

本次公开课,我们将邀请到友盟+首席数据架构师&数据委员会会长张金来为大家讲解到底什么是用户画像,快速建模框架,如何提高用户精准画像的的准确性,从理论到应用的一起了解用户画像。
此公开课为极客公园策划的「极客公开课•Live」第十四期。本次公开课,我们将邀请到友盟+首席数据架构师&数据委员会会长张金来为大家讲解到底什么是用户画像,快速建模框架,如何提高用户精准画像的的准确性,从理论到应用的一起了解用户画像。
- 什么是用户画像?
用户画像也叫用户标签, 是基于用户行为分析获得的对用户的一种认知表达,也是后续数据分析加工的起点。从认知心理学的角度,用户标签其实与人认知世界的方式相一致,人为了简化思考,通常也会通过概念化的方式简化事物认知,这种概念认知就是标签。因此,用户画像的内容可以很宽泛,只要是对人的认知,都可以叫做用户画像。例如:今天路过这个门口三次的人,也可以是一个标签,只要他有合适的应用场景。
另外,我们需要从概念上加以区分,用户标签和用户透视,一个是个体的认知,一个是整体的标签分布,二者都经常被人统称为用户画像。今天我们在这里说的用户画像主要指标签。
- 用户画像的 4 个核心价值
一、市场细分和用户分群:市场营销领域的重要环节。比如在新品发布时,定位目标用户,切分市场。这是营销研究公司会经常用的方式。
二、数据化运营和用户分析。后台 PV\UV\留存等数据,如果能够结合用户画像一起分析就会清晰很多,揭示数据趋势背后的秘密。
三、精准营销和定向投放。比如某产品新款上市,目标受众是白领女性,在广告投放前,就需要找到符合这一条件的用户,进行定向广告投放。
四、各种数据应用:例如推荐系统、预测系统。我们认为:未来所有应用一定是个性化的,所有服务都是千人千面的。而个性化的服务,都需要基于对用户的理解,前提就需要获得用户画像。
- 用户画像的基础:数据
做好用户画像需要一定的门槛,一方面是数据的体量和丰富程度,另一方面是技术和算法能力。今天介绍的经验基础是【友盟+】数据,首先简单介绍一下。【友盟+】有覆盖线上线下的实时更新的全域数据资源,每天大约有 14 亿的设备,覆盖数百万级的网站和 APP 行为,这个庞大的数据量使得我们有丰富的数据资源来生产用户画像,同时又要求我们能相应的技术能力来进行处理。
- 数据是如何生产,变成画像的?
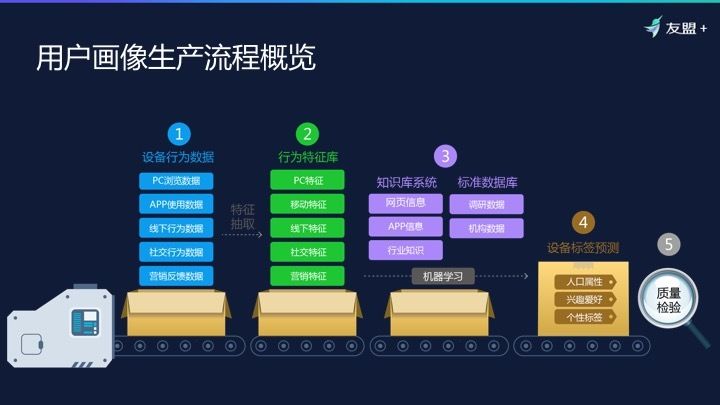
结合上图,用户画像生产流程概览,我们将用户画像的生产比喻成一个流水线,就如同将矿石加工成成品的过程。用户浏览网页、使用 APP、线下行为,这些数据都是矿石,需要提炼、加工成为产品,最后还要通过质检。
