

强化学习有优势也有局限。
谷歌旗下人工智能公司 DeepMind 发布了一篇新论文,它讲述了团队如何利用 AlphaGo 的机器学习系统,构建了新的项目 AlphaZero。AlphaZero 使用了名为「强化学习」(reinforcement learning)的 AI 技术,它只使用了基本规则,没有人的经验,从零开始训练,横扫了棋类游戏AI。
AlphaZero 首先征服了围棋,又完爆其他棋类游戏:相同条件下,该系统经过 8 个小时的训练,打败了第一个击败人类的 AI——李世石版 AlphaGo;经过 4 个小时的训练,打败了此前最强国际象棋 AI Stockfish,2 个小时打败了最强将棋(又称日本象棋)AI Elmo。连最强围棋 AlphaGo 也未能幸免,训练 34 个小时的 AlphaZero 胜过了训练 72 小时的 AlphaGo Zero。
 图/ AlphaZero 视角下,在比赛中赢,平局或输的局数(来自 DeepMind 团队论文)
图/ AlphaZero 视角下,在比赛中赢,平局或输的局数(来自 DeepMind 团队论文)
强化学习这么强大,它是什么?
知名 AI 博主 Adit Deshpande 来自加利福尼亚大学洛杉矶分校(UCLA),他曾在博客中发表过「深度学习研究评论」系列文章,解读了 AlphaGo 胜利背后的力量。他在文章中介绍到,机器学习领域可以分为三大类:监督学习、无监督学习和强化学习。强化学习可以在不同的情景或者环境下学习采取不同的行动,以此来获得最佳的效果。
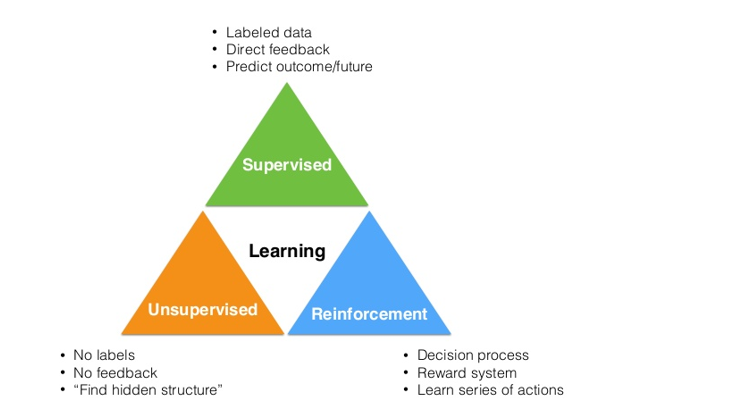 图/Adit Deshpande 的博客《Deep Learning Research Review Week 2: Reinforcement Learning》
图/Adit Deshpande 的博客《Deep Learning Research Review Week 2: Reinforcement Learning》
我们想象一个小房间里的一个小机器人。我们没有编程这个机器人移动或走路或采取任何行动。它只是站在那里。我们希望它移动到房间的一个角落,走到那里会得到奖励分数,每走一步将会损失分数。我们希望机器人尽可能到达指定地点,机器人可以向东、南、西、北四个方向运动。机器人其实很简单,什么样的行为最有价值呢,当然是指定地点。为了获得最大的奖励,我们只能让机器人采用最大化价值的行动。
 图/Adit Deshpande 的博客《Deep Learning Research Review Week 2: Reinforcement Learning》
图/Adit Deshpande 的博客《Deep Learning Research Review Week 2: Reinforcement Learning》
AlphaZero 完爆棋类游戏AI,它的价值有多大?
