

可能比你认的还全。
编者注:本文转载自将门创投(ID:thejiangmen),来源:machinelearning.apple.com,编译:Tom R,极客公园已获转载授权。
在智能和移动设备十分普遍的今天,手写字符识别的重要性愈加显现出来,在手机、便携设备、可穿戴设备以及智能手表上都会有十分重要的应用。对于移动设备端的设备来说中文手写字符识别需要大规模的字符库支持。
这篇文章阐述了我们如何在苹果的移动设备上实现实时手写中文字符识别的过程。通过深度学习技术这一系统可以在较高的精度下实现约 3 万个字符的识别。同时,为了实现较高的精度,研究人员十分关注数据的收集条件、书写形式的表达和训练规则。研究发现,在适当的条件下可以实现更大规模的字符库识别。同时检测精度随着库的增加只发生了轻微的下降,只要保证训练数据足够的质量和数量。
引 言
手写字符识别可以提高用户在移动端的使用体验,特别对于需要输入复杂中文的用户来说,这一功能显得尤为重要。由于中文字符十分丰富,中文手写字符识别一直面临着独特的挑战。与字母文字只有 100 量级字符的语言相比,中文拥有十分庞大的规模。根据国标 GB18030-2005,其中包含了27533 个中文字符以及其他在大中华区使用的语标字符构成。
为了便于计算,通常的识别对象集中在生活中的常用字符上。在另一国家标准 GB2312-80 中只包含了常见的 6763 个字符,其中一级高频词 3755 个,二级高频词 3008 个。国内有两个较为著名的数据集,分别是中科院自动化所的 CASIA 数据集(7356 个字符)和华南理工的 SCUT-COUCH。

这些字符对于中国人整体来说基本已经覆盖了常用的手写需要,但对于个体来说,常用的字符集往往因人而异。每个人都需要熟悉一些并不常见的字符,比如说每个人名字中的生僻字。所以理想的中文字符识别至少应该将范围扩展到国标 GB18030-2005 的规模才能基本覆盖大多人的日常生活需求。
早期的字符识别方法主要是基于结构和笔画分析的方法,这需要获取与笔顺无关而与整体字形有关的统计学模型。这种方法在大型文字库的情况下会十分复杂,使得字符的正确分类清晰辨认变得十分困难。
在拉丁语系的文字中,卷积神经网络(CNN)已经取得了很好的效果。在充分的训练数据下,CNN 已经能够实现很好的效果,但相较于中文字符来说,识别对象的数量还是太小了。
当我们刚刚开始着手解决这一问题时,CNN 是一个很自然的选择,但我们却面临着两个挑战。其一是需要检测对象的规模扩大到了约三万个,其二还需要实时地进行处理还是在 (嵌入式) 移动设备中。接下来我们将详细阐述在追求精度和速度中所面临的挑战以及字符和覆盖范围和书写风格的问题。
系统配置
我们采用了通常的卷积神经网络结构如图 1 所示。
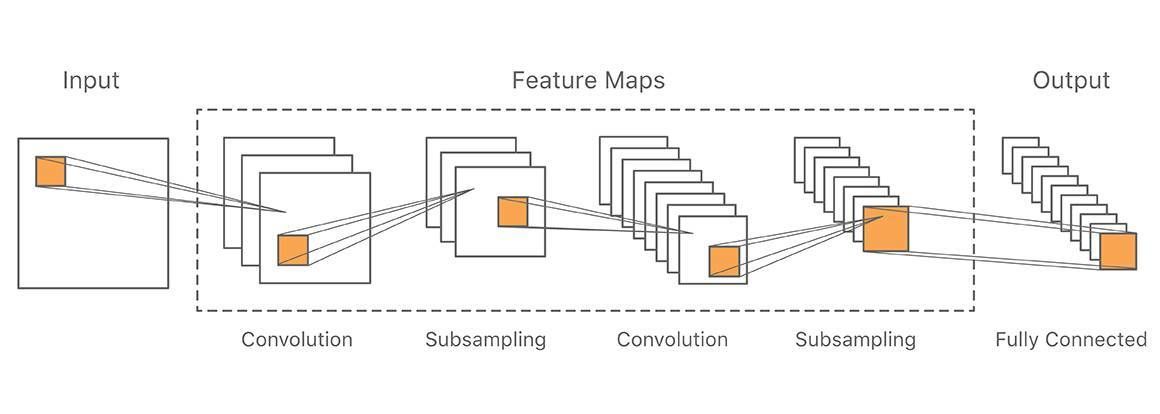 图 1 典型的卷积神经网络结构
图 1 典型的卷积神经网络结构
图中的输入是一个 48*48 像素的中文手写字符,随后通过卷积核下采样进行特征提取,在最后利用全连接层进行输出。在训练时,通过选择卷积核以及特征图的数量来不断提高特征的粒度。其中下采样利用了 2*2 的最大池化层,输出大概 1000 量级的小特征图。最后输出层每一个节点对应一个分类,可以是一级高频的 3755 个汉字,也可以是更大的 30000 多个更完整的字符集。