这个过程通常有几个步骤。首先获得原始行为数据,基于这些数据做特征抽取,相当于清洗、加工的工作;在机器学习环节,会与外部知识库有一些交互。实际上机器算法对人的理解,一定要基于知识体系,就好像我们说的概念。比如,机器给人打汽车相关的标签,一定要首先知道汽车体系有什么样的分类,有什么车型,有这样的知识系统我们才能把人做很好的标识归类。
最后,质量检测,这一步也很重要。一个标签的质量决定了后期的应用效果,如果前期对人的分析偏了,后期结果就很难做对。
- 用户画像生产流程框架
上面讲的是概念图,如果具象到实际操作中,是这样一个框架流程:
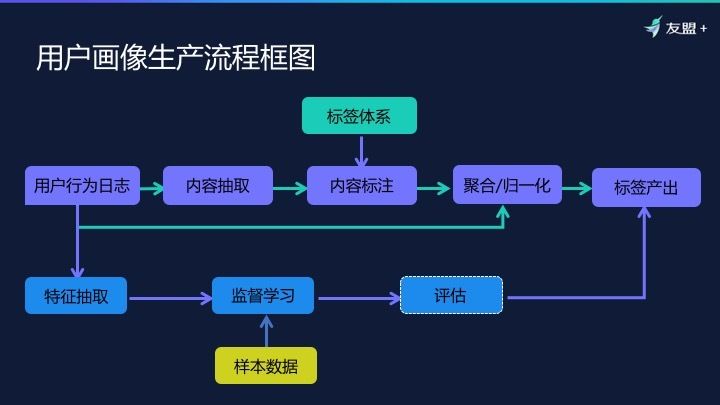
这里先留三个悬念:
悬念一:从用户行为日志开始到标签产出,为什么有两条线?
悬念二:标签体系为什么只作用在内容标注上?
悬念三:为什么下面的「评估」过程要特别标注出来?
1、从用户行为日志开始到标签产出,为什么有两条线?我们把画像分为两大类:第一类:统计型画像;第二类:预测性画像。
第一类,统计型画像是客观存在,这种都是兴趣偏好。比如,用户每天都在看汽车新闻、搜索汽车相关的内容,基于这种行为,我们判断这个用户对汽车感兴趣。这些行为是客观发生的,因此无所谓正确率,也不需要训练样本集。
第二类,预测性画像。需要通过用户行为做预测,像用户的性别预测,尤其是挖掘人的内心态度。比如,用户在消费时,是激进的,还是保守的?有预测就有准确率。所以这里面有很重要的评估指标,就是正确率,也需要取样本集。这就是二者的不同,也会有不同的加工流程。
- 常用的一些标签体系
再继续介绍标签体系,因为很多同学会问到,「我应该建一个什么样的标签体系?什么样的标签体系是比较好的?」通常我们会把它分为四大类:
第一类:人口属性。比如说性别、年龄、常驻地、籍贯,甚至是身高、血型,这些东西叫做人口属性。
第二类:社会属性。因为我们每个人在社会里都不是一个单独的个体,一定有关联关系的,如婚恋状态、受教育程度、资产情况、收入情况、职业,我们把这些叫做社会属性。
第三类,兴趣偏好。摄影、运动、吃货、爱美、服饰、旅游、教育等,这部分是最常见的,也是最庞大的,难以一一列举完。
第四类,意识认知。消费心理、消费动机、价值观、生活态度、个性等,是内在的和最难获取的。举个例子,消费心理/动机。用户购物是为了炫耀,还是追求品质,还是为了安全感,这些都是不一样的。
- 如何判断标签体系的好坏?