AlphaGo Zero 是个突破性的进展,AlphaZero 也是吗?国外专家分析,后者在技术上有四点突破:
一、AlphaGo Zero 根据胜率进行优化,只考虑胜、负两种结果;而 AlphaZero 则是根据结果进行优化,考虑到了平局等可能。
二、AlphaGo Zero 会改变棋盘方向进行强化学习,而 AlphaZero 则不会。围棋的棋盘是堆成的,而国际象棋和将棋则不是,因此 AlphaZero 更通用。
三、AlphaGo Zero 会不断选择胜率最好的版本替换,而 AlphaZero 则只更新一个神经网络,减少了训练出不好结果的风险。
四、AlphaGo Zero 中搜索部分的超参数是通过贝叶斯优化得到的,选取会对估计结果产生很大影响。而 AlphaZero 所有对弈都重复使用相同的超参数,因此无需针对游戏进行特定调整。
第四范式资深机器学习架构师涂威威告诉极客公园,AlphaZero 有突破也有局限:
一、DeepMind 这篇论文核心是证明了 AlphaGo Zero 策略在棋类问题上的通用性;在方法上并没有特别亮眼的地方。AlphaZero 其实是 AlphaGo Zero 策略从围棋往其他类似棋类游戏的拓展版,并战胜了基于其他技术的棋类游戏 AI,它们在此之前是最好的。
二、AlphaZero 也只是解决规则明确、完美信息博弈的类似棋类游戏的「通用」引擎,对于更复杂的其他问题,AlphaZero 依然会遇到困难。
此前,旷世科技孙剑解读 AlphaGo Zero 时曾表示,「强化学习就算可以扩展很多别的领域,用到真实世界中也没有那么容易。比如说强化学习可以用来研究新药品,新药品很多内部的结构需要通过搜索,搜索完以后制成药,再到真正怎么去检验这个药有效,这个闭环代价非常昂贵,非常慢,你很难像下围棋这么简单做出来。」
三、AlphaZero 也需要非常多的计算资源才能解决相对更为「简单」的棋类问题,成本非常高。据极客公园了解,DeepMind 在论文中称,他们使用了 5000 个第一代 TPU 生成自对弈棋谱,并用了 64 个第二代 TPU 来训练神经网络。此前有专家向某媒体表示,TPU 虽然性能很惊艳,但是成本也会很高,有某国际风投机构的投资人对此还发过朋友圈,其中的一句话就是:「这么贵的芯片,我也就是看看......」
四、目前的 AlphaZero 在围棋上离「围棋上帝」可能还有距离,赢了人不代表就是上帝,目前的网络结构、训练策略是不是最优的,其实还是值得进一步研究的。
虽然有一定的局限,但其应用场景值得深挖。在让机器学习更为通用的研究方向上,有很多其他研究领域值得关注,比如 AutoML、迁移学习等等。同时,如何进一步以更少的代价(计算代价、领域专家代价)获得更为通用的 AI 引擎,让 AI 在实际应用中产生更大的价值也是非常值得关注的。
滴滴出行就是一个特别的领域,据极客公园了解,滴滴在匹配司机和乘客的过程中,就使用了人工智能技术,从不合理的直线距离匹配(可能隔着河),到指派到乘客处用时最少的车,经历了很多技术优化。他们也遇到了问题,并为之努力:在训练人工智能系统时,可以使用 GPU 集群等技术,但当让司机和乘客匹配时,要求实时性,配置也会降低,因此如何保证准确,也是研究人员一直在探讨的问题。
但涂威威对 DeepMind 在「通用人工智能」方向上的努力表示肯定。
 图 / 北大AI公开课《胡郁:人工智能+,共创新时代》
图 / 北大AI公开课《胡郁:人工智能+,共创新时代》
第四范式首席科学家、国际人工智能协会(IJCAI)主席、香港科技大学计算机系系主任杨强教授曾提到,计算机真正可以思维的「强」人工智能(通用人工智能)其实是想实现「从 0 到 1」的突破,而目前包括工业界和计算机应用学科等领域,其实只是想让计算机的行为表现像智能一样,这可以称为「从1 到 N」。
但是,科学家们一直在不断探索通用人工智能。DeepMind 就是这方面的先行者之一,好像登山一样,只要一步步攀登,有一天人类必然登顶。
责任编辑:双筒猎枪
头图来源:视觉中国