我们将上面的 CNN 用于 CASIA(中科院自动化所)数据集作为基准。这一测试只包含了一级汉字的字符集,主要是由于这一字符集存在很多的参考文献。同时研究人员还将 CASIA-OLHWDB,DB1.0-1.2 等数据作为研究对象,使得训练样本达到了一百万的级别。
需要注意的是,我们的产品目标并不是在数据集上得到最高的分数,而会优先考虑模型的大小和速度以及完善的用户体验。我们在考虑各方面的基础上做出了一个能识别广泛书写风格、适应性强的实时检测系统。同时我们还适度增加了一些灵活变形的观测样本。
表一给出了上图中 CNN 的结果,Hz-1 代表一级高频汉字(3755 字符),CR(n)代表 Top-n 准确率。除了 Top-1 和 Top-10 的准确率外,还加入了对于用户体验至关重要的 Top-4 准确。
 表一 在 CASIA 在线数据集上的结果,包含 3755 个字符,模型大小 1M
表一 在 CASIA 在线数据集上的结果,包含 3755 个字符,模型大小 1M
文献中 top-1 准确率为 93,%top-10 准确率为 98%,虽然我们的模型在 top-1 上准确率稍微下降,但在 top-4 上却有令人满意的准确率。准确率下降的原因主要是来源于与文献中模型相对较小的模型(1M)。
同时这一系统只在 CASIA 上进行了训练,没有额外的训练数据。我们随后利用从 IOS 设备上收集的更多数据对系统进行进一步训练,这些数据包含了不同的书写风格,而测试集的大小同样是 3755 个字符。
 表二 CASIA 在线数据集 3755 个字符的测试结果,基于增强训练的结果,模型大小为 15M。
表二 CASIA 在线数据集 3755 个字符的测试结果,基于增强训练的结果,模型大小为 15M。
可以看到尽管模型变为了 15M,但精度仅仅略微提升。这告诉我们虽然数据集变大了,但其中出现的大多数模式已经能够被 CASIA 数据集很好的覆盖。同时也证明了训练数据的增加不会破坏模型的效果。
扩大到 30000 个字符的规模
由于人与人之间的常用字各不相同,大规模人口的常用数据集远远超过了 3775 个字符,但到底选择哪一个字符是一个复杂的问题。研究人员采用了国家简体字标准的 GB2312-80 和繁体字标准的 Big5,Big5E, 以及 CNS 11643-92 和香港的 HKSCS-2008, 这些数据集甚至超过了 GB18030-2000 的规模。
我们需要保证用户在日常生活中的书写字符范围,包括简体字和繁体字,同时包括姓名、诗歌、常用标记视觉符号和表情等。我们同时希望这一系统可以支持基本的拉丁字符集以便不时之需。同时这套系统遵循国际标准的 Unicode。所以最后的系统主要集中于识别的汉字,包括 GB18030-2005,HKSCS-2008,Big5,Big5E 以及核心的 ASIIC 字符,同时包含一系列视觉符号和表情,共计约 30000 个字符,基本很好的涵盖了中国大多数用户的使用。——以上为识别范围的选择
在选定了目标范围后,最终的事情就是采集用户日常书写的风格。虽然从书写的特征可以将其归纳到不同的变种中去,但还是存在很多的挑战。包括 (i) U+2EBF 的 (艹) 写法, 或者 (ii) 草书的 U+56DB (四) vs. U+306E (の) 容易混淆. 同时被渲染过的字体会对一些用户特殊的书写习惯识别造成混淆。当人们快速书写时,字体就会变成草书或行书,一些字体便会产生混淆,例如「王」和「五」就会十分接近。最后,广泛的国际化会对字符的识别带来意想不到的影响,例如手写的「二」和字母「Z」就容易混淆。
这套系统基本上覆盖了从印刷体到草书以及各种自由书写的字体。为了覆盖尽可能多的字体,我们在大中华区的各个区域收集不同的字体。在这一过程中我们有了一个惊人的发现,大多数用户甚至都没有见过一些生僻字,更别说使用了。这会在实际使用中造成很多笔画错误和其他误差,是不得不考虑的问题。我们通过付费收集了来自不同年龄、性别和教育背景的人群字体,最终得到包含上千位用户用手指在 IOS 设备上输入的丰富字体。iOS 设备的一大优势便是字体的特征信号十分清晰。
我们发现了十分有趣的模式,对于同一个字有着不同的写法,下面是不同用户的「花」字。



我们可以发现日常生活中的手写字体变化十分丰富,有时候会对字体识别造成很大的影响。所以充足的训练样本对于识别手写和潦草的字迹十分重要。
下面是几个字符的对比,包括「的」、「以」、「王」和「五」。



在先前讨论的原则指导下,研究人员收集了上千万的训练数据。在训练过后,下表是识别能力 30000 字符在 CASIA 上的识别效果。
 表三 在 CASIA 上的测试结果(30k 字符)
表三 在 CASIA 上的测试结果(30k 字符)
其中模型的大小与前文保持一致,随着数量的增加准确率些许下降,这主要是来源于分类数目的增加和一些手写字符造成的混淆,例如「二」和「Z」造成的影响。
比较表 1 到表 3 我们可以发现识别的数量提高了近十倍但是准确率和模型并没有十倍的变化,在保持模型大小(效率)的情况下,只损失了很小的精度,就将识别范围从 3755 扩大到了 30k 的量级。
为了检验这一系统在整个 30000 个字符上的性能,研究人员在不同测测试集上进行了测试并得到了表 4 的平均结果。
 虽然表三和表四的测试集不一样,结果不能直接比较,但我们可以看到其 top-1 和 top-4 精度大致相同,这表现出了训练数据的均衡性。
虽然表三和表四的测试集不一样,结果不能直接比较,但我们可以看到其 top-1 和 top-4 精度大致相同,这表现出了训练数据的均衡性。
一些讨论
由于表意报告员组(IRG)不断提出来自各种来源的新增内容,Unicode 中的 CJK 字符总数(目前约为 75,000)可能还会增加。诚然,这些字符变体会是罕见的(例如,用于历史名称或诗歌)。但对于那些恰好名字里含有这些偏僻字的人来说还是很酷的。
那么,我们怎么在未来处理更大量的人物信息呢?本文所讨论的实验支持基于训练和测试错误率的学习曲线,并给出了不同数量的训练数据。因此,我们可以推断出渐近的值,即我们的准确性与更多的训练数据是相似的,以及它将如何随着更多的字符而改变。
例如,考虑到表 1 和表 3 之间的 10 倍更大的库和相应的(少于)2%的精度下降,我们可以推算出 10 万个字符的库和相应增加的训练数据,top-1 精度达 84%左右,top-10 精度达到 97%左右(具有相同类型的架构)。
综上所述,我们在嵌入式设备上构建覆盖 3 万个字符的高精度手写识别系统还是很靠谱的。只要有足够数量和质量的训练数据,识别的精确度随着库存量的增加只会有少量的降低。这对识别未来更大的字符库是来说无疑是巨大的强心剂。
-END-