在实际构建标签体系时,大家经常会遇到很多困惑,我列举 5 个常见问题。
第一、怎样的标签体系才是正确的?其实每种体系各有千秋,要结合实际应用去评估。
第二、标签体系需要很丰富么?标签是枚举不完的,可以横线延展、向下细分。也可以交叉分析,多维分析。如果没有自动化的方式去挖掘,是很难做分析的,太多的标签反而会带来使用上的障碍。
第三、标签体系需要保持稳定么?不是完全必要,标签体系就是产品/应用的一部分,要适应产品的发展,与时俱进。比如,以前没有共享经济这个词,今天却很热。我们是不是要增加一个标签,分析哪些人对共享经济的参与度高?喜欢共享单车、共享汽车。
但是,有一种情况下,标签要保持稳定。如果你生产的标签有下游模型训练的依赖,即我们模型建完后,它的输入是要保持稳定的,不能今天是 ABC,明天是 BCD。在这种情况下,是不能轻易对标签体系做更改的。
第四个,树状结构 or 网状结构?树状结构和网状结构从名字上就可以看出其分别。网状结构,更符合现实,但是层次关系很复杂,对数据的管理和存储都有更高要求。知乎,如果仔细去看它的话题设置,其实是网状的。
网状的特点就是一个子话题,父级可以不止一个,可能有两个。比如儿童玩具,既可以是母婴下分分类,也可以是玩具下的分类,它就会存在两个父节点之下。树状结构相对简单,也是我们最常用的。网状结构在一些特定场景下,我们也会去用。但是实现和维护的成本都比较高。比如,有一个节点是第四级的,但它的两个父节点一个是二级,一个是三级,结构异化带来处理上的麻烦。
第五个,何为一个好的标签体系?应用为王,不忘初心。标签是为了用的,并不是为了好玩,最好保证标签体系的灵活和细致性。
- 统计型标签的生产流程
再回到刚才说的生产流程上。我先结合下面的图介绍上半边,统计型的标签是怎么去加工的。
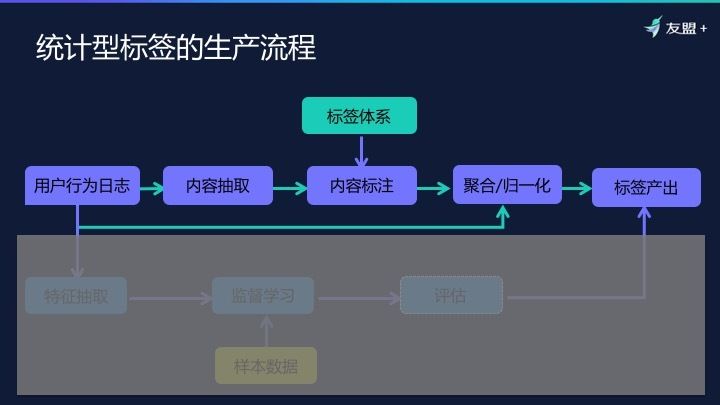
首先我们要有行为数据,例如用户每天看 100 篇文章,有 40 篇是体育的,有 30 篇是汽车的,有 20 篇是旅游的,还有 10 篇其他的。我推测,你比较喜欢体育、汽车、旅游。
对于这样的标签,大概需要什么流程去做呢?环节一很重要,内容标注。只有知道用户看的内容是什么,才能统计偏好。环节二,如何基于用户行为做聚合统计和归一化。
- 一个经典的标注例子:网页标注
在做内容标注时,一般会有两种情况:第一种:有些公司在建自有用户画像时会很幸运,例如电商、视频类、音乐类的媒体,它给用户服务的这些内容是已经分类好的。可以直接用内容的标注来做用户行为标注。

但是,对于一些通用型的内容,比如【友盟+】的数据,会有 PC 浏览数据、APP 的使用数据,一定要先了解用户喜欢看什么,才能去做下一步的工作。在这里面,最复杂,也最典型的就是网页的内容标注。
- 标签的最终生成:行为统计

根据用户的行为,统计标签数值,归一化。比如,我们判断用户是喜欢运动、还是服饰,会将他看来多少相关网页、使用了多少 APP 进行累加,在除以一个总累积,得到一个标签得分。
这里面有几个点需要关注:
第一、统计量的选取。可能是浏览数量、浏览时长、浏览频度、复合关系等。举个复合关系的例子,对于某个商品类目的偏好,你可以将浏览、搜索、收藏,购买等行为统计量加权在一起考虑。
