

如果说 AlphaGo 确立了 AI 的「围棋霸权」,那懂得自己思考的 MuZero,可能会在更多领域确立「霸权」。
Google 母公司 Alphabet 旗下的 DeepMind,在这一个月里大动作频出。
先是在月初推出了蛋白质结构预测 AI——AlphaFold 2,这个 AI 在 CASP 竞赛中拔得头筹,解决了困扰了学界 50 年的难题:生物学家 Andrei Lupas 本人花了十年时间,用尽各种实验方法也没能弄清楚一种蛋白质折叠后的形状,但借助 AlphaFold 2 后,他在半个小时内就得到了答案。
接着,在月底,DeepMind 在《自然》杂志上发布论文介绍「进阶版 AlphaGo」——MuZero。简单来说,MuZero 更「通用」了,它精通国际象棋、围棋、将棋,还能在数十款 Atari 游戏上全面超越过去的 AI 算法和人类。但更具革命意义的是,MuZero 不像它的前辈们,它在下棋和游戏前完全不知道游戏规则,完全是通过自己的试验和摸索,洞悉棋局和游戏的规则,形成自己的决策。换句话说,AI 会自己「动脑子」了。
MuZero 就像是 Netflix 热剧《女王的棋局》里的贝丝·哈蒙,在完全不知国际象棋规则的情况下,凭借几次观察就把棋盘「画」在自己的心里,并通过不断复盘棋局强化自己的直觉,最终所向披靡。
不知道规则,怎么赢棋?
2016 年,AlphaGo 横空出世,以 4:1 击败韩国顶级棋手李世乭,并在 2017 年的乌镇围棋峰会上击败了世界第一棋手柯洁。中国围棋协会甚至当即授予 AlphaGo 职业围棋九段的称号。
AlphaGo 依赖的还是 DeepMind 输入的专家棋法数据集,然后它的继任者 AlphaGo Zero 开始摆脱对「人类数据」的依赖,开始通过多次自我对弈积累所需数据。2018 年底问世的 AlphaZero 更是在前两者的基础上迭代,除了围棋,它还学会了将棋和国际象棋。让人叹为观止的是,从第一次见到棋盘,到成为世界级棋类大师,AlphaZero 只用了 24 小时。
「但你不能像下棋一样,只顾着往前看。你必须学习这个世界如何运作。」DeepMind 的首席研究科学家 David Silver 告诉《连线》,按照这个思路,他们决定不提前告诉 AI 该怎么赢了,「这是我们第一次打造这种系统」。
