

为什么做自动驾驶需要世界模型?
6 月 4 日,被誉为「学术界奥斯卡」的全球计算机视觉顶级会议 CVPR 2026 在美国丹佛开幕,小鹏集团第三次受邀发表演讲,通用智能中心负责人刘先明首次展示小鹏世界模型技术图谱。去年此时,刘先明作为中国车企唯一的受邀者介绍了小鹏的第二代 VLA 模型。这一次,世界模型和第二代 VLA 拼出了小鹏基座模型的全景图,也回答了业界普遍关注的问题:小鹏智驾是如何实现技术跃迁的。
作为 AI 领域最有影响力的顶会,CVPR(The IEEE/CVF Conference on Computer Vision and Pattern Recognition)历来都是 AI 研究的风向标,而「具身智能」毫无疑问是今年的 TOP 级议题。今年大会首次开设「具身智能基座模型部署研讨会」,邀请特斯拉 AI 软件副总裁 Ashok Elluswamy、小鹏集团通用智能中心负责人刘先明等分享各自团队的研究成果。
去年同期,刘先明在 CVPR 首次披露正在研发中的基座模型。不到一年时间,基于基座模型、也就是第二代 VLA 的辅助驾驶软件正式量产,完成了从研发创新到商业应用的重要跨越。凭借远超传统架构模型的安全、舒适、效率表现,第二代 VLA 改写了很多用户的辅助驾驶体验,推送首月就创下「辅助驾驶里程占比超过 50%」的行业里程碑,成为国内辅助驾驶的全新标杆。
第二代 VLA 是怎么做到的?在 CVPR 现场,刘先明进一步打开小鹏的物理 AI 卷轴,展示小鹏基座模型的另一支柱:世界模型。他说,小鹏集团正在研发具备主动思考、可控生成和长时序推演能力的世界模型。世界模型与第二代 VLA 不是互相替代或互相竞争的关系,而是通过不同训练信号共同提升模型对物理世界的理解能力和在物理世界的行动能力。
「走 VLA 路线还是世界模型路线?」对于这个争论不休的技术议题,刘先明的回答是:小鹏物理世界基座模型,是第二代 VLA,也是世界模型。它们本质上在做同一件事:通过不断放大模型规模、数据规模和训练目标的复杂度,训练足够强大的物理世界基座模型。
「学习人类」和「从世界中学习」
刘先明介绍,在小鹏的基座模型架构中,第二代 VLA 主要从人类驾驶行为中学习,将视频流、指令与动作输出进行统一建模,掌握在复杂交通环境中合理行动的能力;世界模型则通过对未来状态和场景演化的预测,学习物理世界的运行规律,并支持可控生成、长时序推演和因果推理。前者让模型学习「如何行动」,后者让模型理解「行动之后世界会如何变化」。
二者结合,最终目标是构建能够深度理解真实世界并在其中安全行动的物理 AI 基座模型。
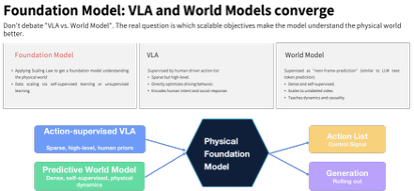
小鹏物理世界基座模型技术图谱
人类动作包含丰富的高层语义,隐性地编码了感知、推理、意图、风险判断、社交互动以及对物理世界的理解;只是这类监督信号在时间上相对稀疏。它通常只能监督最终的行为结果,而难以覆盖促成这一行为过程中每一次潜在的物理状态转移。
世界模型则是从世界本身中学习的。它不只是预测下一步动作,还可以预测未来状态、未来观测,或者潜在空间中的未来表征。相比之下,它所获得的监督信号要密集得多:每一帧画面、每一次运动、每一次交互都可以成为训练信号。世界模型借鉴了大语言模型中「下一个 Token 预测」的范式,通过在海量未标注视频上进行下一帧或下一状态的密集预测,逐步学会物理世界的动力学与因果结构。
通过这种融合架构,小鹏成功将稀疏的人类意图与密集的物理预测相结合,使得模型不仅在学习「人类驾驶员会怎么做」,更在深度理解「物理世界接下来会发生什么」。这种双重目标的并行演进,确保了系统在复杂环境下的可控性与安全性,也为自动驾驶系统赋予了更深层次的物理感知与逻辑推理能力。
主动思考、可控生成和长时序推演
刘先明认为,一个优秀的世界模型必须具备三大能力:主动思考、可控生成和长时序推演,这是智能的体现,也是世界模型能在自动驾驶领域应用的前提条件。事实上,小鹏研发团队近期发表了一系列与世界模型相关的学术论文,围绕这几个核心能力拆解小鹏世界模型的研究方法。
《X-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving》介绍了 X-World,基于视频扩散生成技术构建的可控多视角生成式世界模型,能在给定动作条件下生成符合物理约束的未来视频,同时在持续生成过程中保持良好的可控性与稳定性。X-World 现已投入到闭环仿真测试、在线强化学习、数据生成等研发环节。