第二、个体内的可比性。个体用户的不同标签间具有可比性。举个例子,我有两个标签:阅读、旅游。我的阅读标签是 0.8 分,旅游是 0.6 分,代表我更倾向于去阅读,而不是去旅游?如何保证这一点呢?在上面公式里将个体的行为总和作为分母就可以了。
第三、垂类内的可比性。一个垂类内不同用户的相同标签具有可比性。
例如,我的动漫得分是 0.8,你的是 0.6,表示我比你要更喜欢动漫。那么分母就是选取整个动漫类行为的总和。比如说,今天全国用户在 B 站上一共 100 万小时,你有 1 个小时,你是百万分之一,他花了 2 个小时,大约是百万分之二,最后再做一个归一化,就会产生一个类内可比的得分。
我们刚刚说的是绝对化的值,还有一个简单的做法就是做排序,基于用户的使用时间做排序,这样也可以。
但是排序和归一化到底有什么不同?排序只代表相对性,而刚才说归一化代表了强弱, 我的得分是 0.8 和你是 0.6,就表示偏好强度上我比你高了 30%,而排序则不能反映这样的比例。
11、统计型标签生产要点回顾
1、行为数据。浏览、使用、点击、购买、LBS 等,通过行为数据反映人的偏好倾向;
2、标签体系。根据实际需要进行设定。可以参考《消费者行为学》、电商类目体系、应用市场体系、媒体资讯体系等;
3、内容标注。把行为相关的内容抽出来做分析,把标签体系先打到它们身上,再累积到「人」身上;
4、得分归一化。明确归一化的目标,选择所需的归一化方法。举个例子,推荐适合用个体内可比较的得分,不管 A 看会某个内容用了多少时间,A 所看到最多的内容就优先推荐给 A,不用和其他人比较;
但在投放广告上,就要考虑用户在这个商品上的倾向度有多高,需要用户间可比较的得分。
- 预测型标签的生产流程
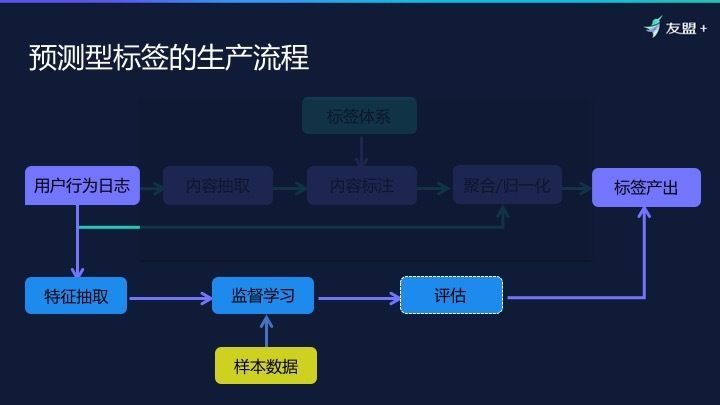
预测性标签的生产流程:特征抽取→监督学习、样本数据→评估→标签产出,这也是经典的机器学习流程。
- 特征工程
特征工程,是机器学习的关键过程之一。最重要的是提取不同侧面的特征。我们以移动端使用行为可抽取的部分特征为例:
1、APP 使用事实特征:用户 30 天内开启 APP 的天数、用户 180 天内开启 APP 的天数。这两个数据都会作为特征,考虑用户短期和长期的情况。
用户 30 天内使用 APP 时长占比、用户 180 天内使用 APP 时长占比。刚才说的是次数,这块是时长,用户可能反复打开,但是总时长很短。
2、兴趣特征:虽然信息有损失,但是泛化效果更好。举个例子,你是 A 站用户,他是 B 站用户,理论上讲,如果我们用最底层的数据,你们两个人是不太一样的,但某种程度上,他们都是对二次元感兴趣的人;
近期用户兴趣标签归一化值、长期用户兴趣标签归一化值。用户长短期基于兴趣标签下使用不同 APP 的熵值、历史某类 APP 时间消耗占比变动比例。其实反映了我们要看这个分布,以及分布的趋势性,你过去关注度高,现在关注度减弱,和你过去关注度不高,现在关注度高,其实这两个是完全对应不同的人,这也是我们参考的特征。
3、设备与环境特征:近期使用的设备品牌、近期使用的设备型号;工作日时间段内 Wi-Fi 使用时间分布、休息日时间段内 Wi-Fi 使用时间分布(工作日与假日的区分)。
- 模型训练与结果评估