上面提到的「Alpha」家族,最早需要「人类数据」、「领域知识」和「游戏规则」,至少也还需依赖「游戏规则」。而刚面世的 MuZero 则没有这些知识储备,就像是下棋被蒙着眼,玩游戏背着手。
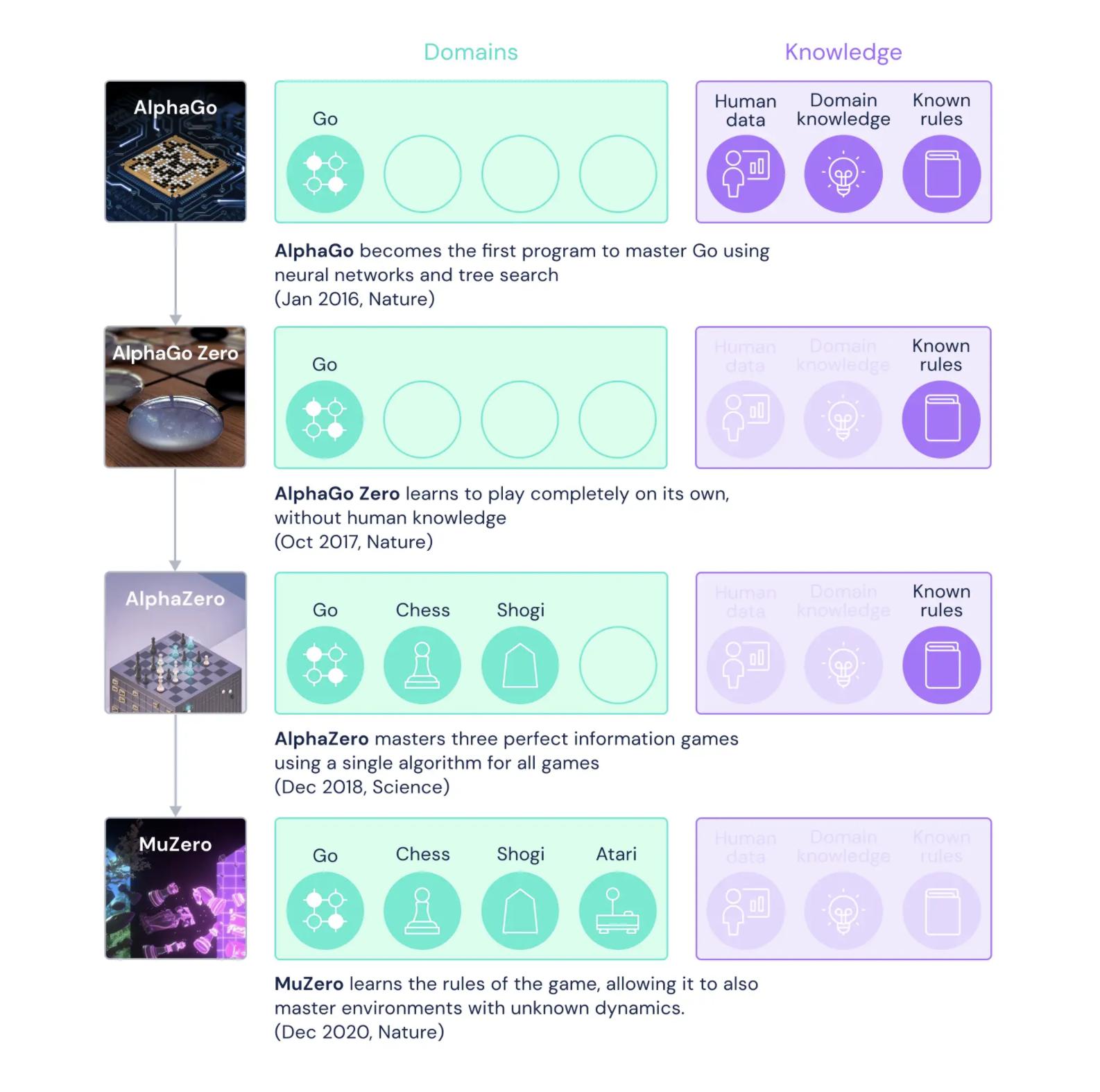
「Alpha」家族至少也还需依赖「游戏规则」,而刚面世的 MuZero 则没有任何知识储备|DeepMind
既然 MuZero 连怎么赢棋都不知道,那它又是如何学习世界运作原理的呢?先以 AlphaZero 为例,由于它已经知晓棋局的规则,所以它知道一个动作后的下一个棋步是什么样的,运用深度学习中的「蒙特卡洛树搜索」(MCTS)就能评估不同的下棋可能性,并从中选出最优的动作。在这个过程中,AlphaZero 只需要利用「预测网络」这一神经网络。
而 MuZero 不知道现有的规则,那么只能从零开始构建一个内部模型,形成自己对棋局的理解。
首先,MuZero 会利用「表征网络」将自己观察到的棋步收集起来,转化为专属于自己的知识;
接着,利用「预测网络」形成策略(即最好的「下一步」是什么),判断价值(即当前决策「有多好」);
最后,借助「动态网络」判断「上一步有多好」,回收此前做出的最佳棋步,不断完善自己的内部模型。
也就是说,MuZero 并没有具体的「行事准则」,它就像是一个小孩,在有了一定思考能力的基础上,正在不断完善自己的行事准则。在此之前,「AlphaGo」虽能轻松击败人类,但也只限于围棋等专精领域,却无法「触类旁通」,每遇到新的游戏都需要更改框架,重新学习。而掌握了「思考方式」的 MuZero 显然能做得更多了,也就是,更通用了。
「知道雨伞能让人不被淋湿,比能对雨滴建模更有用。」DeepMind 用这句话表示,对 AI 来说,它们会的本领看起来越笨,越有实际意义。

在游戏方面,以研究 AI 打扑克出名的 FAIR 研究科学家 Noam Brown 这样评价 MuZero:「当前人们对游戏 AI 的主要批评是模型不能对现实世界中相互作用进行准确建模。MuZero 优雅而令人信服地克服了这个问题(适用于完美信息游戏)。我认为,这是可以与 AlphaGo 和 AlphaZero 相提并论的重大突破!」
这个会思考的 AI,能做什么?
DeepMind 研究表示,MuZero 在不具备任何底层动态知识的情况下,通过结合 MCTS 和学得模型,在各种棋类种的精确规划任务中可以匹敌 AlphaZero,甚至超过了提前得知规则的围棋版 AlphaZero。
在实验中,只要为 MuZero 延长每次行为的时间,它的表现就会变得更好。随着将每次行动的时间从十分之一秒增加到 50 秒,MuZero 的能力会增加 1000 Elo(衡量玩家的相对技能),这基本相当于熟练的业余玩家和最强的职业玩家之间的区别。
开始自我思考的 MuZero 就像人一样。现实世界混沌、复杂,人们也没有具体的行事手册,只能摸着石头过河,慢慢形成自己的规划能力,进而制定下一步该怎么做的策略。
那么,MuZero 能做什么?
《连线》记者提到了在生化界做了件「大实事」的蛋白质结构预测 AI,接着问起了 MuZero 的实用价值。David Silver 表示,MuZero 已经投入实际使用,用于寻找一种新的视频编码方式,从而完成视频压缩。考虑到大量不同的视频格式和众多的压缩模式,能节省 5% 的比特已经是极具挑战的任务。「互联网上的数据大部分是视频,那么如果可以更有效地压缩视频,则可以节省大量资金。」由于 Google 拥有世界上最大的视频共享平台 YouTube,因此他们很可能将 MuZero 其应用到该平台上。

David Silver 对它的造物有足够的自信|WIRED
David Silver 想得更远,「一个真正强大的系统,它能看到所有你看到的东西,它有和你一样的感官,它能够帮助你实现目标。另外一个变革性的,从长远来看,(MuZero 的『强化学习』思路)是可以提供个性化的医疗解决方案的东西。有一些隐私和伦理问题必须解决,但它会有巨大的价值,它会改变医学的面貌和人们的生活质量。」
目前,「Alpha 家族」这种规划算法也已经在物流、化学合成等诸多现实世界领域中产生影响。然而,这些规划算法都依赖于环境的动态变化,如游戏规则或精确的模拟器,导致它们在机器人学、工业控制、智能助理等领域中的应用受到限制。
而不再「循规蹈矩」的 MuZero,先摸索规则、建立内部模型再精通的思路,显然具有更强的可塑性。会自己思考的 AI,离通用 AI 会更近一些。
「我不想给它设定一个时间尺度,但我想说,人类能实现的一切,我最终认为机器都能实现。大脑完成的只是一个计算过程,我不认为那里有什么神奇的东西。」David Silver 对它的造物有足够的自信。
如果说 AlphaGo 确立了 AI 的「围棋霸权」,那懂得自己思考的 MuZero,可能会在更多领域确立「霸权」。
题图:Netflix
责编:于本一
本文首发于极客之选,转载请联系极客君微信 geekparker。


