
「山海·知音」大模型 2.0——依托「山海·Atlas」的多模态、跨语言基座能力,让「山海·知医」等垂直专业智能体,惠及千家万户。
随着智能体时代到来,云知声在「山海·Atlas」通用智算基座持续演进基础上,年前实现了「山海·知医」5.0 医疗大模型升级,今天迎来了「山海·知音」2.0 的重磅发布,正在完成「一基两翼」技术战略升级的能力拼图。
「山海·知音」大模型 2.0——依托「山海·Atlas」的多模态、跨语言基座能力,让「山海·知医」等垂直专业智能体,惠及千家万户——听懂专业与乡音、聊出亲情与温度、极致机敏反应,是本次升级的三大能力进化。
01 听懂专业与乡音——ASR 全景升级
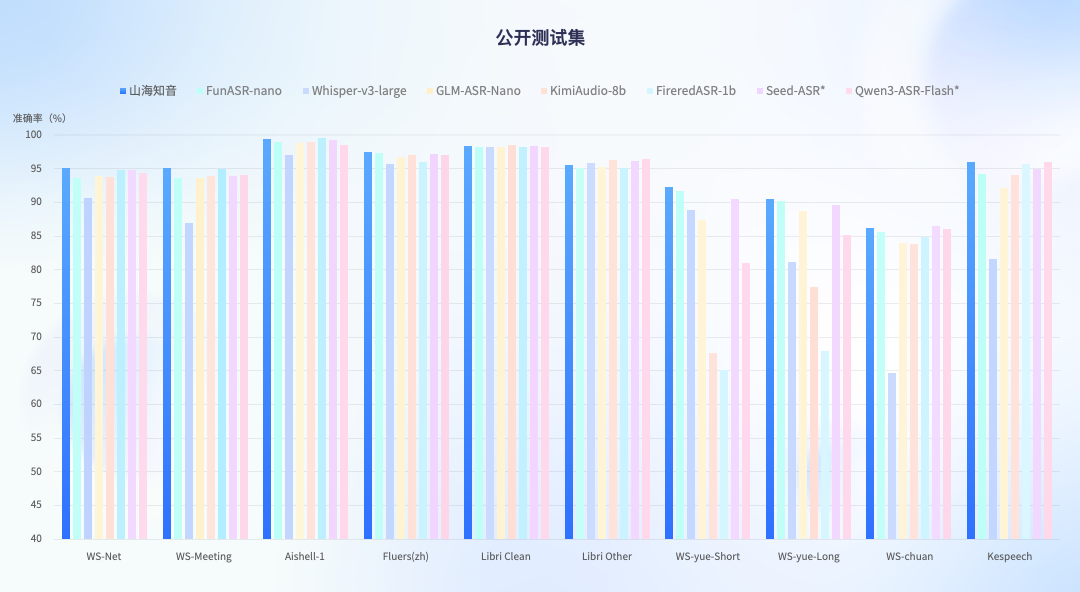
此次模型 ASR 能力在公开测试集和自有全场景测试集中,均显现了领先的语音识别能力,在评测中实现了从通用到极端全面的领先水平,超过了国内主流的开源和闭源语音大模型,达到业界最高水平。特别是在高难度的复杂噪音与方言口音场景下,相比主流 ASR 模型性能提升了 2.5% 至 3.6%,在复杂背景音环境下识别准确率更是在业内首次突破 90%。
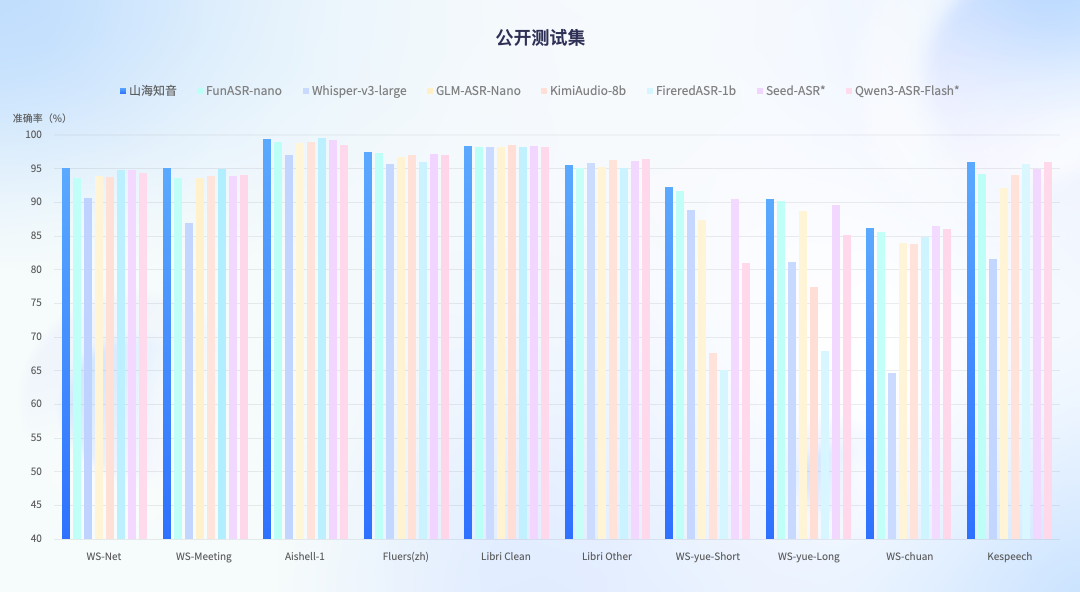
公开测试集
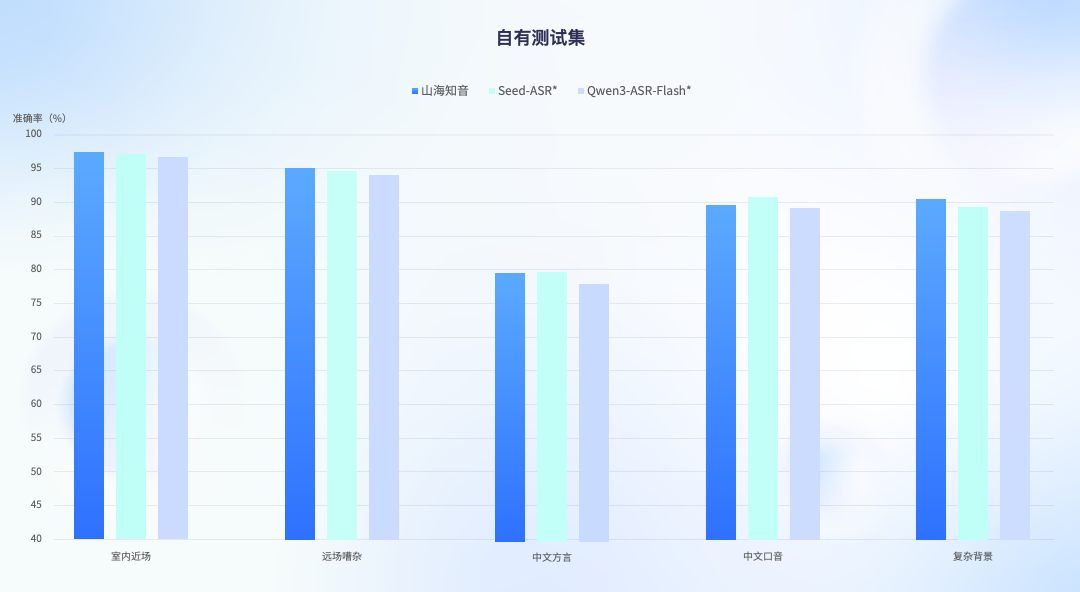
自有测试集
真实的语音识别环境中,还经常会面临专业术语识别不清、逻辑混乱等挑战。作为此次升级中最大的亮点,即模型「能够听得懂专业话」,它可结合上下文和行业术语,听懂专业场景中的每一个术语与指令,识别精度提升 30%。「它不是在『听字』,而是在『理解事』」。