1、模型选择。有有监督的分类算法:逻辑回归、SVM、决策树、Bagging、深度学习;
2、二分类 or 多分类。二分类比较简单,多分类则有不同的拆分策略。举个例子,把人分为男女,是二分类的问题;分为年龄段,就是多分类的问题,我们在机器学习当中也有不同的做法,OvO(一对一)、OvR(一对其他)、MvM(多对多)。
3、结果评估。评估指标包括:正确率、召回率、应用效果。但是对于统计型标签来说无正确率,召回率看阈值,今天你只看一个汽车的型号,理论上我也可以给你打一个标签,但是分值非常低,这个分值到底要不要算做这个标签的人,要看中选什么样强度的人。预测型标签,一般看 Precision,Recall,F-Score,ROC。
4、Ranking 任务。一类特殊的定制化标签。针对特定场景,如对电话营销需要按照可能性排序打电话。套用上述模型,可以用最终得分来做 Ranking。
15、关于标签评估的延展
标签的生产不是目的,使用才是。正确率≠效果,举个例子:喜欢看车不代表是试驾购车的目前人群。
第一,用户分层的评估。针对于重点人群进行评估,不同人群分层进行评估;第二,从全局进行评估。不要只局限于样本集合的评估,参看一些全局统计数据。例如,人口属性的分布和统计局的结果是否相符?第三,有效果反馈的应用。将标签直接应用于使用场景中检验效果。例如,进行营销的定向投放,测试点击率;第四,利用其它数据佐证。使用其他行为数据来验证标签的有效性。例如,在电商环境中后续的行为差异来评估显著性。
- 一个快速建模框架
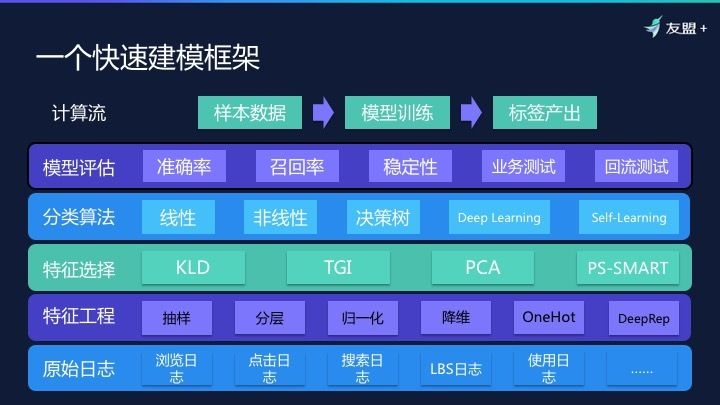
我们今天不再强调标签丰富度,而是快速建模的能力。快速建模怎么做到?这套系统在【友盟+】比较完备,使得我们收到一个样本就可以很快训练模型,这个流程最快 3 个小时就能够把标签算出来。
- 用户画像的应用
Data -> Insight -> Action->Data->…
第一步,先有数据,就像标签生产出来,要有数据的过程;第二步,分析,洞察。洞察并不是最终目的,因为洞察只是得到一个结论或者方向;第三步,开始应用;应用后又带来新的数据,从而形成数据的闭环。举个例子,广告怎样的群体点击了,数据被反馈回来,下一个循环可以进行调整,不断地迭代,优化整个效果。
DIP营销服务流程
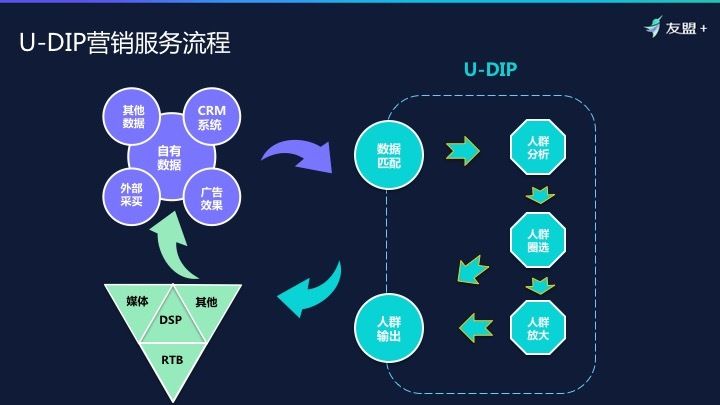
关于上述流程的实际使用,结合【友盟+】DIP 数据智能平台讲一下营销服务流程是如何做的。
左上面是我们一些数据,例如:客户上传数据后,我们会有一个匹配的过程,把所有数据打通连接。上传、匹配之后,会对这些数据做人群分析。比如说宝马 X1 今年刚上市,他们把去年购买 X1 的用户都上传上来,我们会分析这样的用户在哪些方面是有特性的,比如年龄段、地域分布、收入、偏好。有了这样的分析后,我们可以选择相应的人群,基于历史的偏好、特征,然后再去投放;如果中间我们会发现人群量不够,最初选择 10 万人可以放大到 100 万人。最后输出到媒体、RTB 等渠道商。做预算,看效果,将效果数据回流,再去迭代,以进一步提高投放的精准率。这是我们常用的一个流程。
