

1 月 5 日,拉斯维加斯。黄仁勋再度向全球抛出「重磅炸弹」——Rubin。
1 月 5 日,拉斯维加斯。黄仁勋再度向全球抛出「重磅炸弹」——Rubin。其训练性能是 Blackwell 的 3.5 倍,AI 软件运行性能飙升 5 倍;但推理成本,仅为前代的 1/10。但这种惊人的表现,却是被逼出来的。实际上,TPU 和可重构数据流架构(RPU)的崛起,正凶猛侵蚀英伟达的霸权。

去年 11 月,Meta 拟采用谷歌 TPU 的传闻一出,英伟达一夜蒸发数千亿美元。焦头烂额的黄仁勋,不得不光速出手,将可重构数据流芯片公司 Groq 收入囊中。如今,Groq 的并购与 Rubin 的发布,共同指明了 AI 芯片的「收敛时刻」:更高性能的通用芯片,才是所有人要奔赴的终极战场。
疯抢高阶 TPU
2025 年圣诞节,英伟达豪掷 200 亿美元(约 1400 亿人民币),买了一家「非 GPU」公司——Groq。英伟达以其持有现金三分之一的巨资,打包买走了 Groq 的核心技术、图纸和核心人才。
三个月前,Groq 的估值还仅为 69 亿美元。如今,黄仁勋抛出 3 倍溢价,对 Groq 志在必得。而 Groq 主攻的,是特有的 LPU 芯片技术,即用软件定义硬件的「可重构数据流架构」。这种独特的设计,能让 LPU 在处理大模型时,实现 Token「瞬时」+「准时」的吞吐,超越 GPU、TPU 的物理极限,实现比 GPU 快 5-18 倍、能效比高 10 倍的突破,加之 Groq 是由谷歌 TPU 之父创办,因而被称为「高阶 TPU」。这是英伟达真正缺乏,或许也是让黄仁勋心动不已的技术。

在 AI 从「训练」向「推理」转换的时代,可重构数据流架构将是 GPU 难以抵挡的存在。感受到风向的,不只是英伟达。去年底,英特尔已与美国可重构 AI 芯片独角兽 SambaNova 签下一份收购意向书,要在可重构赛道施展拳脚。而在大洋彼岸的中国,一则中国芯片企业融资的消息,同样意味深长。2025 年 12 月 2 日,北京四大明星芯片公司清微智能宣布,完成超 20 亿元人民币的 C 轮融资。清微智能打造的 RPU,与 Groq 的 LPU,属于同源的可重构数据流技术路线。中美两国的超级资本,几乎不约而同押注在「可重构」这个关键战场。
2026,三大流派争雄
在「榜一大哥」们相继投下重注后,2026 年 AI 芯片三大技术流派至此可见端倪:一是 GPU 派,二是 ASIC 派,三是可重构数据流派。
GPU 派,以英伟达、摩尔线程为代表,是当今 AI 芯片领域的绝对霸主。但 GPU 芯片的性能提升,非常依赖于半导体制程的极限突破,以及 HBM 带宽的艰难提升。当「内存墙」、高功耗等问题席卷而来,GPU 为通用性付出的代价,让效率的进一步提升困难重重。于是,就有了 ASIC 派,以谷歌 TPU、寒武纪、百度昆仑芯为代表。ASIC 架构,走的是一种「特种兵路线」。它是一种为特定算法深度定制的集成电路,通过将硬件与算法深度绑定,实现 AI 运算的极致能效。
但 ASIC 的短板也很明显,一旦算法迭代,硬件难匹配,芯片就有过时、甚至被废的风险。那 AI 芯片,能不能既能实现高性能、低功耗,又能够根据算法变化,实现硬件灵活重构?
于是,「可重构数据流派」正式登场。像 Groq 的 LPU、清微智能的 RPU,都属于这一派。它的核心,是「软件定义硬件」。也就是说,RPU 内部的硬件资源,可通过软件指令、实时重组,所以像一条可以随时调整工序的智能流水线。这种兼具 ASIC 高效能和 GPU 灵活性的可重构芯片(RPU),又被称为芯片界的「变形金刚」。
它究竟有多强?以清微智能量产的 TX81 芯片为例。一台搭载可重构 TX81 芯片的 AI 训推一体服务器,就能搞定万亿参数大模型的部署。像 REX1032 训推一体服务器,单机支持 DeepSeekR1/V3 满血版推理,成本大降 50%,能效比提升 3 倍。
所以 2026 年开年之际,三大技术流派的定位,突然尘埃落定:GPU 派在训练和通用计算中虽然保持核心地位,但 ASIC 派,正用极致能效比,主攻特定模型的推理场景,让云厂商降本增效;而可重构数据流派,更以其灵活、高效、确定性,成为多元化 AI 芯片生态的重要力量。这个曾被国际半导体界誉为「未来最具前景的芯片架构」,正从细分走向主流,并成为头部企业争相布局的核心方向。但在中国,这不是未来,而是现实。
高阶超越之路
2025 年深冬,新疆双河市,中树云智算中心拔地而起。这是全疆第一座基于可重构计算架构打造的绿色算力枢纽,首期工程,全部基于清微智能的可重构计算芯片部署、打造。从底层架构到核心 IP,它全链条自主可控,肩负起国家「东数西算」和「算力出海」数字节点的重任。更大的惊喜在于,清微智能刚刚发布的新一代超节点方案,凭借超越 GPU 和 ASIC 集群的高算力和高显存,将成为可重构 AI 计算领域的「大国重器」。

(图)中树云双河智算中心实景
AI 生态上,清微智能深度融入国产「众智 FlagOS」开源生态,并与寒武纪、昆仑芯、摩尔线程、华为昇腾、中科海光携手,作为国内唯六的「FlagOS 卓越适配单位」。此外,清微智能还在全国范围展开「织网」,多个省市的千卡级智算中心相继落地,算力卡订单总量突破 30000 枚。IDC 数据显示,2025 年上半年清微智能的出货量已妥妥进入国内第一梯队。这意味着中国的可重构芯片,已从「技术突破」跃升到「规模落地」的新阶段。即便放眼全球,中国可重构芯片技术的水平,也与国际主流并驾齐驱。
清微智能的下一代芯片,更是瞄准了 3D 可重构架构,力图将 AI 芯片有效带宽提升 10 倍,能效比提升数倍,实现对国际主流高端 AI 芯片的超越。即便面对 Groq、SambaNova,中国人完全可以保持「平视」。
所以,清微智能才会获得国家集成电路产业投资基金(大基金二期)的垂青,而且是「大基金」唯一投资的新架构芯片企业。最新的 C 轮融资中,京能集团、北创投、京国瑞等北京国资巨头更联手入主,成为其未来发展的「压舱石」。至此,清微智能正式跻身自主可控「芯片矩阵」,与摩尔线程、昆仑芯、寒武纪一起,纳入北京 AI 芯片矩阵的「四大金刚」之列。
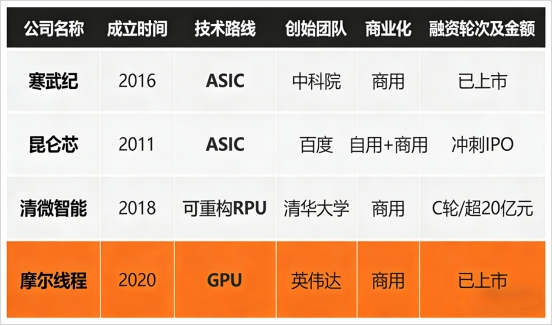
而「四大金刚」,恰好实现对「三大技术流派」的全覆盖。当国家级资本加码与英伟达天价收购一并发生时,实则指明了同一个趋势:AI 芯片将进入非 GPU(ASIC 和可重构)全面参与角逐的新阶段。
行业预测,更是乐观。据 IDC 预测,2028 年中国 AI 加速卡市场中,非 GPU 产品的占比有望从 2025 年上半年的约 30%,提升至接近 50%。
占据半壁江山。这意味着,中国的可重构企业在未来三年不仅迎来估值的全球对标,更会跻身算力主会场,成为决胜未来的关键力量。
来源:互联网