例如在汽车 4S 店试驾场景中,当销售提及「方向盘」相关描述时,即使上下文未明确出现「半幅方向盘」,模型仍能通过逻辑推理准确识别。
而在严肃的医疗场景,模型能显式注入「依帕司他」「二甲双胍」等术语进行定向增强,确保识别结果更精准。
同时,模型支持 30 余种中文方言及 14 种国际语言的识别转写,无论是晦涩的粤语、闽南语、上海话,还是英、日、韩、法、德、泰等国际语言,均能实现精准转写。更进一步,模型还能融合讲义等视觉语义,构建「视听融合」闭环交互,进一步提升识别结果。
02 聊出亲情与温度——TTS 声动进化
如果说 ASR 能力是「耳朵」,那么 TTS 能力便是「嘴巴」。山海·知音-TTS 以「高度拟人+创意多元」为核心,让语音合成兼具真实感与创造力,使科技更有温度。
它目前支持 12 种方言(粤语、四川话、上海话全拿下)+ 10 种外语,清嗓、笑声、呼吸声都自然还原,甚至能切换 12 种普通话风格,温柔、干练、亲切随你选。「科技不该高高在上,而该用你最舒服的方式说话。」
目前模型已支持粤语、四川话、上海话等 12 种方言,以及日语、韩语、泰语等 10 种外语。可实现跨方言、跨语种、跨情感的组合生成,针对小语种的语音韵律也进行了专项优化——如日语的「促音」、泰语的「声调变化」,合成自然度接近母语使用者。
此外,还支持一句话声音复刻以及播客级长文本合成,赋能有声内容创作与互动娱乐。
基于大模型的语音合成通常采用流匹配 (Flow Matching) 将大语言模型预测的语音 Token 转换为梅尔谱,再通过神经声码器 (Neural Vocoder) 重建为最终语音。但该方案普遍存在延迟较高的问题。业界常通过流匹配分段处理来降低延迟,但效果有限,且容易牺牲音质。
为实现真正高质量、低延迟的流式语音生成,云知声创新性地设计了基于纯因果注意力机制的流匹配模块,并与神经声码器进行联合优化,构建出端到端的纯流式推理架构。该方案在不损失合成质量的前提下,显著降低系统延迟——在低并发场景下,首包延迟已压缩至 90 毫秒以内,达到业界领先的实时交互水平。
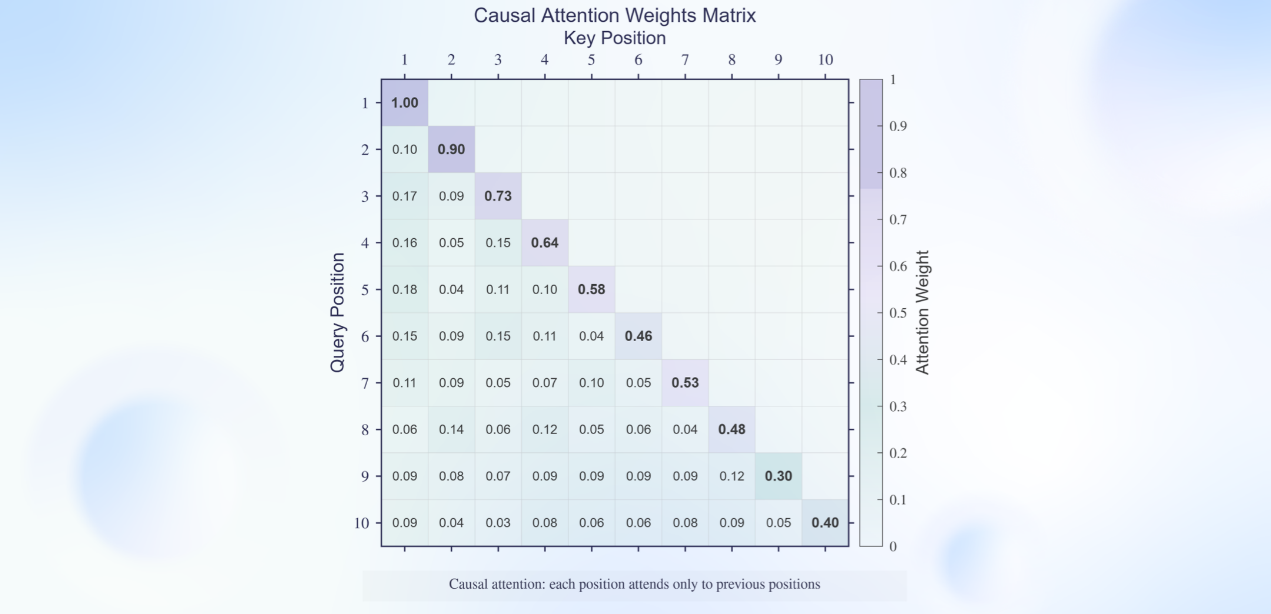
因果注意力机制
03 极致机敏反应——端到端全双工交互
真正的智能交互,在于「理解语境、感受情绪、自然回应」。端到端模型实现流畅全双工面临的核心挑战是:需在流式收声时同步完成理解、决策与生成,并在任意打断瞬间保持对话状态连贯。山海·知音 2.0 基于端到端交互大脑攻克了这一难题,将全双工能力提升至新高度。
支持随时打断、即时接话、连贯追问,就像和一个真正聪明的朋友聊天,行云流水,毫无卡顿。「这不是问答,是对话。」
背后是谁在支撑这一切?
答案是云知声独创的「山海·Atlas」智算一体基座,将通用多模态大模型底座与 Atlas 基础架构深度整合,既是专业智能体的基础,也是感知 AI 中枢的根基——将传统的 ASR、TTS 和全双工能力,有效整合到端到端大模型中,做到传统模块级联无法实现的极致交互体验和效率。
智起山海,知音万物
从手术室到乡间小路,从驾驶舱到老人床头,
云知声相信:真正的智能,不是炫技,而是融入生活。
山海·知音 2.0,
让 AI 不再「人工智障」,
而是听得清、说得真、懂人心的伙伴。
这一次,AI 终于学会好好说话了。
来源:互联网