在举个实际的例子,如果要做一个新产品的传播推广,这时需要做定向投放。我们先要对潜在用户要进行分析,例如对于科技产品非常感兴趣的人,我们发现他每天 8、9 点特别活跃,通过进一步分析,他会和哪些媒体做触达,或者他看不看电视会不会留意到地铁里面的广告,这也是一个触达渠道,以及看什么样类型的,看资讯、社交、八卦,这个不太一样。要找到受众,应该到哪找?比如说去这种有态度的网易新闻,还是个性化的今日头条,或者说腾讯新闻,这都需要进行分析。
基于上面的分析之后,再做结合分析。举个例子,你对科技感兴趣,那你的手机是不是到了更新期,你手机大概用了三年,应该到了更新期,就可以对这样的特定人进行投放。把人圈出来,投放、曝光,曝光之后我们去看营销的结果,然后返回来继续分析,会不会对其他内容感兴趣,再去做下一轮分析。
这就是我们之前做的一系列方法的一个应用。
最后关于数据应用我再给出一些通用型的建议:
第一、分析:
1、结合业务场景去选择分析维度:如果你是给中年妇女推荐保健品,你去分析她们喜欢不喜欢二次元,这就非常说不通了。
2、不要只是简单的看画像分布,一定要做对比。

3、例如,与大盘对比情况:TGI。上图是我们分析一个 APP 内的购买人群。紫色的线是人群的分布,年龄段的分布。我们看到 18-30 岁之间的人很多,感觉还不错。但是,如果你做一下大盘情况,APP 的用户大多是年轻人,因为本身这个产品有一个年龄偏小的分布特征。通过分析对比之后发现,TGI 比较高是 30-39 岁的人,这个范围的人才是在购买人群里面是显著的,这个群人才是你去做运营活动、投放的人群。
分析,一定要去做对比,单纯看分布是并没有太多信息含量。不对比看不出来差异。
4、环节的对比。哪些人我触达了,哪些人到这里落地了,哪些人注册了、哪些人真正浏览、哪些是留存、哪些是付费,每一个环节你都可以做这样的分析。
第二、精准投放(Action)。这是我们今天做标签非常大的一类应用。这时候大家可能会发现,我们做品牌广告、效果广告是不同的,举个例子,品牌广告我们就会关心 TA 浓度,关注我投放广告的人性别怎么样、年龄分布怎么样。效果广告是不一样的,效果广告通常很直接,你这个人是不是点了,最终 CTR 高不高,最终购买 ROI 高不高,这种一定是你最直接的兴趣是什么,你什么性别不重要,我就想知道你要不要。
另外一点,直觉未必靠谱,一定要通过反馈来检测,就是刚才说我们为什么要数据闭环,比如说,有一个商品设计者说,我这个产品目标是吸引白领女性,实际上他上市场去卖的时候发现,买他的男性大学生最多,跟他想的根本不一样。
如果你一直持续的给白领女性做广告投放,实际上效果可能不是最优的,反而你做校园活动会达到更好的效果。
甚至说,你可以基于你的用户场景做专属标签,以及你可以通过人群放大来做处理。举个例子说,我今天有新的车型上市,一个方法是,先选取对汽车感兴趣的人,或者 SUV 感兴趣的人,就可以去做投放,这个效果就可能不是最优的,更优的情况是针对你这个 case,去针对性的做训练,针对性的选取跟你相关的人,通常效果上比通用的标签选取更好,这时候我建议如果你特别强调你的效果,就去试试训练专属的标签。
更多详细讲解,请见知乎 Live
以上就是本次公开课的关键内容,更多演示请点击「极客公开课•Live」第十四期或扫描下方二维码查看获取:



