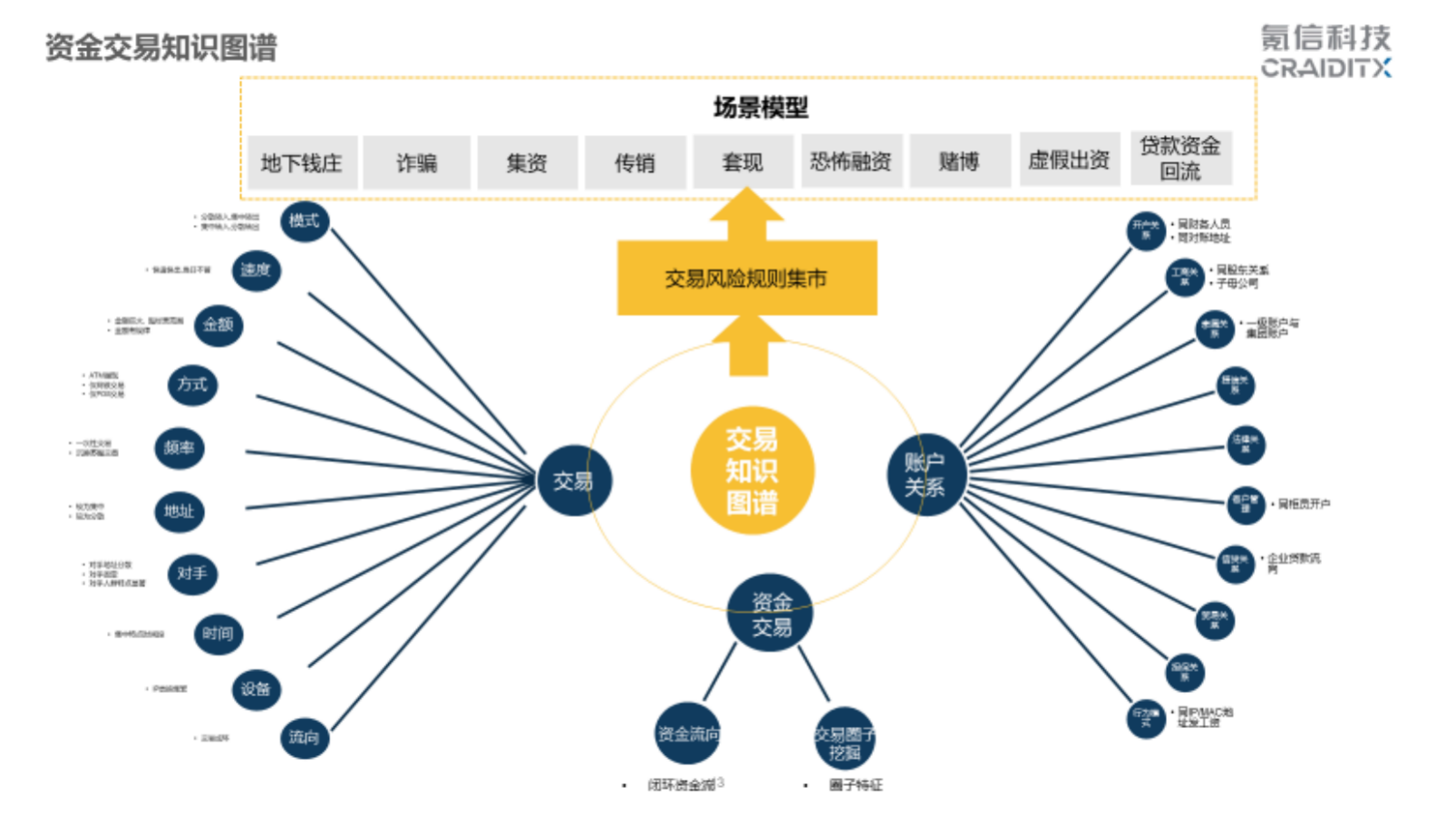
另外,我们基于风险专家的经验形成风险知识图谱,这是一般风险专家会去考虑一个交易往来的特征,从金额、模式、速度、场景方面考虑。
结合这两个东西来做图的深度学习预测模型。有了这个模型指导以后,由单个种子去触发。使用 ACL 优化的 PPR 算法,加上 Sweep-cut 算法,实现大规模的挖掘。最后做到一件事情:通过种子的节点去找密切的社区,学到图的结构,找到更可疑的人。

讲完原理,我再举个例子。比如一个大银行的房贷系统,发现几十个帐户都和叫「X 琴」的人有关系,和她的资金往来非常多, X 琴可能是中介,或者专门职业给人提供首付、中间过桥的,这里面肯定不正常。如果纯靠人工去找的话,很难从几十亿交易流水数据中找到这样的东西,但是通过图挖掘可以一目了然看到 X 琴的帐户有问题。
这是我们今天的分享,最后想说「AI+金融」的实践,我们作为外行,有幸和金融专家合作,得到还可以的结果。希望更多同学与我们有更多合作。
谢谢大家。