《X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling》介绍了 X-Foresight,一套基于预测式世界模型的视觉-动作因果预测网络,X-Foresight 在架构上与 VLA 融为一体,在统一的 token 空间内联合预测未来的多视角画面与自车动作,为 VLA 的控车决策提供了核心支撑。X-Foresight 的预测式决策逻辑,倒逼模型「理解世界」,掌握车辆、行人运动规律与场景因果链条。
此外,小鹏研发团队还在《X-Cache: Cross-Chunk Block Caching for Few-Step Autoregressive World Models Inference》中提出了「世界模型加速器」X-Cache,一个面向少步自回归世界模型的跨段块级缓存,能在基本不牺牲画质的前提下,减少约七成的重复计算,对世界模型的去噪主干实现最高约 2.7 倍的推理加速。
刘先明透露,近期还将发表名为「X-mind」的论文,解析模型如何「主动思考」,并可视化地呈现驾驶决策背后的中间推理过程。可解释性对于自动驾驶的软件性能调试、用户信任建立以及模型快速迭代都至关重要。
Scaling、Scaling,还是Scaling
去年 CVPR,刘先明的演讲题目是《通过大规模基础模型实现自动驾驶的规模化》(Scaling up Autonomous Driving via Large Foudation Models),他明确表示,小鹏研发团队验证了规模法则(Scaling Law)在自动驾驶 VLA 模型上的持续生效。做 AI,没有那么多「炸裂」和「震惊」瞬间,更多是持之以恒践行规模法则这样「简单的道理」,不断挖掘技术红利。
探索规模法则的上限始终是小鹏团队的追求,过去一两年,研发团队通过提升模型、算力、数据的规模,不断摸高基座模型的性能。目前,小鹏第二代 VLA 模型拥有数十亿参数量,使用了上亿的视频片段作为训练数据,每版模型的训练量超过 4 万亿 Token。
小鹏集团此前透露,研发团队平均每天能够迭代数版模型。「进化速度」很可能成为小鹏自动驾驶的重要护城河,而速度的背后是强大的 AI 基础设施能力。小鹏是国内最早建成万卡以上规模智算集群的企业,在截至今年 3 月的一年间,小鹏集群的单 GPU 训练效率提升了 1010%、单任务训练效率提升了 4360%,GPU 硬件利用率从 40% 提升到了 90%,达到头部 AI 公司的标准。

另一方面,小鹏对车端算力的「压榨」也可谓极致,通过芯片、编译器、模型的软硬件联合开发,小鹏大幅提升了车端芯片有效算力,将车端模型推理速度提升了 12 倍。刘先明展示了三组芯片&模型组合的对比数据:使用开源模型和通用芯片,计算利用率为 22.8%、推理时延 800 毫秒;使用开源模型和小鹏自研的图灵芯片,模型计算利用率为 35.1%、推理时延 300 毫秒;使用自研的第二代 VLA 模型和自研图灵芯片后,计算利用率大幅提升到 82.5%、时延压缩至 80 毫秒。
据悉,自动驾驶只是小鹏基座模型落地的第一步,未来,基模还将应用到机器人、飞行汽车等更多具身载体。小鹏人形机器人 IRON 面向量产版本的软硬件研发进展顺利,即将进入软硬件合围阶段。
刘先明不止一次表示,只有能做基座模型的公司,才有可能真的做到 L4,并进一步赋能机器人、飞行汽车等多种具身载体。而基座模型,本身就需要软-硬、端-云、AI 研发-先进制造等全栈技术的托举。
附:小鹏世界模型相关论文
X-World 论文:https://arxiv.org/pdf/2603.19979
X-World 页面:https://x-world-1.github.io/
X-Cache 论文:https://arxiv.org/abs/2604.20289
X-Cache 页面:https://x-cache-1.github.io/en/
X-Foresight 论文:https://arxiv.org/abs/2605.24892
X-Foresight 页面:https://x-foresight-1.github.io/en/


